Clear Sky Science · nl
Een multimodale benadering om nepnieuws en invloedrijke knooppunten in de verspreiding ervan te herkennen met deep learning en netwerkanalyse
Waarom dit van belang is voor het dagelijks leven
Elke dag scrollen miljoenen mensen door sociale media en zien berichten over gezondheid, politiek, geld en meer. Tussen nuttige informatie zitten geruchten en nepnieuws die angst, verwarring of zelfs schade in de echte wereld kunnen veroorzaken. Deze studie introduceert een krachtige methode om twee dingen tegelijk te doen: ten eerste automatisch valse of misleidende berichten herkennen, en ten tweede in kaart brengen wie het meest verantwoordelijk is voor hun verspreiding binnen een online gemeenschap. Het werk richt zich op Twitter-berichten over Covid-19, maar de ideeën kunnen platforms, journalisten en het publiek helpen sneller en preciezer te reageren op schadelijke desinformatie op veel terreinen van het leven.
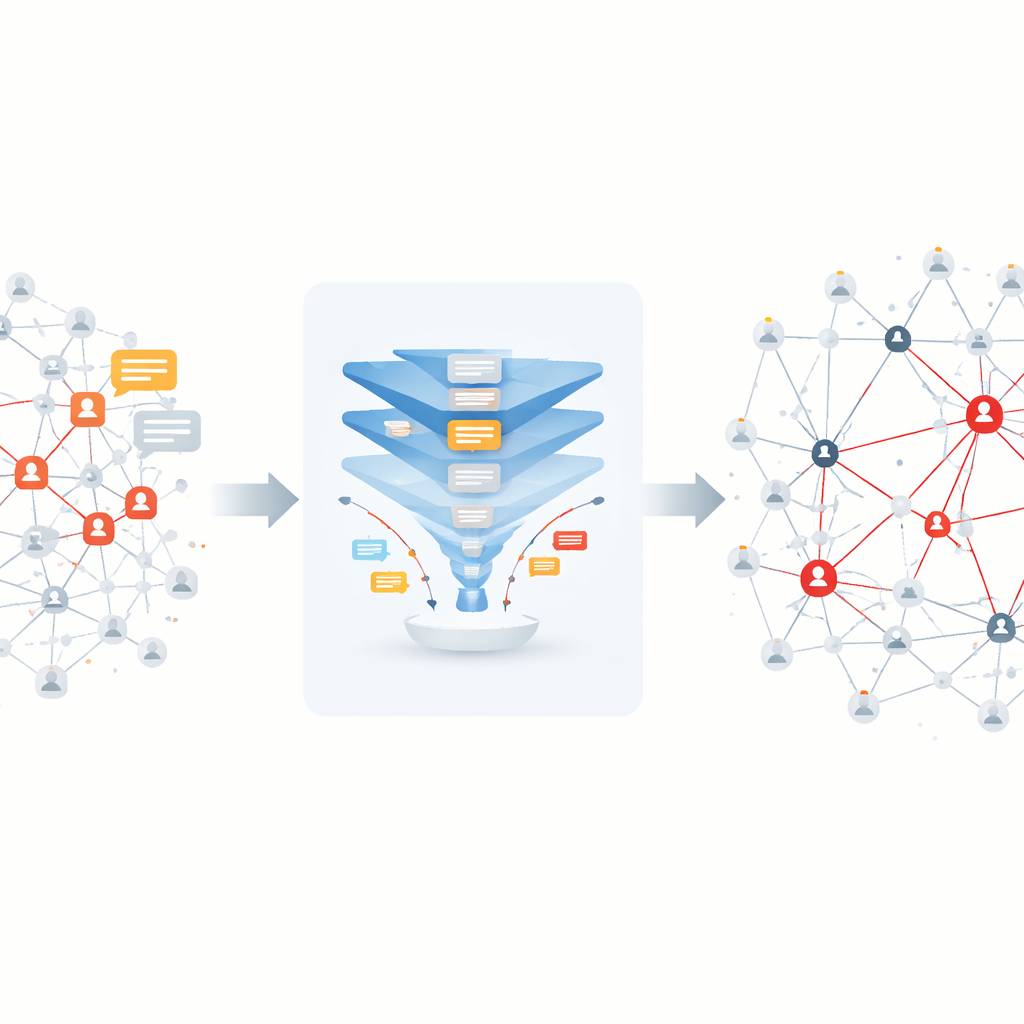
Hoe geruchten door online gemeenschappen rimpelen
Sociale netwerken zoals Twitter, Facebook of berichtendiensten zijn te zien als enorme webben van mensen (knooppunten) verbonden door hun interacties (links). Wanneer een gebruiker een bericht plaatst en anderen reageren of het delen, kan die informatie snel door het web rimpelen. Geruchten — onbevestigde of valse beweringen — gedragen zich veelal als besmettelijke ziekten: ze kunnen van persoon tot persoon springen, snel groeien en moeilijk te stoppen zijn. Eerder onderzoek behandelde vaak twee vragen los van elkaar: hoe vast te stellen of een bepaald bericht een gerucht is, en hoe de belangrijkste “verspreiders” te vinden die dat gerucht bij veel anderen brengen. De auteurs bepleiten dat het aanpakken van beide vragen tegelijk, met aandacht voor hoe het netwerk is opgebouwd en hoe activiteit in de tijd verandert, een veel helderder beeld geeft van hoe valse verhalen zich verplaatsen.
