Clear Sky Science · nl
Kennisintegratie voor fysica-geïnformeerde symbolische regressie met voorgetrainde grote taalmodellen
Computers leren de formules van de natuur raden
Veel grote ideeën in de wetenschap worden samengevat in keurig uitgewerkte vergelijkingen: van hoe een bal valt tot hoe lichtgolven door de ruimte rimpelen. Dit artikel onderzoekt een nieuwe manier om computers automatisch zulke vergelijkingen uit ruwe data te laten herontdekken, door ze een groot taalmodel te laten raadplegen—hetzelfde type AI dat moderne chatbots aandrijft—zodat hun gissingen niet alleen nauwkeurig zijn, maar ook fysisch zinvol.
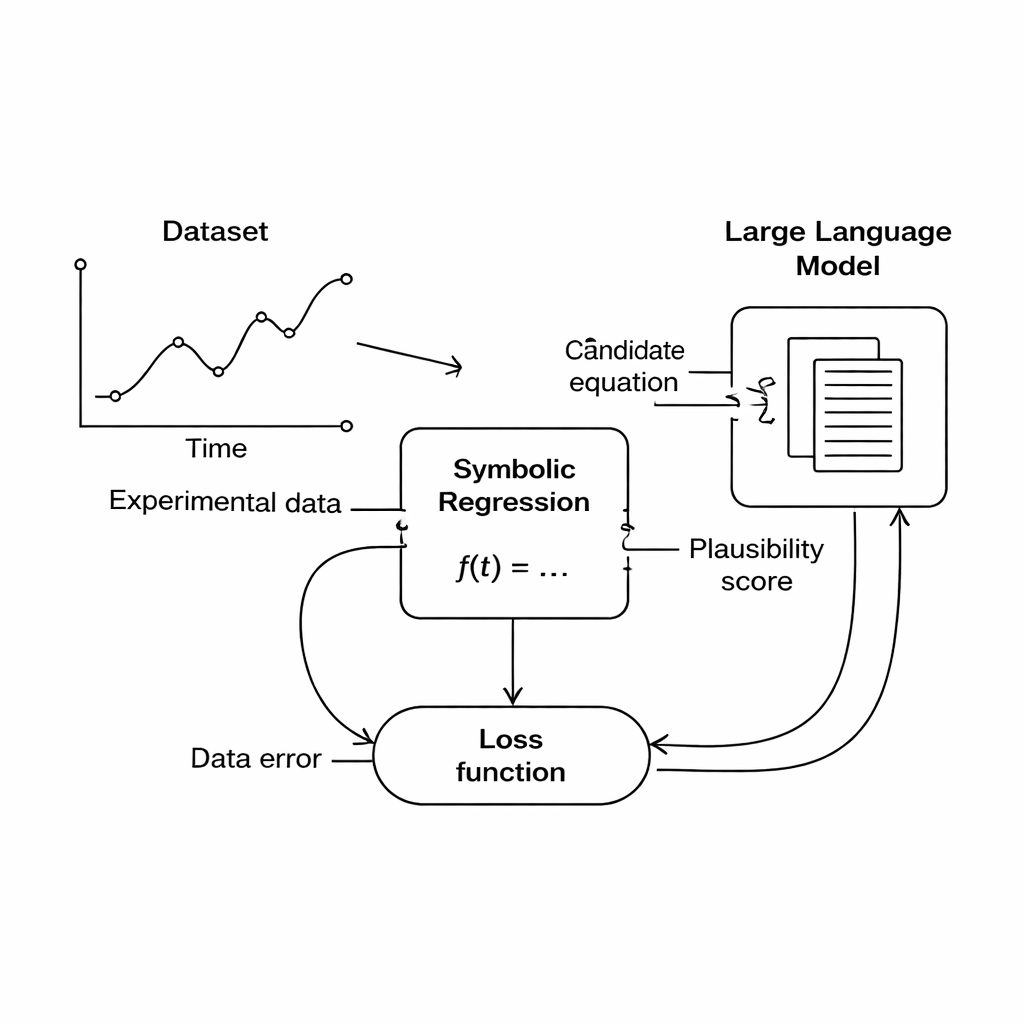
Van ruwe data naar leesbare natuurwetten
De auteurs richten zich op een techniek die symbolische regressie heet, waarmee gezocht wordt naar een wiskundige formule die gemeten invoer en uitvoer met elkaar verbindt. In tegenstelling tot gewoon curvefitting begint symbolische regressie niet met een vaste vorm van de formule; in plaats daarvan bouwt en ontwikkelt het kandidaatvergelijkingen totdat er één goed bij de data past. Daardoor is het een veelbelovend instrument voor wetenschappelijke ontdekking, omdat het mogelijk nieuwe relaties kan onthullen die nog nergens zijn opgeschreven. Er zit echter een addertje onder het gras: een formule die perfect bij de data past kan fysisch gezien nog steeds onzin zijn—bijvoorbeeld door afstand bij tijd op te tellen of eenheden te produceren die niet overeenkomen met een echte grootheid.
