Clear Sky Science · nl
Voorspelling van de ziekte van Alzheimer met deep learning en XAI-gebaseerde interpreteerbare feature-selectie uit genexpressiegegevens in bloed
Waarom dit onderzoek belangrijk is
De ziekte van Alzheimer berooft mensen geleidelijk van hun geheugen en zelfstandigheid, maar de nauwkeurigste huidige tests vereisen vaak hersenscans of ruggenprikken die duur, invasief en moeilijk te herhalen zijn. Deze studie onderzoekt een minder belastend alternatief: met een eenvoudige bloedafname en geavanceerde computeranalyse patronen in genactiviteit opsporen die op Alzheimer wijzen, wat mogelijk de weg vrijmaakt voor vroegere en beter toegankelijke diagnostiek.
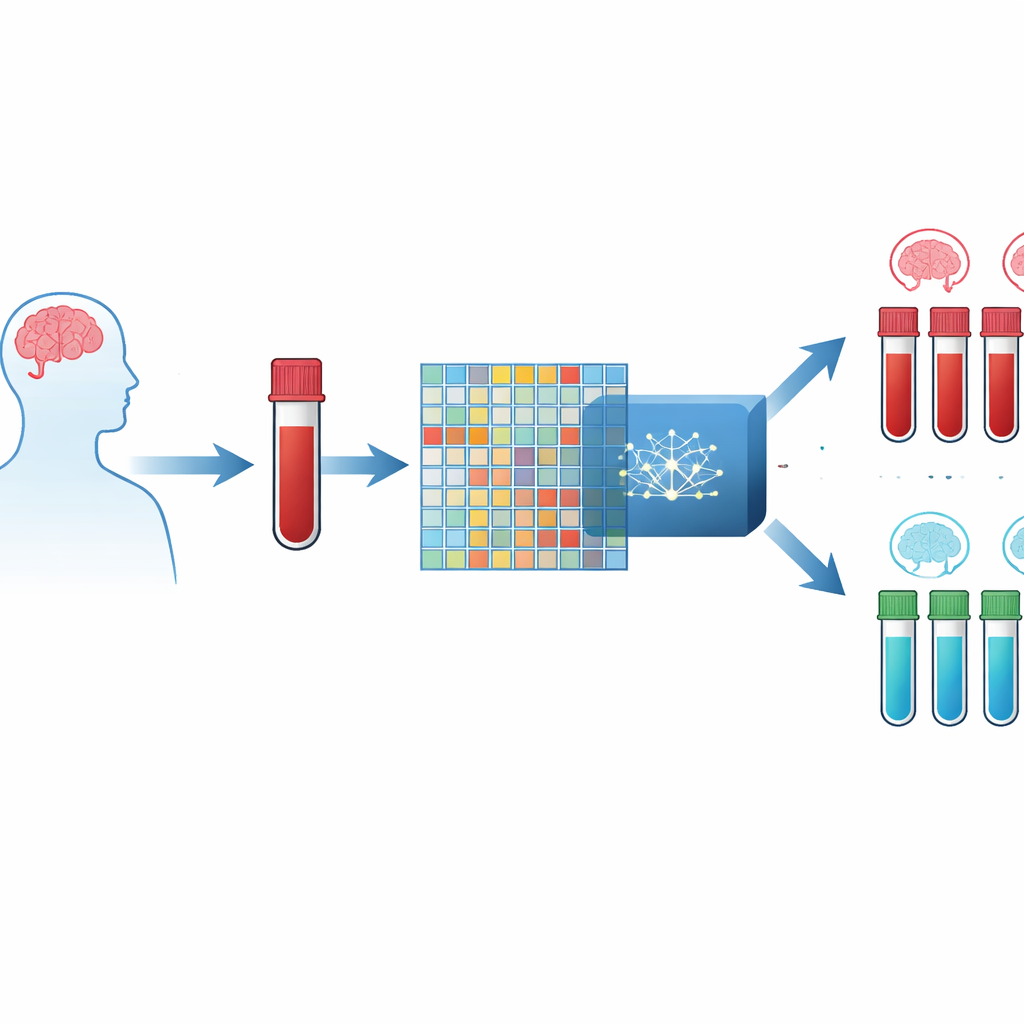
Een bloedtest in plaats van een hersenscan
De auteurs richten zich op kleine veranderingen in hoe genen aan- of uitgezet worden in bloedcellen. Moderne laboratoriumchips kunnen tegelijk de activiteit van duizenden genen meten, wat voor elke persoon een enorme tabel met waarden oplevert. De uitdaging is dat er veel meer genmetingen zijn dan patiënten, wat computermodellen gemakkelijk op een dwaalspoor kan brengen. Om dit te omzeilen combineerden de onderzoekers drie grote openbare datasets van bloedmonsters van mensen met Alzheimer en van gezonde vrijwilligers, en creëerden zo een geïntegreerde bron met meer dan twaalfduizend gemeenschappelijke genen gemeten bij honderden individuen.
