Clear Sky Science · nl
Voorkeur voor feature-engineering boven architecturale complexiteit bij voorspelling van intermitterende vraag
Waarom het voorspellen van zeldzame verkopen ertoe doet
Achter elke autoreparatiewerkplaats of onderdelenmagazijn ligt een stil raadsel: hoeveel langzaam draaiende reserveonderdelen moeten op de plank liggen? Deze artikelen worden zelden en onvoorspelbaar verkocht, maar moeten beschikbaar zijn wanneer een voertuig uitvalt. Te veel bestellen betekent kapitaal vastgezet in stoffige voorraad; te weinig bestellen betekent dat klanten moeten wachten terwijl onderdelen worden aangevoerd. Dit artikel pakt dat alledaagse maar kostbare probleem aan door een eenvoudige vraag te stellen: is het beter om steeds complexere voorspellingsmodellen te gebruiken, of bestaande modellen te voeden met slimmer, zorgvuldig ontworpen signalen uit de data?
Van lange perioden van niets tot plotselinge pieken
In veel toeleveringsketens, vooral voor automotive reserveonderdelen, is de vraag niet stabiel zoals bij melk of brood. In plaats daarvan zijn er lange periodes van maanden zonder verkopen, onderbroken door plotselinge bestellingen van een paar stuks. De auteurs analyseren meer dan 56.000 dealer–onderdeelcombinaties, goed voor ongeveer 1,4 miljoen maandelijkse waarnemingen, en vinden dat de meeste reeksen extreem schaars zijn: gemiddeld zijn er veel nulmaanden voor elke maand met een verkoop, en de omvang van bestellingen schommelt sterk. Traditionele statistische methoden zoals de Croston-aanpak en haar verfijningen zijn ontwikkeld voor dit soort "aan–uit"-vraag en geven stabiele, interpreteerbare voorspellingen, maar behandelen elk onderdeel geïsoleerd en kunnen niet gemakkelijk extra informatie gebruiken zoals prijzen of productkenmerken. Moderne machine-learningsystemen kunnen in principe al deze informatie benutten, maar ze hebben vaak moeite wanneer de data grotendeels uit nullen bestaat en slechts af en toe informatief is.
Een eenvoudig idee: leer het model wat echt telt
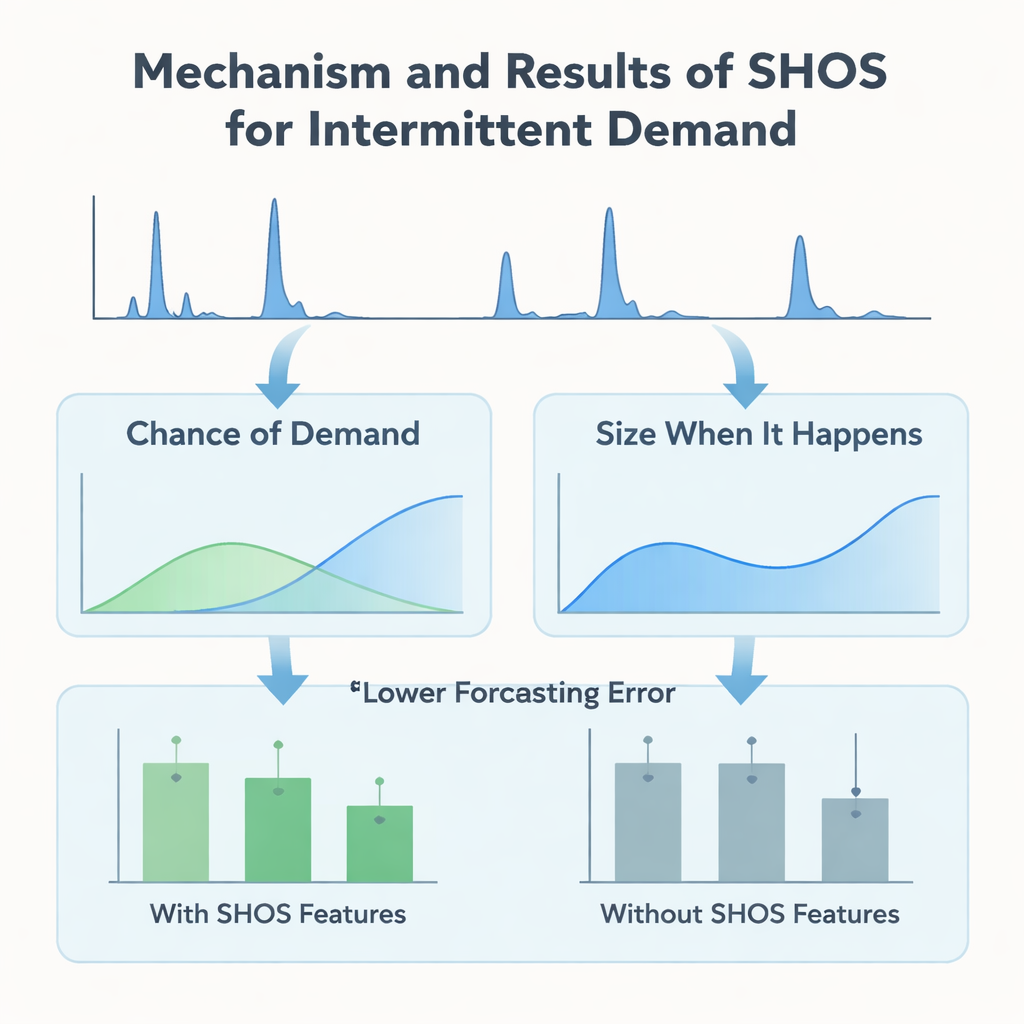
In plaats van steeds ingewikkeldere machine-learningarchitecturen te ontwerpen, richten de auteurs zich op wat er in het model gaat. Ze introduceren het Smoothed Hybrid Occurrence–Size (SHOS) framework, een lichtgewicht statistische routine die over elke vraagsgeschiedenis draait. Voor elke maand produceert SHOS twee getallen: de geschatte kans dat er volgende maand vraag zal zijn, en de typische omvang van die vraag als die er is. Dit doet het door zorgvuldig eerdere nullen en niet-nullen te versoepelen, zijn gedrag aan te passen voor zeer schaarse reeksen en sneller te reageren wanneer de vraag na een lange stilte plotseling terugkeert. Cruciaal is dat SHOS niet het uiteindelijke voorspellingsmodel is. De outputs worden extra invoerfeatures voor standaard machine-learningalgoritmen, naast eenvoudige items zoals recente verkopen, voortschrijdende gemiddelden en statische productgegevens.