Waarom fysisch inzicht nog steeds telt
Om dergelijke onzin te vermijden, hebben onderzoekers "fysica-geïnformeerde" versies van symbolische regressie ontwikkeld die bekende natuurwetten in de zoektocht verwerken. Deze methoden belonen vergelijkingen die bijvoorbeeld energie behouden of dimensionele consistentie respecteren. Het coderen van deze kennis vereiste echter doorgaans dat experts beperkingen en speciale verliesfuncties per nieuw probleem met de hand ontwierpen. Dat maakt de aanpak krachtig maar moeilijk te generaliseren. Elk nieuw fysisch systeem kan eigen zorgvuldige ontwerpinspanningen nodig hebben, wat de toegankelijkheid van deze hulpmiddelen voor niet-experts beperkt.
Het taalmodel de vergelijkingen laten beoordelen
Deze studie stelt een andere route voor: in plaats van domeinregels hard te coderen, gebruik een groot taalmodel (LLM) als flexibele beoordelaar van wetenschappelijke plausibiliteit. Tijdens de zoektocht produceert de symbolische regressiemotor kandidaatvergelijkingen die in bepaalde mate bij de data passen. Elke vergelijking wordt vervolgens naar tekst vertaald en samen met een korte prompt die de betrokken grootheden en eventuele bekende fysische beperkingen beschrijft naar het LLM gestuurd. Het LLM geeft scores terug voor drie aspecten: of de eenheden van de vergelijking zinvol zijn, hoe eenvoudig deze is, en of deze fysisch realistisch lijkt. Deze scores worden in de hoofddoelfunctie opgenomen, zodat de computer nu "past bij de data" afweegt tegen "ziet eruit als goede natuurkunde" bij het kiezen van welke vergelijkingen verder te verbeteren.
De methode op de proef gesteld
Om te onderzoeken hoe goed dit werkt, voerden de auteurs uitgebreide computertests uit op drie klassieke problemen: de vrije val van een bal in het aardse zwaarteveld, de eenvoudige harmonische beweging van een massa aan een veer, en een gedempte elektromagnetische golf. Voor elk systeem simuleerden ze duizenden ruisende metingen onder gevarieerde omstandigheden en vroegen ze drie populaire symbolische regressieprogramma’s de onderliggende vergelijkingen terug te vinden, met of zonder hulp van een LLM. Ze proefden drie compacte, open-source taalmodellen—Mistral, Llama 2 en Falcon—en onderzochten hoe verschillende promptontwerpen, van minimaal context tot volledige beschrijvingen en zelfs de echte formule, de begeleiding van het LLM veranderden. In de meeste instellingen verbeterde het toevoegen van de LLM-score hoe nauwkeurig de teruggevonden vergelijkingen overeenkwamen met de bekende wetten en maakte het ze robuuster tegen ruis, waarbij de combinatie van PySR (een bibliotheek voor symbolische regressie) en Mistral over het algemeen het beste presteerde.