Computers leren de belangrijkste waarschuwingssignalen te kiezen
In plaats van een algoritme te vragen alle twaalfduizend genen te verwerken, leerden de onderzoekers het eerst een veel kleinere set bijzonder informatieve genen te selecteren. Ze vergeleken verschillende manieren om dit te doen, waaronder eenvoudige statistische tests, methoden die minder nuttige genen stapsgewijs verwijderen, en benaderingen die de selectie direct in het model inbouwen. Deze “feature selection”-instrumenten beperkten de lijst tot honderden of iets meer dan duizend genen die het beste patiënten van gezonde controles onderscheidden. De gereduceerde genensets voorkwamen dat de modellen ruis gingen onthouden en verbeterden hun prestaties op niet eerder geziene data.
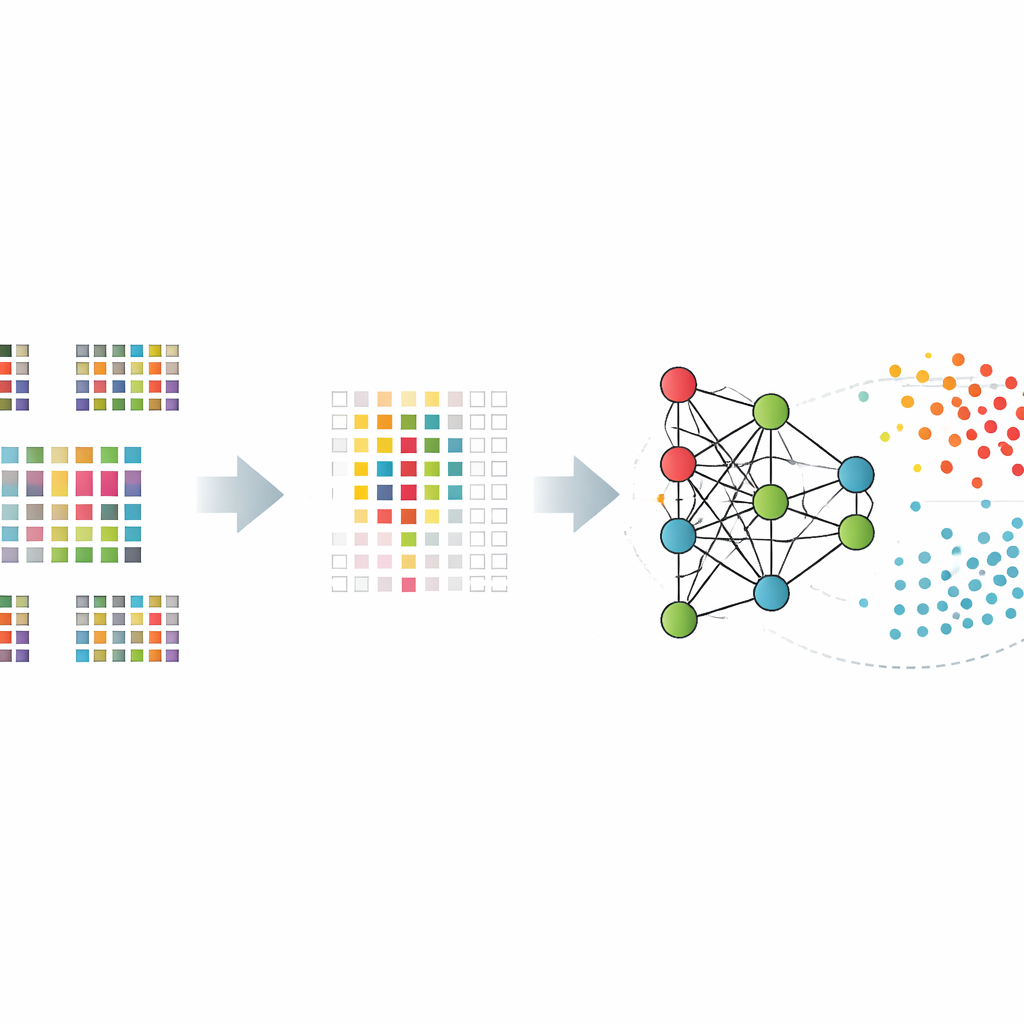
Het zwarte vakje begrijpelijk maken
Om blind vertrouwen in een black-boxvoorspelling te vermijden, gebruikten de onderzoekers technieken van verklaarbare kunstmatige intelligentie om te begrijpen welke genen er het meest toe deden en hoe ze elke beslissing beïnvloedden. Een methode genaamd SHAP, ontleend aan de speltheorie, scoort de bijdrage van elk gen aan de uiteindelijke uitkomst voor iedere persoon. Door deze toe te passen op hun best presterende modellen, lichtten de auteurs een kerngroep genen uit waarvan de activiteitspatronen consequent de schaal in de richting van een Alzheimer- of gezonde classificatie deden doorslaan. Veel van deze genen zijn al in verband gebracht met hersengezondheid of immuunfunctie, wat biologische geloofwaardigheid verleent aan de interne werking van het model.
Kracht vergroten met synthetische patiënten
