Clear Sky Science · nl
Evaluatie van ChatGPT-4o en Gemini voor de behandeling van jicht: een vergelijkende analyse op basis van EULAR-richtlijnen
Waarom slimme chatbots en pijnlijke gewrichten ertoe doen
Jicht, een pijnlijke vorm van artritis die vaak de grote teen treft, komt wereldwijd steeds vaker voor. Artsen hebben al duidelijke, op wetenschap gebaseerde richtlijnen om het te diagnosticeren en te behandelen, maar veel patiënten krijgen nog steeds niet de optimale zorg. Tegelijkertijd verschijnen krachtige kunstmatige-intelligentiechatbots zoals ChatGPT-4o en Gemini in zorgomgevingen, wat een eenvoudige maar cruciale vraag oproept: kunnen deze hulpmiddelen daadwerkelijk veilige, richtlijnconforme adviezen geven over jicht, of kunnen ze artsen en patiënten op het verkeerde been zetten?
Controleren hoe goed de chatbots de regels volgen
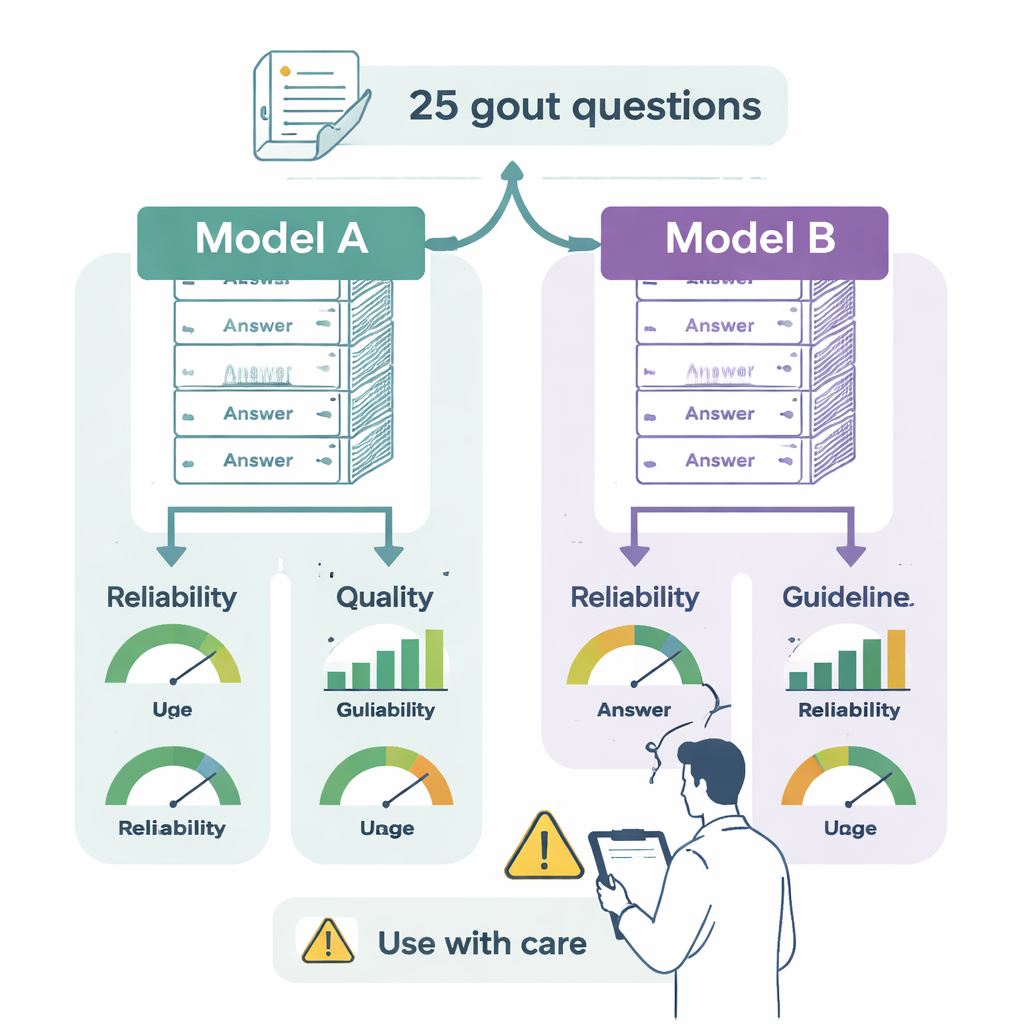
De onderzoekers wilden twee toonaangevende taalmodellen testen — ChatGPT-4o en Gemini 2.0 Flash — aan de hand van de officiële Europese (EULAR) richtlijnen voor jicht. Twee specialisten zetten 25 kernaanbevelingen uit de richtlijnen om in artsachtige vragen over kwesties uit de dagelijkse praktijk: hoe jicht te diagnosticeren, wanneer urateremmende medicatie te starten, hoe aanvallen te behandelen, welke streefwaarden in bloedtesten te hanteren, en hoe levensstijl of andere geneesmiddelen aangepast moeten worden. Beide chatbots kregen dezelfde vragen in aparte, schone sessies zodat eerdere antwoorden geen invloed zouden hebben op nieuwe reacties.