Feature-kwaliteit boven modelcomplexiteit plaatsen
Om te testen of deze statistische "pre-processing" echt helpt, bouwen de onderzoekers een gecontroleerd experiment. Ze vergelijken een reeks populaire modellen—gradient-boosted trees, random forests en lineaire methoden—met en zonder SHOS-features, allemaal getraind op hetzelfde maandelijkse paneel met nullen en geëvalueerd met een rigoureus rollend-venster schema dat echte inzet nabootst. Ze testen ook meer uitgebreide tweefasige "hurdle"-modellen die gescheiden voorspellen of er vraag zal zijn en hoe groot die zal zijn. Over 11 validatievensters halveert het toevoegen van SHOS-features bijna de gemiddelde voorspellingsfout voor sterk intermitterende items en verlaagt het een belangrijke zakelijke maatstaf, gewogen gemiddelde absolute procentuele fout, met meer dan 40%. Verrassend genoeg presteren de tweefasige architecturen, ondanks dat ze complexer en op dit soort data afgestemd zijn, niet beter dan een enkele, eenvoudige regressor die simpelweg de SHOS-signalen gebruikt.
Zien hoe het model zijn keuzes maakt
Het team gaat verder dan de kopcijfers over nauwkeurigheid en onderzoekt hoe de modellen de gegeven informatie daadwerkelijk gebruiken. Met behulp van SHAP, een standaardtool voor het interpreteren van machine-learningvoorspellingen, tonen ze aan dat de op SHOS gebaseerde features—"kans op vraag" en "grootte wanneer het gebeurt"—consistent behoren tot de meest invloedrijke invoeren. Tijdens lange periodes zonder vraag duwt een lage SHOS-kans de voorspellingen richting nul en voorkomt zo een verkeerde voorraadopbouw. Wanneer na een droge periode een golf van vraag verschijnt, verhoogt een recentheidsaanpassing in SHOS snel de kans- en omvangschattingen, waardoor het model kan reageren zonder overmatig te reageren op een enkele piek. Deze gedragingen zijn zichtbaar zowel in het eenvoudige enkelvoudige model als in de meer complexe hurdle-versies, wat benadrukt dat de belangrijkste winst voortkomt uit de kwaliteit van de signalen, niet uit architecturale trucjes.
Wat dit betekent voor dagelijkse voorraadbeslissingen
Voor praktijkmensen die proberen de juiste onderdelen op voorraad te houden, is de boodschap zowel praktisch als geruststellend. De studie toont aan dat zorgvuldig ontworpen, statistisch onderbouwde features grote verbeteringen kunnen opleveren bij het voorspellen van zeldzame, onregelmatige verkopen zonder terug te vallen op kwetsbare, moeilijk te onderhouden modelopstellingen. Een bescheiden, goed afgestemde gradient-boosted tree uitgerust met SHOS-features presteert beter of gelijk aan meer uitgebreide pijplijnen en is tegelijkertijd eenvoudiger te implementeren en te monitoren voor tienduizenden artikelen. Simpel gezegd: je voorspellingssysteem betere samenvattingen geven van hoe vaak en hoeveel klanten waarschijnlijk bestellen, kan zwaarder wegen dan upgraden naar het nieuwste, meest complexe algoritme. Deze nadruk op eenvoudige, interpreteerbare bouwstenen maakt de aanpak aantrekkelijk voor grootschalige, praktische toeleveringsketens en suggereert dat vergelijkbare feature-gecentreerde strategieën ook in andere sectoren met intermitterende vraag de moeite waard kunnen zijn.
Bronvermelding: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Trefwoorden: intermitterende vraag, voorspelling van reserveonderdelen, feature-engineering, supply chain-analyse, machine learning