Clear Sky Science · nl
Machine learning-benadering voor het identificeren van tarwerassen met enkelzaadbeeldvorming
Waarom slimmer zaaigoed sorteren ertoe doet
Voor boeren en zaadbedrijven is het essentieel om het ene tarweras van het andere te kunnen onderscheiden. Het planten van het verkeerde ras kan leiden tot lagere opbrengsten, slechtere ziekteresistentie en gewassen die niet geschikt zijn voor de lokale bodem of het klimaat. Toch zien verschillende tarwerassen er met het blote oog bijna identiek uit. Deze studie onderzoekt hoe kunstmatige intelligentie en digitale foto’s van individuele zaden betrouwbaar nauwe rassen van elkaar kunnen onderscheiden, en zo de weg vrijmaken voor snellere, goedkopere en objectievere kwaliteitscontroles van zaaigoed.
Van deskundig oordeel naar camera-gecontroleerde inspectie
Vandaag de dag zijn veel zaadinspectiesystemen nog afhankelijk van menselijke experts die zaden visueel beoordelen op ras en zuiverheid. Dit proces is traag, duur en vatbaar voor meningsverschillen, vooral omdat veel tarwecultivars alleen verschillen door subtiele veranderingen in vorm of oppervlaktestructuur. De auteurs wilden deze subjectieve aanpak vervangen door een geautomatiseerd systeem dat beelden van individuele tarwekorrels gebruikt die zijn gemaakt in een kleine, lichtgecontroleerde doos. Door zorgvuldig verlichting, afstand en achtergrondkleur te standaardiseren, creëerden zij een schoon visueel beeld van zes veelvoorkomende Iraanse tarwerassen en genereerden ze tienduizenden zaadfoto’s om computermodellen mee te trainen en te testen.
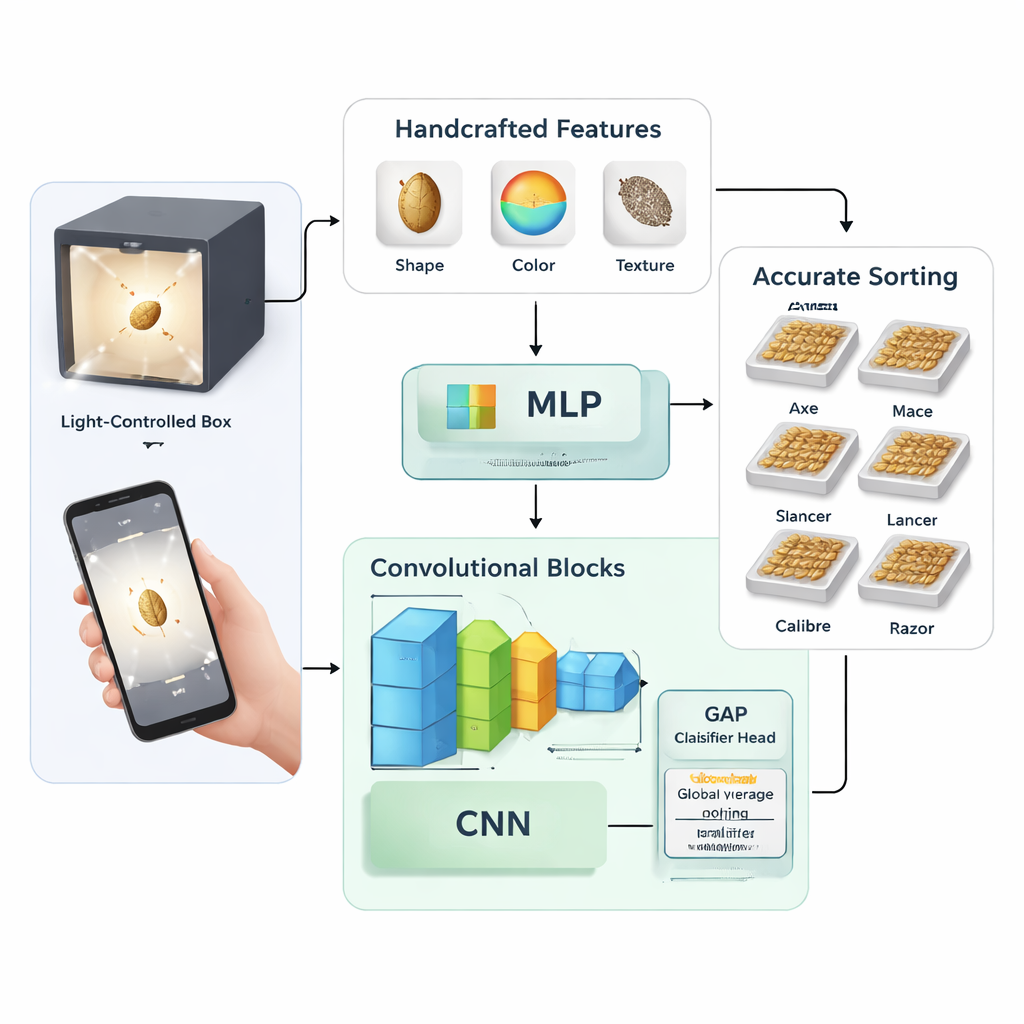
Twee manieren om een computer zaden te leren zien
