Clear Sky Science · nl
Model voor het extraheren van ruimtelijke relaties in het Chinees door integratie van geografische semantische kenmerken
Computers leren begrijpen waar plaatsen zich bevinden
Dagelijks beschrijven we locaties in eenvoudige uitdrukkingen: een stad ligt ten zuiden van een rivier, een park ligt bij een universiteit, een snelweg loopt door een provincie. Dit soort alledaagse taal omzetten in precieze digitale kennis is cruciaal voor slimme kaarten, navigatie-apps en geografisch onderzoek. Dit artikel presenteert een nieuwe methode, PURE‑CHS‑Attn, die computers helpt Chinese teksten te lezen en automatisch de ruimtelijke relaties tussen plaatsen nauwkeuriger vast te stellen dan voorheen.
Waarom ruimtelijke taal ertoe doet
Ruimtelijke relaties zijn woorden en zinnen die aangeven hoe plaatsen ruimtelijk verbonden zijn, zoals "binnen", "naast", "noord van" of "30 kilometer van". Ze vormen een brug tussen de echte wereld die we op kaarten zien en de concepten die we in ons hoofd gebruiken. In geografische informatiesystemen (GIS) vormen deze relaties de basis voor hoe data worden georganiseerd, doorzocht en geanalyseerd. Ze zijn ook centraal in andere gebieden: bijvoorbeeld het combineren van satellietbeelden, het volgen van bewegingen in video, het plannen van industriële lay-outs of het bestuderen van hoe klimaat en reliëf biodiversiteit beïnvloeden. Omdat veel van deze informatie in natuurlijke taal is geschreven, wordt het steeds belangrijker betrouwbare hulpmiddelen te hebben die tekst kunnen lezen en ruimtelijke relaties automatisch kunnen extraheren.
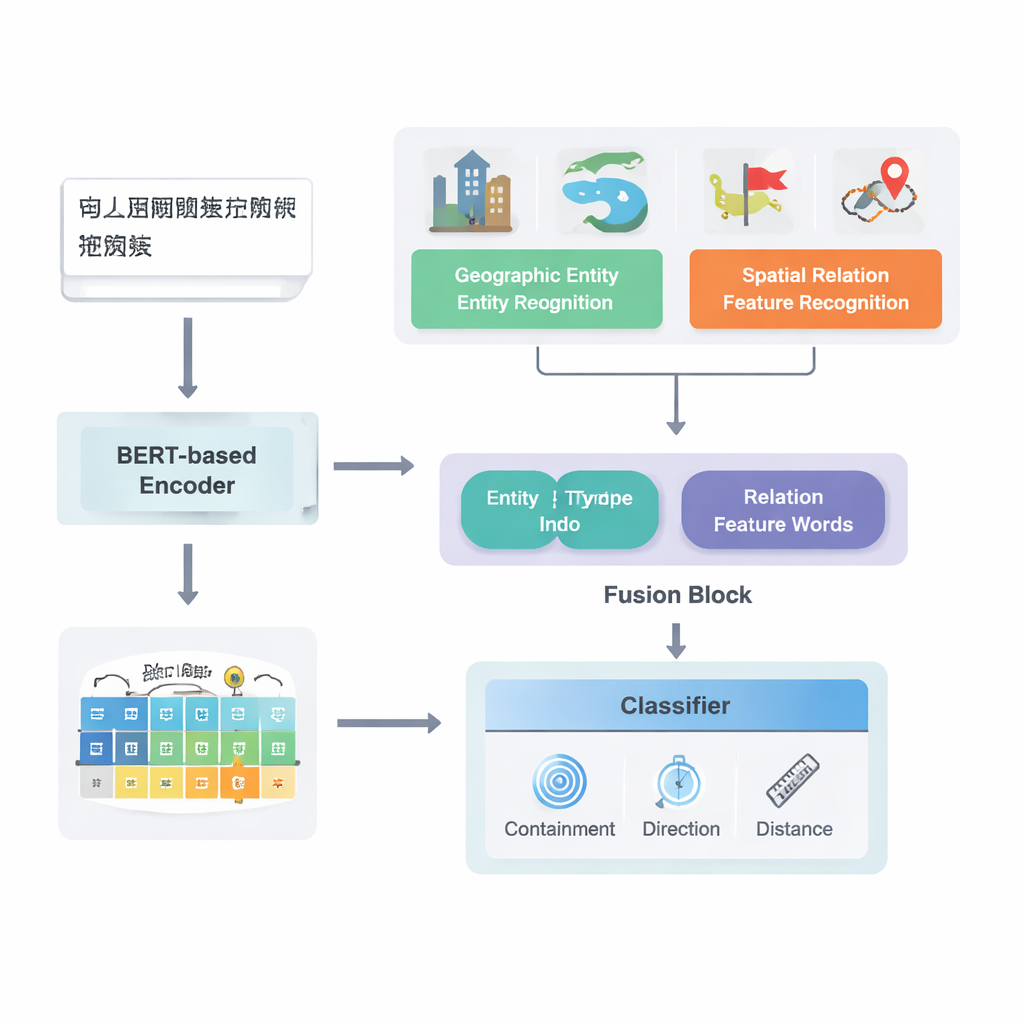
Van ruwe tekst naar in kaart gebrachte relaties
De auteurs richten zich op Chinese teksten en bouwen voort op een krachtige bestaande deep learning-pijplijn bekend als PURE. Hun verbeterde model, PURE‑CHS‑Attn, werkt in meerdere fasen. Eerst scant het zinnen om geografische entiteiten te vinden zoals bergen, rivieren, steden en bestuurlijke gebieden, en labelt elk met een type (bijvoorbeeld landoppervlak, waterlichaam, openbare voorziening, historische locatie of bestuurlijke eenheid). Vervolgens detecteert het model ruimtelijke relatiewoorden zoals "grens", "stroomt