Hoe de antwoorden werden beoordeeld
Elk antwoord werd beoordeeld door twee ervaren jichtspecialisten die niet wisten welk model de tekst had gegenereerd. Ze waardeerden drie zaken. Ten eerste betrouwbaarheid: lijkt het antwoord evenwichtig, objectief en betrouwbaar, of laat het belangrijke feiten weg of overdrijft het voordelen? Ten tweede kwaliteit: is het antwoord duidelijk, goed georganiseerd en nuttig voor een specialist die beslissingen moet nemen? Ten derde richtlijnafstemming: komt het overeen met wat EULAR daadwerkelijk aanbeveelt, is het gedeeltelijk in overeenstemming maar onvolledig, of staat het in directe tegenstelling tot de richtlijnen? Het team controleerde ook hoe moeilijk de antwoorden waren om te lezen met standaard leesbaarheidstests die inschatten welk opleidingsniveau nodig is om een tekst te begrijpen.
ChatGPT vs. Gemini: wie deed het beter?
Beide chatbots leverden over het algemeen verstandige, goed geschreven antwoorden en beide herinnerden lezers vaak eraan een zorgprofessional te raadplegen. Maar er deden zich belangrijke verschillen voor. ChatGPT-4o kwam in 76% van de gevallen volledig overeen met de jichtrichtlijnen en gaf in nog eens 20% grotendeels juiste maar onvolledige antwoorden, met slechts één antwoord dat een duidelijke medische fout bevatte. Gemini was in 48% van de antwoorden volledig in overeenstemming en in 32% grotendeels correct maar onvolledig. Bezorgender waren de 12% van zijn antwoorden die juiste ideeën combineerden met onjuiste informatie en de 8% die de richtlijnen ronduit tegenspraken — bijvoorbeeld door breed gebruik van een krachtige klasse ontstekingsremmers (IL-1-remmers) voor te stellen terwijl EULAR deze voorbehoudt aan geselecteerde, moeilijk behandelbare patiënten, of door routinematig starten van urateremmende medicatie tijdens een acute aanval aan te bevelen, een gebied waar deskundigen juist tot meer voorzichtigheid oproepen.
Leesbaar, maar geen makkelijke leesstof
Wat stijl betreft waren de twee systemen verrassend vergelijkbaar. Op meerdere leestests produceerden beide teksten die minstens een universitair niveau vereisten om comfortabel te volgen. Dat kan acceptabel zijn voor specialistische artsen, maar is veel te complex voor de meeste patiënten. Geen van beide modellen gaf referenties of links naar bronnen tenzij daar specifiek om gevraagd werd, waardoor het moeilijk is te verifiëren waar de informatie vandaan kwam. De overeenstemming tussen de beoordelaars werd als goed tot uitstekend beoordeeld, wat suggereert dat de scoring consistent was en dat de verschillen tussen de chatbots reëel waren en geen kwestie van mening.
Wat dit betekent voor mensen met jicht
Samengevat suggereert de studie dat geavanceerde chatbots nuttige assistenten kunnen zijn voor artsen die jicht behandelen, maar dat ze nog niet zelfstandig kunnen opereren. ChatGPT-4o was betrouwbaarder, vollediger en trouwer aan de deskundige richtlijnen dan Gemini, maar zelfs zeldzame fouten kunnen van belang zijn wanneer medicatie en veiligheid in het geding zijn. Beide tools communiceerden op een niveau dat te complex is voor de meeste patiënten en misten ingebouwde transparantie over hun bronnen. Voorlopig stellen de auteurs dat AI gezien moet worden als een veelbelovend ondersteunend hulpmiddel dat clinici en onderwijsprofessionals kan helpen — maar alleen wanneer het advies wordt gecontroleerd aan de hand van actuele richtlijnen en deskundig oordeel, vooral bij aandoeningen zoals jicht waarbij kleine doseringsdetails en timingbeslissingen een groot verschil kunnen maken voor pijn, blijvende schade en kwaliteit van leven.
Bronvermelding: Meral, H.B., Kolak, E. Evaluation of ChatGPT-4o and Gemini for gout management: a comparative analysis based on EULAR guidelines. Sci Rep 16, 4831 (2026). https://doi.org/10.1038/s41598-026-35166-5
Trefwoorden: jicht, klinische richtlijnen, kunstmatige intelligentie, grote taalmodellen, reumatologie