Een computer leren twijfelachtige berichten te lezen en te markeren
Het eerste deel van de methode richt zich op de inhoud van elke tweet. De onderzoekers behandelen elke tweet als een kort document en schonen die op door rommel te verwijderen, zoals extra symbolen, weblinks en e-mailadressen te vervangen door eenvoudige tags, en veelvoorkomende stopwoorden eruit te halen die weinig betekenis toevoegen. Vervolgens zetten ze elk woord om in een numerieke vector met een veelgebruikte techniek genaamd GloVe, die vastlegt hoe woorden doorgaans samen voorkomen in grote tekstverzamelingen. Door deze woordvectoren te middelen wordt elke tweet een compacte numerieke samenvatting van zijn betekenis. Deze samenvattingen worden vervolgens ingevoerd in een eendimensionaal convolutioneel neuraal netwerk — een type deep learning-model dat subtiele patronen kan detecteren — om te bepalen of een tweet een echt bericht is of een gerucht.
De sleutelverspreiders binnen het netwerk vinden
Nadat het systeem geruchten van echte tweets heeft gescheiden, richt het tweede deel van de aanpak zich op de structuur van het sociale netwerk zelf. Elke gebruiker is een punt in een gerichte, gewogen graaf, en elke reply of retweet wordt een link waarvan de sterkte weerspiegelt hoe vaak de een op de ander reageert. Met deze informatie clusteren de auteurs eerst gebruikers in gemeenschappen — groepen die meer met elkaar dan met buitenstaanders interacteren — door een speciale boomrepresentatie van het netwerk te bouwen en vervolgens nauw verbonden subgroepen samen te voegen op basis van hoe goed ze bij elkaar passen. Binnen deze gemeenschappen berekenen ze hoe vaak elke gebruiker op de belangrijkste paden tussen anderen ligt, een maat bekend als betweenness. Gebruikers die keer op keer op paden met hoge waarde verschijnen worden gezien als invloedrijke verspreiders. De gewichten van verbindingen worden daarna bijgewerkt om zowel de frequentie van interacties als de centraliteit van de verbonden gebruikers te weerspiegelen, waardoor de meest waarschijnlijke routes die geruchten in de loop van de tijd door het netwerk nemen zichtbaar worden.
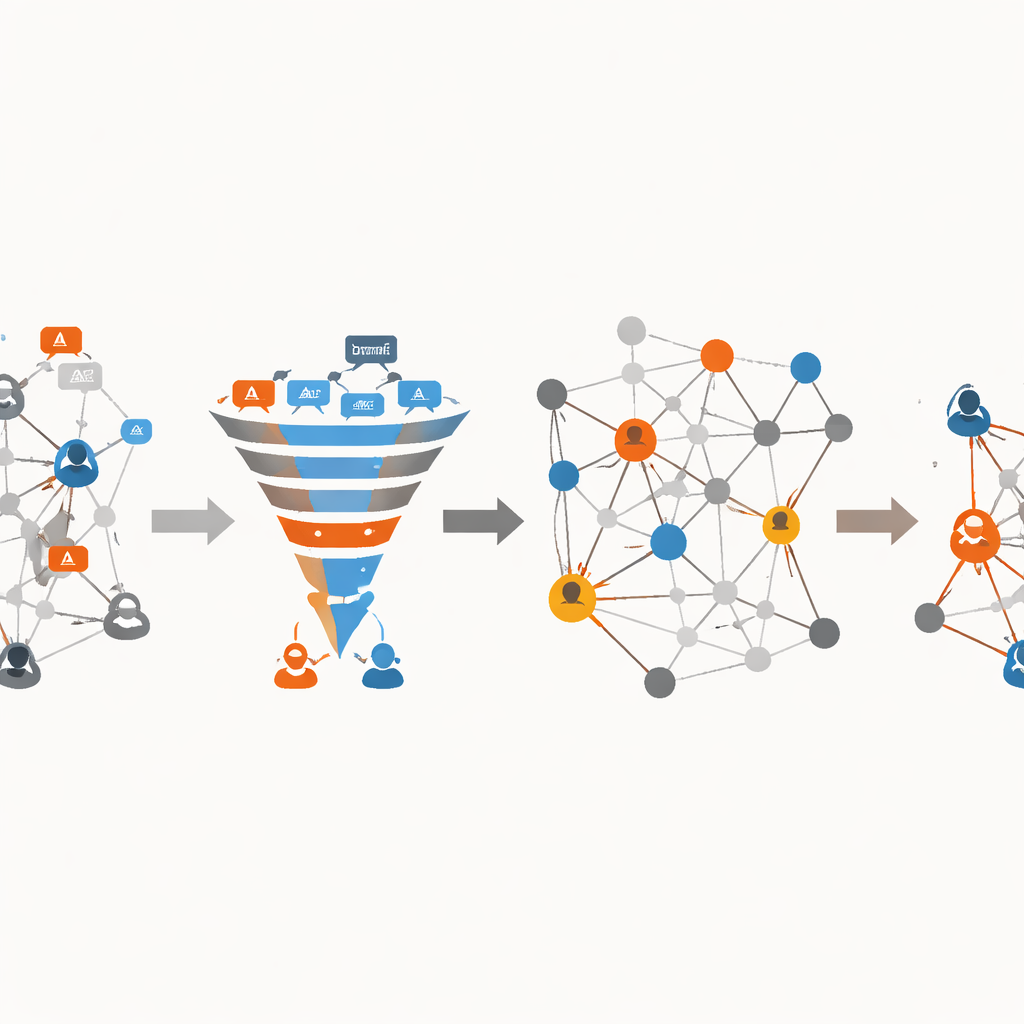
Wat de Covid-19 casestudy aantoonde
