Clear Sky Science · nl
Domein-adaptieve faster R-CNN voor identificatie van ontbrekende PBM op bouwplaatsen uit draagbare en algemene afbeeldingen
Waarom ontbrekende veiligheidsuitrusting toch voorbij glipt
Helmen, hesjes, maskers, handschoenen en stevige schoenen horen op bouwplaatsen onvoorwaardelijk te zijn, maar tekortkomingen komen toch voor—en ze kunnen dodelijk zijn. Veel projecten vertrouwen tegenwoordig op camera’s en kunstmatige intelligentie om werknemers te signaleren die verplichte uitrusting missen, maar deze systemen worstelen omdat echte overtredingen zeldzaam en moeilijk op beeld vast te leggen zijn. Deze studie onderzoekt een manier om slimmere detectiesystemen te trainen door voorbeelden uit gewone straatfoto’s te lenen, zodat geautomatiseerde veiligheidstoezicht betrouwbaarder wordt zonder te hoeven wachten tot er ongelukken of veel overtredingen plaatsvinden.
Alledaagse foto’s als veiligheidsles
Het kernidee is eenvoudig: mensen in openbare ruimtes of kantoren dragen zelden bouwuitrusting, dus foto’s uit die omgevingen zitten vol voorbeelden van "wat je niet op een bouwplaats moet dragen." De uitdaging is dat die scènes er heel anders uitzien dan echte bouwsituaties—achtergronden, verlichting en camerahoeken veranderen allemaal hoe mensen verschijnen. De auteur behandelt deze twee werelden als verschillende "domeinen": een source-domein met veel voorbeelden van ontbrekende PBM uit algemene afbeeldingen, en een target-domein met minder maar meer realistische bouwplaatsfoto’s, vaak gefilmd vanaf camera’s op helmen van werknemers. Het artikel toont aan dat door zorgvuldig af te stemmen wat de computer uit beide domeinen leert, het systeem ontbrekende uitrusting op echte locaties veel nauwkeuriger kan detecteren dan wanneer het alleen op bouwdata was getraind.
Hoe de nieuwe veiligheidschecker een scène ziet
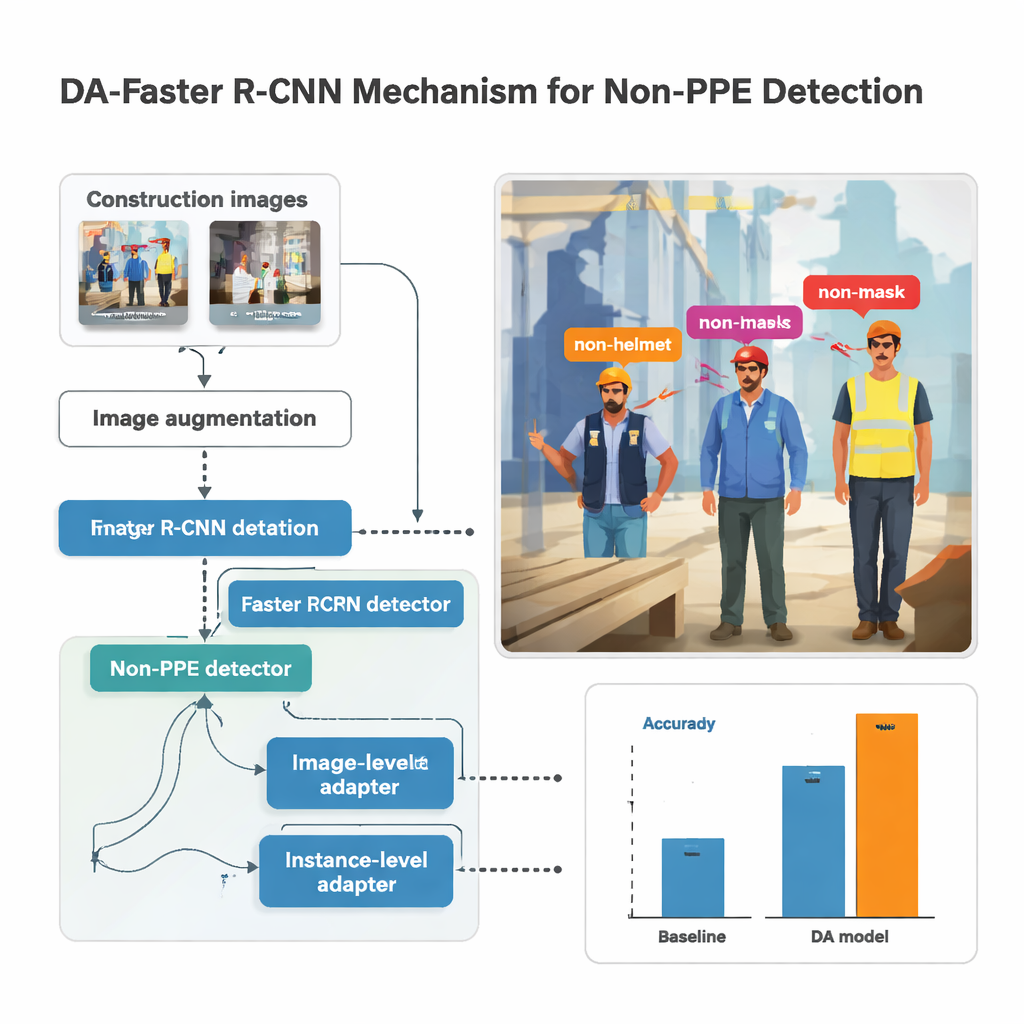
Het onderzoek bouwt voort op een populair objectdetectiesysteem genaamd Faster R‑CNN, dat een afbeelding scant, regio’s voorstelt die waarschijnlijk mensen of lichaamsdelen bevatten, en vervolgens classificeert wat het binnen elk vak ziet. Hier wordt de detector getraind om vijf soorten ontbrekende uitrusting te herkennen: geen helm, geen masker, geen handschoenen, geen hesje en geen veiligheidsschoenen. Voordat afbeeldingen aan het model worden gevoed, worden ze sterk geaugmenteerd—opgehelderd of verduisterd, gedraaid, vervaagd en vervormd—om onstabiele camera’s, fel zonlicht en ongemakkelijke hoeken na te bootsen die veel voorkomen op drukke bouwplaatsen. Deze synthetische variatie helpt het model stabiel te blijven wanneer de real-world beelden niet perfect zijn, zoals vaak het geval is bij opnamen van body‑cams.
Het systeem leren de achtergrond te negeren
