Clear Sky Science · nl
Een diepe reinforcement-learningbenadering voor de analyse van dansbewegingen
Computers leren dans te kijken zoals wij
Van klassiek ballet tot hiphop: dans zit vol subtiele verschuivingen in ritme en houding die het menselijk oog direct oppikt — maar die voor computers moeilijk waarneembaar zijn. Deze studie introduceert een nieuwe manier waardoor kunstmatige intelligentie dansvideo’s meer als een menselijke expert kan “bekijken”, door routinematige stukken over te slaan en zich te concentreren op korte, onthullende momenten die een stijl definiëren. Het resultaat is een systeem dat dansgenres nauwkeuriger herkent terwijl het veel minder video bekijkt, wat voordelen kan bieden voor alles van digitale archieven tot sport- en entertainmenttechnologieën.
Waarom dansvideo’s moeilijk zijn voor machines
Op het eerste gezicht lijkt het trainen van een computer om dansstijlen te herkennen eenvoudig: voer video’s in en laat deep learning patronen vinden. In werkelijkheid verspillen de meeste bestaande systemen moeite. Standaard videomodellen verwerken ofwel elk frame of bemonsteren clips op vaste intervallen, met de veronderstelling dat alle momenten even belangrijk zijn. Maar dansstijlen verschillen vaak in kleine details — hoe een voet draait, wanneer een partner draait, of de timing van een spin — in plaats van in constante beweging. Dat betekent dat veel frames repetitief of niet-informatief zijn, en dat sleutelposes tussen vaste bemonsteringspunten kunnen vallen, wat leidt tot verwarring tussen bijvoorbeeld een wals en een foxtrot.
Een slimmere manier om door video te bladeren