Zelfs na het samenvoegen van datasets bleef het aantal echte bloedmonsters beperkt. Om hun modellen te versterken trainden de auteurs een gespecialiseerd type neuraal netwerk, bekend als een generative adversarial network, om realistische synthetische genprofielen te maken die lijken op die van echte patiënten. Deze kunstmatige monsters werden alleen toegevoegd aan de trainingsdata, nooit aan de testdata, zodat de prestatiecontroles eerlijk bleven. Met deze uitgebreidere trainingspool en zorgvuldig gekozen genen kon een diep neuraal netwerk Alzheimervoorbeelden identificeren met ongeveer 91% totale nauwkeurigheid en 95% precisie, wat betekent dat zeer weinig gezonde mensen ten onrechte als ziek werden aangemerkt.
Wat de bevindingen betekenen voor patiënten
Dit werk suggereert dat een toekomstige bloedtest voor Alzheimer, aangedreven door slimme algoritmen die zowel sleutelgenen selecteren als verklaren, een aanvulling kan zijn op of zelfs de afhankelijkheid van dure scans en invasieve procedures kan verminderen. Hoewel meer validatie nodig is op onafhankelijke patiëntengroepen en verschillen tussen labmethoden beter gecontroleerd moeten worden, toont de studie aan dat het combineren van meerdere datasets, het wegsnijden van niet-helpende informatie en het openen van de “black box” van AI ons dichter bij een praktische, interpreteerbare bloedtest voor vroegere en comfortabelere detectie van Alzheimer kan brengen.
Bronvermelding: Hariharan, J., Jothi, R. Alzheimer’s disease prediction using deep learning and XAI based interpretable feature selection from blood gene expression data. Sci Rep 16, 8022 (2026). https://doi.org/10.1038/s41598-026-35260-8
Trefwoorden: Diagnose van Alzheimer, bloed biomarkers, genexpressie, deep learning, verklaarbare AI