Om hun raamwerk te testen pasten de onderzoekers het toe op een omvangrijke Twitter-dataset over Covid-19: bijna 100 miljoen tweets met meer dan 150.000 gebruikers, waaruit ze meer dan 14.000 unieke berichten extraheerden die waren gelabeld als authentieke informatie of geruchten. Op deze data classificeerde hun deep learning-model ongeveer 99 procent van de tweets correct, en overtrof daarmee meerdere bestaande methoden, inclusief andere geavanceerde nepnieuwsdetectoren. In de tweede fase vergeleken ze hun lijst met invloedrijke gebruikers met een bekend wiskundig model van hoe informatie zich verspreidt en vonden de hoogste overeenstemming tussen de geteste methoden. Ze toonden ook aan dat bij analyse over langere perioden — 120, 240 en vervolgens 360 dagen — het model beter werd in het aanwijzen van kernverspreiders en belangrijkste geruchtenroutes, en dat het dat deed met lagere verwerkingstijd dan concurrerende netwerkgebaseerde technieken.
Wat dit betekent voor het bestrijden van desinformatie
Kort gezegd laat de studie zien dat het mogelijk is een systeem te bouwen dat niet alleen met zeer hoge nauwkeurigheid waarschijnlijk nepnieuws signaleert, maar ook volgt hoe het zich verplaatst en wie het meest verantwoordelijk is voor de verspreiding. In plaats van alle gebruikers en verbindingen gelijk te behandelen, benadrukt de methode een kleinere set gemeenschappen en individuen wiens gedrag het meest van belang is om schadelijke verhalen te beheersen. Hoewel het werk is uitgevoerd op geanonimiseerde Twitter-data over Covid-19 en mogelijk niet direct generaliseert naar elk platform of onderwerp, wijst het op een weg naar meer gerichte, datagedreven reacties op online geruchten — bijvoorbeeld door factchecking, waarschuwingen of platforminterventies te richten waar ze de grootste impact kunnen hebben, met respect voor individuele privacy en ethisch gebruik.
Bronvermelding: Zhang, W., Qian, M. & Zhang, Q. A multi-modal approach for recognizing fake news and influential nodes in spreading them using deep learning and network analysis. Sci Rep 16, 9775 (2026). https://doi.org/10.1038/s41598-026-35342-7
Trefwoorden: nepnieuws, sociale netwerken, geruchtenverspreiding, deep learning, invloedrijke gebruikers