De onderzoekers stellen een raamwerk voor dat Reinforcement-based Attentive Temporal Sampling heet, of RATS, waarin videoanalyse wordt gezien als een actieve zoektocht in plaats van passief kijken. In plaats van frame voor frame te marcheren, verdeelt het systeem een dansvideo in korte clips en zet elke clip eerst om in een compacte beschrijving van de beweging met behulp van een gespecialiseerde 3D-convolutionele netwerktopologie. Deze bewegingssamenvattingen worden vervolgens in geheugen opgeslagen. Daarbovenop handelt een beslissingsagent die door de volgorde van clips stapt en kiest of hij een kleine sprong vooruit maakt, een grotere sprong, of stopt en een stijlvoorspelling afgeeft. In wezen leert het systeem hoe het door de tijd kan bladeren, waarbij het blijft hangen bij veelzeggende patronen en minder nuttige stukken overslaat.
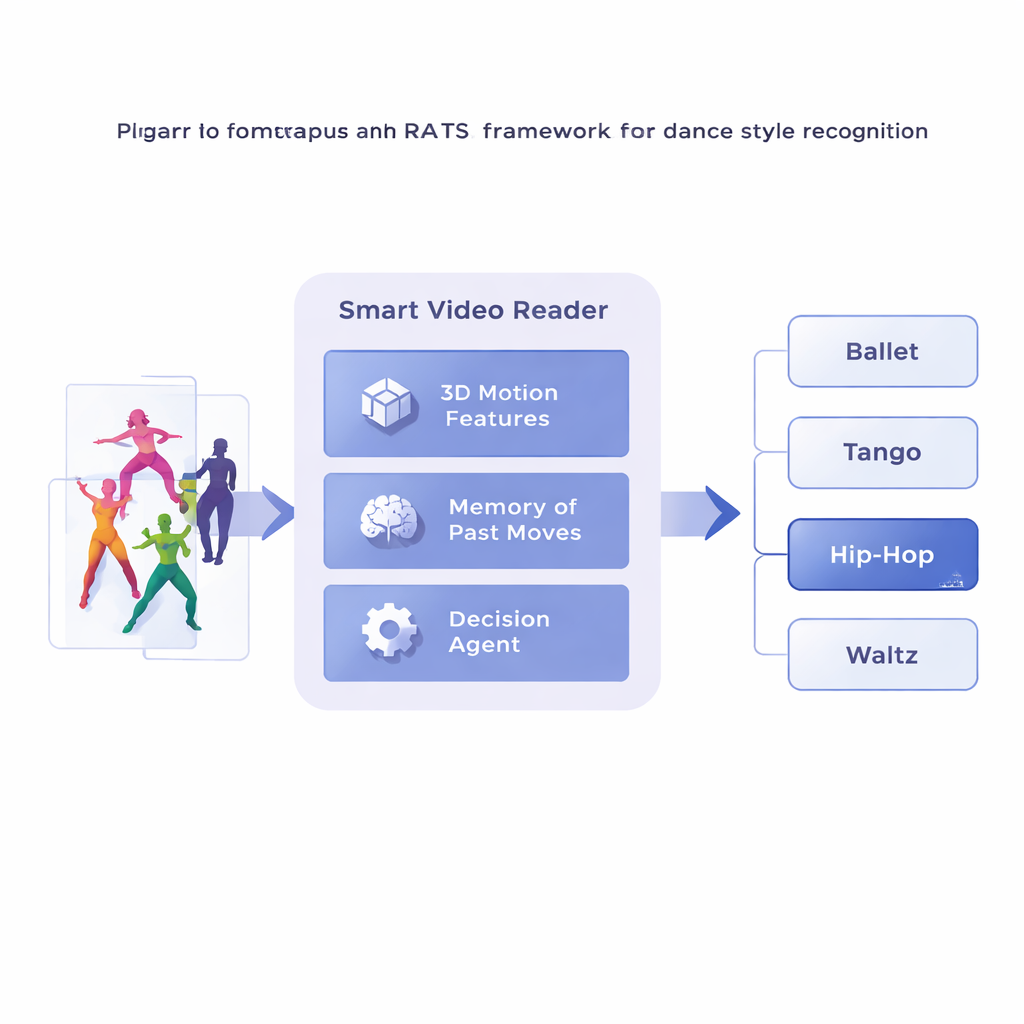
Leren wanneer te kijken en wanneer te beslissen
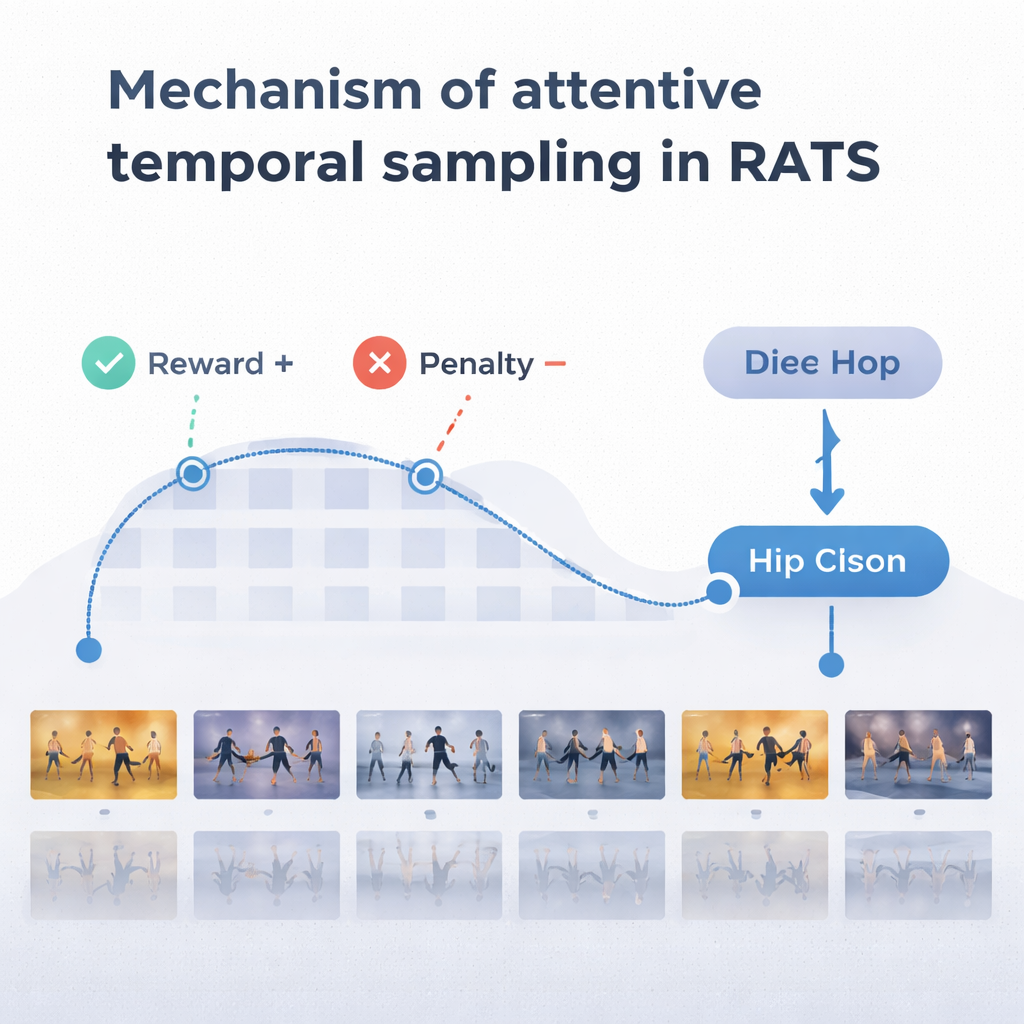
Om zinvolle keuzes te maken, vertrouwt de agent op een vorm van geheugen die is geïnspireerd op hoe wij zowel verleden als opkomende bewegingen herinneren. Een bidirectioneel recurrent netwerk houdt bij wat het systeem al “gezien” heeft en hoe de huidige clips zich tot die geschiedenis verhouden. Bij elke stap weegt de agent drie opties: een korte sprong maken om fijnmazige details zoals voetwerk te inspecteren, een langere sprong over repetitieve beweging maken, of stoppen en de dans classificeren. Het systeem wordt getraind met beloningen en straffen: het verdient een grote positieve score voor een correcte beslissing, een grote negatieve score voor een verkeerde, en een kleine straf telkens wanneer het vooruit springt. Deze balans moedigt de agent aan zowel nauwkeurig als efficiënt te zijn — wachten totdat er voldoende bewijs is, maar niet dwalen door de hele video.