door", "ten zuiden van" of "dicht bij", die aangeven hoe twee plaatsen zich tot elkaar verhouden. Een krachtig taalmodel, BERT‑wwm‑ext, zet de karakters in elke zin om in numerieke vectoren die hun betekenis en context vastleggen. Deze vectoren voeden afzonderlijke componenten die entiteiten en relatiewoorden herkennen en geven hun resultaten door aan een fusiemodule.
Menselijke kennis mengen met machine learning
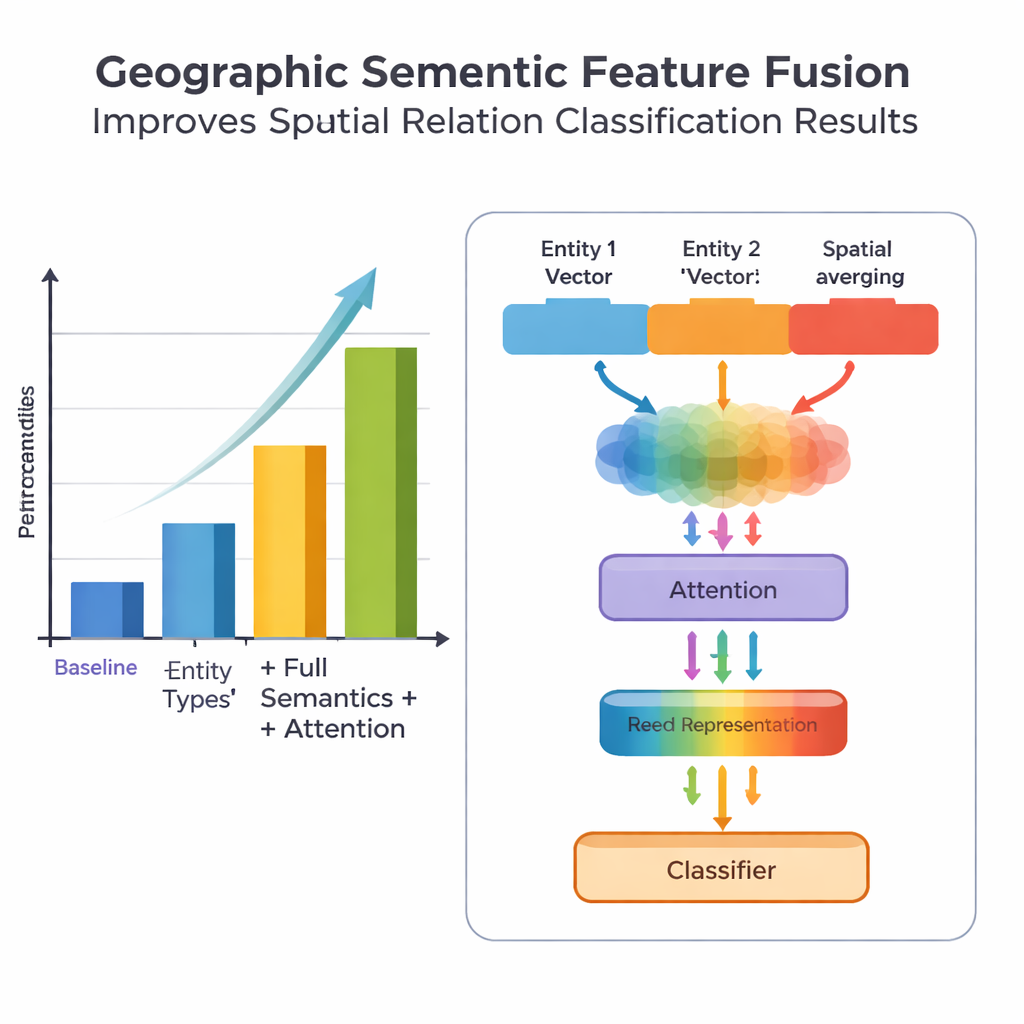
Een belangrijke nieuwigheid van het werk zit in hoe het geografische kennis met geleerd tekstpatroon fusioneert. In plaats van elk woord gelijk te behandelen, benut het model twee soorten semantische informatie die mensen van nature gebruiken: het type van elke geografische entiteit en de specifieke ruimtelijke relatiewoorden die ze verbinden. De fusiemodule combineert eerst de vectoren voor de twee entiteiten met gewichten die afhangen van hoe vaak verschillende typen plaatsen (zoals twee bestuurlijke regio's versus een rivier en een district) deelnemen aan verschillende relatiecategorieën. Daarna voegt het de vectoren van de ruimtelijke relatiewoorden toe. Bovenop deze "basisfusie" voegen de auteurs een attentie-mechanisme toe dat het model dynamisch laat focussen op de meest informatieve delen van de entiteit–woordcombinatie. De uiteindelijke gefuseerde representatie wordt doorgegeven aan een classifier, die één of meer relatiecategorieën kan toewijzen — topologisch (zoals inclusie of aangrenzend), directioneel (noord, zuid, enz.) of afstandsgebaseerd — tussen elk paar plaatsen in de zin.
Het model op de proef stellen
Om hun aanpak te evalueren hebben de onderzoekers een dataset samengesteld en zorgvuldig geannoteerd uit de Encyclopedia of China: Chinese Geography, met 1381 zinnen en 368 ruimtelijke relatieparen. Ze vergeleken meerdere versies van het model: een baseline die alleen grove locatie-informatie gebruikt, een versie met fijnere entiteitstypen, een versie die ook ruimtelijke relatiewoorden toevoegt, en hun volledige PURE‑CHS‑Attn-model met het nieuwe fusie- en attentieontwerp. Volgens standaardmaatstaven voor precisie, recall en F1-score verbeterde PURE‑CHS‑Attn de prestaties met ongeveer 7% in precisie, 6,5% in