De studie vergelijkt twee brede strategieën om een machine tarwerassen te leren herkennen. In de eerste strategie stelden de onderzoekers handmatig 58 numerieke metingen op uit elke zaadfoto, waaronder basisvorm (zoals lengte en oppervlakte), kleurstatistieken in verschillende kleurenspaces en textuurpatronen. Vervolgens gebruikten ze een techniek genaamd hoofdcomponentenanalyse om deze metingen te comprimeren tot 27 sleutelkenmerken, die als input dienden voor een traditioneel neuraal netwerk, een multilayer perceptron. In de tweede strategie sloegen ze handmatig feature-ontwerp over en trainden ze convolutionele neurale netwerken—beeldgerichte AI-modellen—om nuttige patronen rechtstreeks uit de ruwe pixelgegevens te leren.
Een slank maar krachtig deep-learningmodel bouwen
De deep-learningaanpak werd in meerdere varianten getest. De auteurs ontwierpen hun eigen relatief kleine netwerk met twee tot vier gestapelde convolutionele blokken en experimenteerden met verschillende trainingsinstellingen, zoals leersnelheden, dropout-niveaus en batchgroottes. Ze vergeleken ook twee manieren om het netwerk af te ronden: een klassieke "fully connected" laag versus een compactere methode genaamd global average pooling, die grote dense lagen vervangt door een eenvoudige gemiddelde-stap vóór de uiteindelijke classificatie. Ter vergelijking finetuneden ze twee zware, veelgebruikte architecturen—Inception-ResNet-v2 en EfficientNet-B4—op dezelfde tarwedataset om te zien hoe een op maat gemaakt klein model zich verhoudt tot diepe, algemene netwerken.
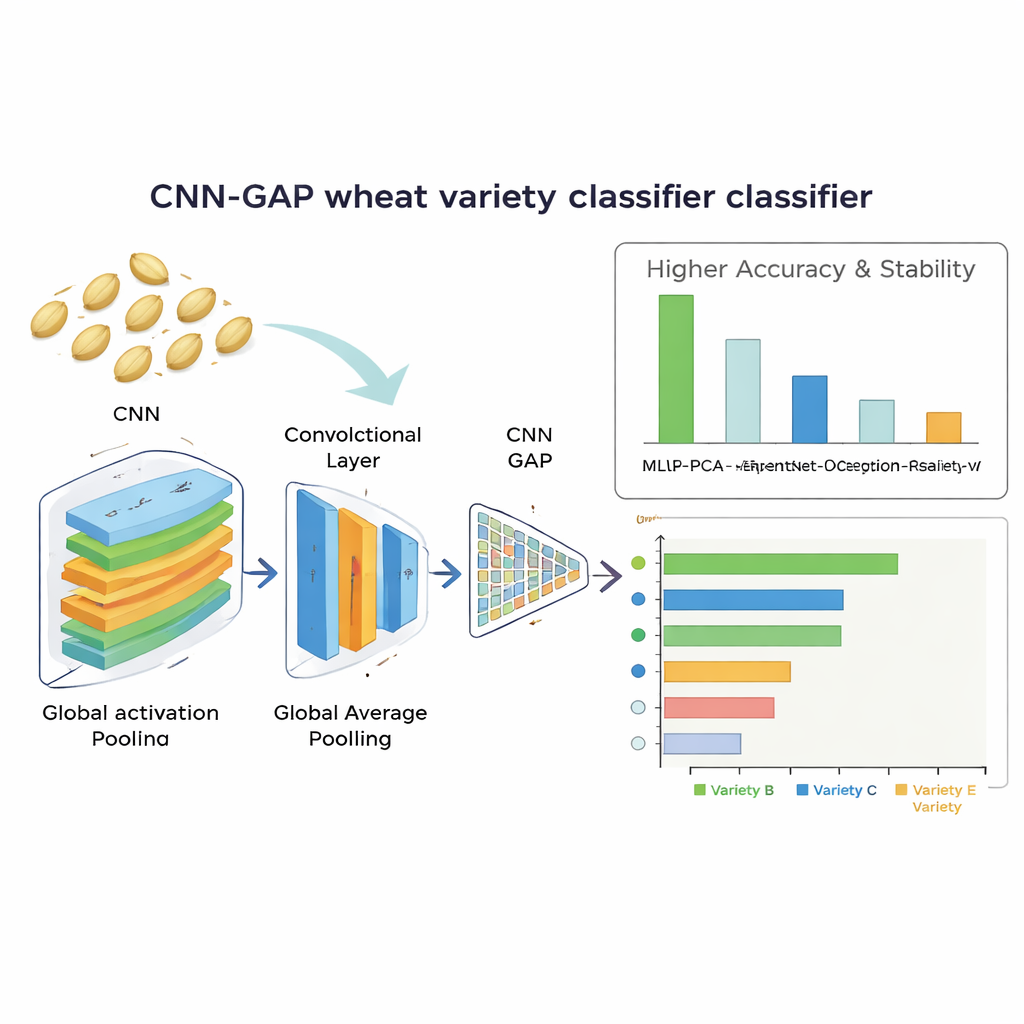
Hoe goed het systeem de korrel leest
De beste prestatie werd geleverd door het op maat gemaakte convolutionele netwerk dat global average pooling gebruikte. Het identificeerde tarwerassen correct in ongeveer 92% van de gevallen en toonde zeer stabiele resultaten over herhaalde trainingsruns. Dit model overtrof niet alleen de grote