Beter dan conventionele dansclassificatoren
Het team testte RATS op de Let’s Dance-dataset, een uitdagende verzameling van 1.000 video’s met tien stijlen, van Flamenco en Tango tot Swing en Square dance. Vergeleken met meerdere bestaande methoden, waaronder standaard deep-netwerken en andere dansgerichte modellen, behaalde RATS de hoogste nauwkeurigheid — ongeveer 92% — en de beste algehele balans tussen precisie en recall. Het bleek ook statistisch beter dan sterke concurrenten, en niet slechts licht verschillend door toeval. Belangrijk is dat het systeem deze resultaten bereikte terwijl het gemiddeld slechts ongeveer 38% van de videoframes analyseerde. Uniforme bemonstering van elke paar frames was sneller maar miste cruciale momenten en liet de prestaties dalen; elk frame verwerken was trager en nog steeds minder nauwkeurig dan de gerichte aanpak.
Wat dit betekent buiten de dansvloer
Voor leken is de kernboodschap eenvoudig: computers kunnen beter presteren wanneer ze leren selectieve kijkers te zijn. Door een AI te leren zich te concentreren op de “gouden momenten” in de tijd, toont dit werk dat machines complexe menselijke bewegingen nauwkeuriger kunnen herkennen terwijl ze minder middelen gebruiken. Hoewel de studie zich richt op dans, kan hetzelfde idee systemen helpen belangrijke elementen te herkennen in sportroutines, beveiligingsbeelden of elke lange video waarin belangrijke gebeurtenissen kort en verspreid zijn. Met andere woorden: slimmer kijken — niet meer kijken — kan de toekomst zijn van videobegrip.
Bronvermelding: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Trefwoorden: dansherkenning, video-analyse, deep learning, reinforcement learning, menselijke beweging