Het eenvoudig mengen van straatfoto’s met bouwopnamen is niet voldoende; het model zou kunnen leren ontbrekende uitrusting te associëren met stadsstoepen in plaats van met mensen. Om dat te voorkomen introduceert de studie "domeinadaptatie"-modules die het systeem zachtjes dwingen zich te concentreren op mensen en kleding in plaats van op de omgeving. Eén module kijkt naar de afbeelding als geheel en stuurt het netwerk zodat bouw- en niet‑bouwfoto’s vergelijkbare algemene patronen opleveren, ondanks verschillende verlichting of apparatuur. Een andere module werkt op het niveau van elke gedetecteerde persoon en zorgt ervoor dat de visuele handtekening van bijvoorbeeld een onbeschermd hoofd er vergelijkbaar uitziet, of het nu op een steiger of in een winkelstraat verschijnt. Deze modules worden op een adversariële manier getraind: een kleine classifier probeert te raden uit welk domein een afbeelding komt, terwijl het hoofdnetwerk leert die informatie te verbergen en zijn focus op beschermende uitrusting te houden.
De methode op de proef stellen
De auteur stelde een omvangrijke dataset samen door body‑cambeelden van vijf bouwplaatsen in Zuid‑Korea te combineren met meerdere openbare beeldverzamelingen. Na handmatige labeling van elk geval van ontbrekende helmen, maskers, handschoenen, hesjes en veiligheidsschoenen trainde de studie honderden modellen met verschillende neurale‑netwerkbackbones en parameters. De beste presteerder gebruikte een diep netwerk genaamd ResNet‑152 samen met sterke beeldaugmentatie en de domeinadaptatiemodules. Op voorheen ongeziene bouwbeelden behaalde deze opstelling een mean Average Precision—een totaalscore voor detectiekwaliteit—van ongeveer 86,8 procent, terwijl het nog steeds ongeveer 33 frames per seconde draaide, snel genoeg voor bijna realtime monitoring. Vergeleken met meer conventionele supervised systemen verbeterde het aangepaste model de nauwkeurigheid met maximaal 14 procentpunt, en tot wel 39 punten ten opzichte van een eenvoudigere baseline.
Wat dit betekent voor veiligere locaties
Voor niet‑specialisten is de conclusie dat slimmer trainen, niet alleen grotere datasets, geautomatiseerd veiligheidstoezicht veel betrouwbaarder kan maken. Door te leren van zowel alledaagse foto’s als echte bouwplaatsen, en door het systeem onbelangrijke achtergronddetails te laten negeren, detecteert de voorgestelde aanpak met hoge betrouwbaarheid ontbrekende helmen, hesjes, handschoenen, maskers en veiligheidsschoenen, zelfs wanneer echte overtredingen schaars zijn. Hoewel het huidige werk zich richt op vijf soorten uitrusting en één hoofddataset van bouwplaatsen, biedt het een praktische blauwdruk voor toekomstige systemen die harnassen, lijnen en andere veiligheidsapparatuur op veel locaties zouden kunnen volgen, waardoor toezichthouders problemen vroeg kunnen opsporen en werknemers veiliger kunnen houden zonder de hele dag naar video’s te hoeven kijken.
Bronvermelding: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
Trefwoorden: bouwveiligheid, persoonlijke beschermingsmiddelen, computer vision, domeinadaptatie, objectdetectie