voorgetrainde netwerken, maar overtrof ook de handmatig samengestelde feature-benadering, die na dimensiereductie ongeveer 86% nauwkeurigheid bereikte. De analyse van verwarringspatronen toonde aan dat het lichtere model bijzonder goed was in het scheiden van rassen die er zeer vergelijkbaar uitzagen, terwijl de diepere transfer-learning modellen de neiging hadden te overfitten op de beperkte dataset. Belangrijk is dat het winnende netwerk efficiënt was: het verwerkte elke zaadafbeelding in ongeveer 13,6 milliseconden en bevatte slechts ongeveer 2,1 miljoen aanpasbare parameters, waardoor het realistisch is voor gebruik in goedkope real-time sorteerapparatuur.
Beperkingen, praktijkgebruik en wat volgt
Toen hetzelfde model werd getest op een geheel andere teelt—kikkererwtenzaden—daalde de nauwkeurigheid sterk, wat aantoont dat een systeem dat is afgestemd op fijne verschillen tussen tarwekorrels niet automatisch generaliseert naar andere soorten. Evenzo, omdat alle trainingsafbeeldingen uit een zorgvuldig gecontroleerde kamer kwamen, kan de prestatie afnemen onder wisselende veldverlichting of bij deels verborgen korrels. Desondanks toont het werk aan dat een compact, goed ontworpen deep-learningmodel, gevoed met gestandaardiseerde enkelzaadbeelden, betrouwbaar tarwerassen kan onderscheiden die met het blote oog bijna niet te onderscheiden zijn. Met bredere trainingsdata en meer gevarieerde beeldomstandigheden zouden vergelijkbare systemen praktische hulpmiddelen kunnen worden voor geautomatiseerde zaadcertificering, waardoor boeren zuiverdere zaadpartijen en voorspelbaardere oogsten kunnen veiligstellen.
Bronvermelding: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Trefwoorden: tarwezaden, deep learning, beeldgebaseerde classificatie, zaadkwaliteit, precisie-landbouw