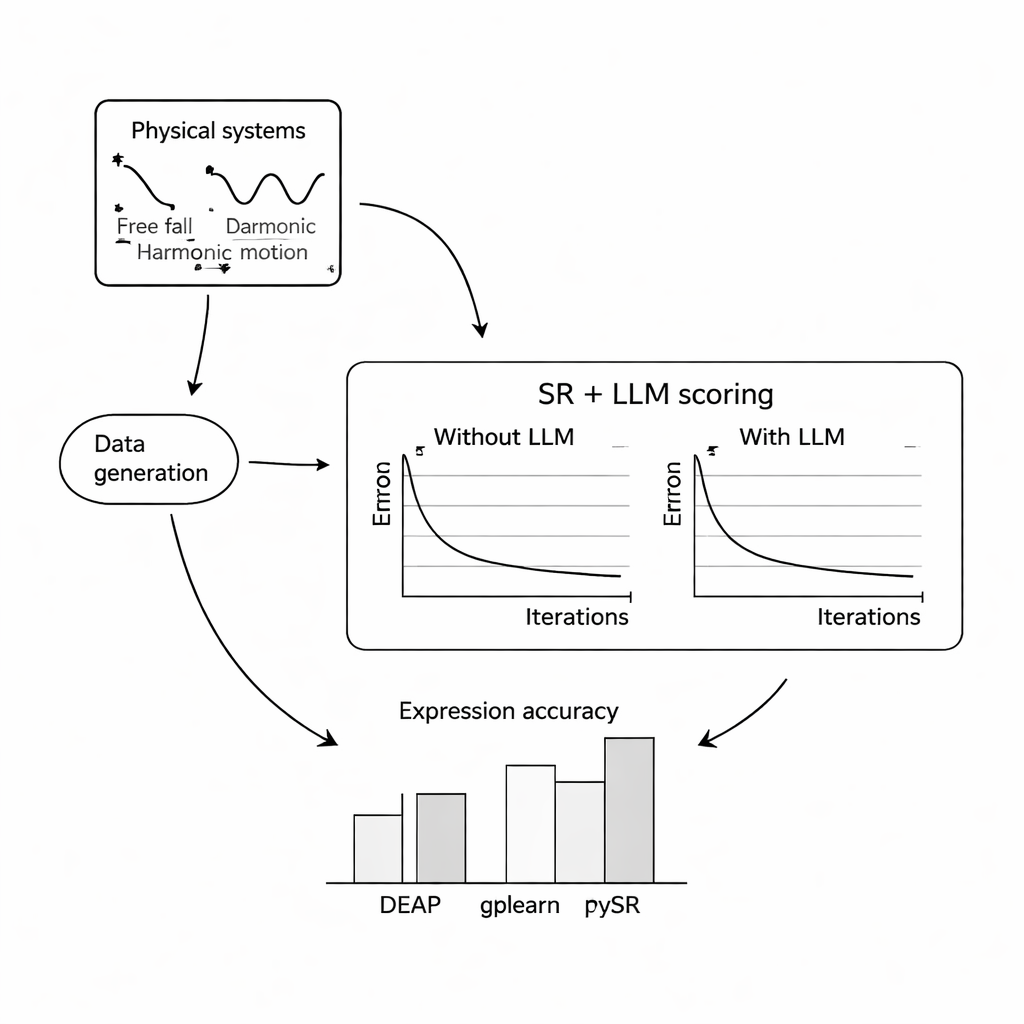
Wanneer woorden de wiskunde sturen
Een belangrijke bevinding is dat de bewoording van de prompt de uitkomsten sterk beïnvloedt. Wanneer prompts duidelijke beschrijvingen van variabelen, de aard van het experiment en soms de exacte doelformule bevatten, convergeerde de door het LLM gestuurde zoektocht betrouwbaarder naar de juiste structuur. In deze rijkere gevallen waren de ontdekte vergelijkingen vaak structureel identiek aan de grondwaarheidswetten, en niet alleen numeriek dicht daarbij. De auteurs testten ook hoe de aanpak standhoudt bij toenemende niveaus van willekeurige meetruis. Hoewel alle methoden degradeerden naarmate de data ruisiger werden en de onderliggende vergelijkingen complexer, verloren de met LLM aangevulde versies doorgaans langzamer aan nauwkeurigheid dan hun standaardtegenhangers, wat suggereert dat het plausibiliteitsgevoel van het taalmodel als stabiliserende factor kan werken.
Wat dit betekent voor toekomstige ontdekkingen
Voor algemene lezers is de belangrijkste boodschap dat tekstgebaseerde AI meer kan dan essays schrijven of vragen beantwoorden—het kan ook andere algoritmen richting wetenschappelijke vergelijkingen sturen die "goed aanvoelen" volgens onze bestaande kennis van de natuur. De hier gepresenteerde methode garandeert niet dat elke ontdekte vergelijking correct is, en blijft afhankelijk van menselijk toezicht en zorgvuldig opgestelde prompts. Maar het laat zien dat grote taalmodellen, getraind op zeeën van wetenschappelijke tekst, kunnen dienen als herbruikbare bron van domeinkennis, waarmee geautomatiseerde instrumenten kunnen overschakelen van blind datafiten naar het voorstellen van wetten die wetenschappers kunnen interpreteren, controleren en verder uitbouwen.
Bronvermelding: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Trefwoorden: symbolische regressie, fysica-geïnformeerde AI, grote taalmodellen, wetenschappelijke ontdekking, vergelijkingsleren