recall en 6,7% in F1 ten opzichte van de baseline. Het presteerde vooral sterk bij het herkennen van topologische en directionele relaties en ging beter om met zeldzame "few-shot" relatietypen dan eenvoudigere modellen. In vergelijking met drie recente state-of-the-art systemen, waaronder één gebaseerd op grote taalmodellen, eindigde PURE‑CHS‑Attn als een nabije tweede terwijl het veel lichter en gemakkelijker te implementeren bleef.
Uitdagingen en toekomstige richtingen
Ondanks deze verbeteringen heeft het model nog steeds moeite met afstandsrelaties, vooral wanneer er maar een handvol trainingsvoorbeelden beschikbaar is. De auteurs tonen aan dat hun dataset zeer weinig van zulke gevallen bevat, wat beperkt wat een datahongerig methode kan leren. Ze merken ook op dat het klakkeloos middelen van veel ruimtelijke relatiewoorden in een zin ruis kan introduceren; hun attentie-mechanisme helpt dat, maar lost het niet volledig op. Vooruitkijkend suggereren ze twee veelbelovende paden: het uitbreiden en balanceren van trainingsdata met augmentatie, en het combineren van hun geografische semantische fusie met technieken uit grote taalmodellen en prompt-gebaseerd leren om de prestaties in data-arme scenario's verder te verbeteren terwijl het systeem efficiënt blijft.
Wat dit betekent voor alledaagse kaarttoepassingen
In eenvoudige bewoordingen leert dit onderzoek computers om ruimtelijke beschrijvingen in het Chinees meer zoals mensen te lezen, door aandacht te besteden aan welke soorten plaatsen genoemd worden en precies hoe hun relaties geformuleerd zijn. Het PURE‑CHS‑Attn-model laat zien dat het mengen van gestructureerde geografische kennis met moderne deep learning leidt tot nauwkeurigere en robuustere extractie van "wie is waar, ten opzichte van wat" uit tekst. Dit effent het pad voor slimere, meer geautomatiseerde GIS-systemen, rijkere geografische kennisgrafen en betere hulpmiddelen om te onderzoeken hoe ruimte beschreven wordt in wetenschap, beleid en alledaagse communicatie.
Bronvermelding: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Trefwoorden: extraheren van ruimtelijke relaties, geospatiale AI, geografische semantiek, Chinees tekstmining, GIS-automatisering