Clear Sky Science · nl
Compacte deep learning‑modellen voor colon‑histopathologie: focus op prestaties en generalisatieproblemen
Waarom dit onderzoek belangrijk is voor patiënten en artsen
Dikkedarmkanker behoort tot de dodelijkste vormen van kanker wereldwijd, maar de diagnose berust nog steeds op specialisten die weefselsnedes onder de microscoop zorgvuldig beoordelen—een taak die traag is en gevoelig voor meningsverschil. Deze studie onderzoekt of zeer kleine, efficiënte kunstmatige intelligentie (AI)‑modellen kunnen helpen om kankerverwekkend colonweefsel nauwkeurig genoeg te signaleren om in de dagelijkse klinische praktijk nuttig te zijn, ook in instellingen met beperkte rekenkracht. Tegelijkertijd onthult het een verborgen zwakte: modellen die tijdens ontwikkeling vrijwel perfect lijken, kunnen op nieuwe, realistische data alsnog ernstig falen.
Computers leren microscoopbeelden “lezen”
Wanneer een colonbiopsie wordt afgenomen, onderzoeken pathologen dunne, gekleurde weefselsnedes onder de microscoop. Kankerveranderingen tonen vervormde klieren, onregelmatige celvormen en invasie in omliggende structuren, terwijl gezond weefsel ordelijke, regelmatige patronen vertoont. De auteurs gebruikten een openbare verzameling van 24.000 digitale afbeeldingen van zulke snedes, gelijk verdeeld tussen kanker (colonadenocarcinoom) en goedaardig weefsel. Ze pasten alle afbeeldingen aan naar een standaard, klein formaat en voerden realistische variaties toe—kleine rotaties, spiegelen, inzoomen en subtiele kleurveranderingen—om de natuurlijke variatie in snijrichting, kleuring en scannen na te bootsen. Deze zorgvuldige voorbereiding helpt AI‑modellen focussen op betekenisvolle weefselpatronen in plaats van op oppervlakkige details zoals precieze oriëntatie of helderheid.
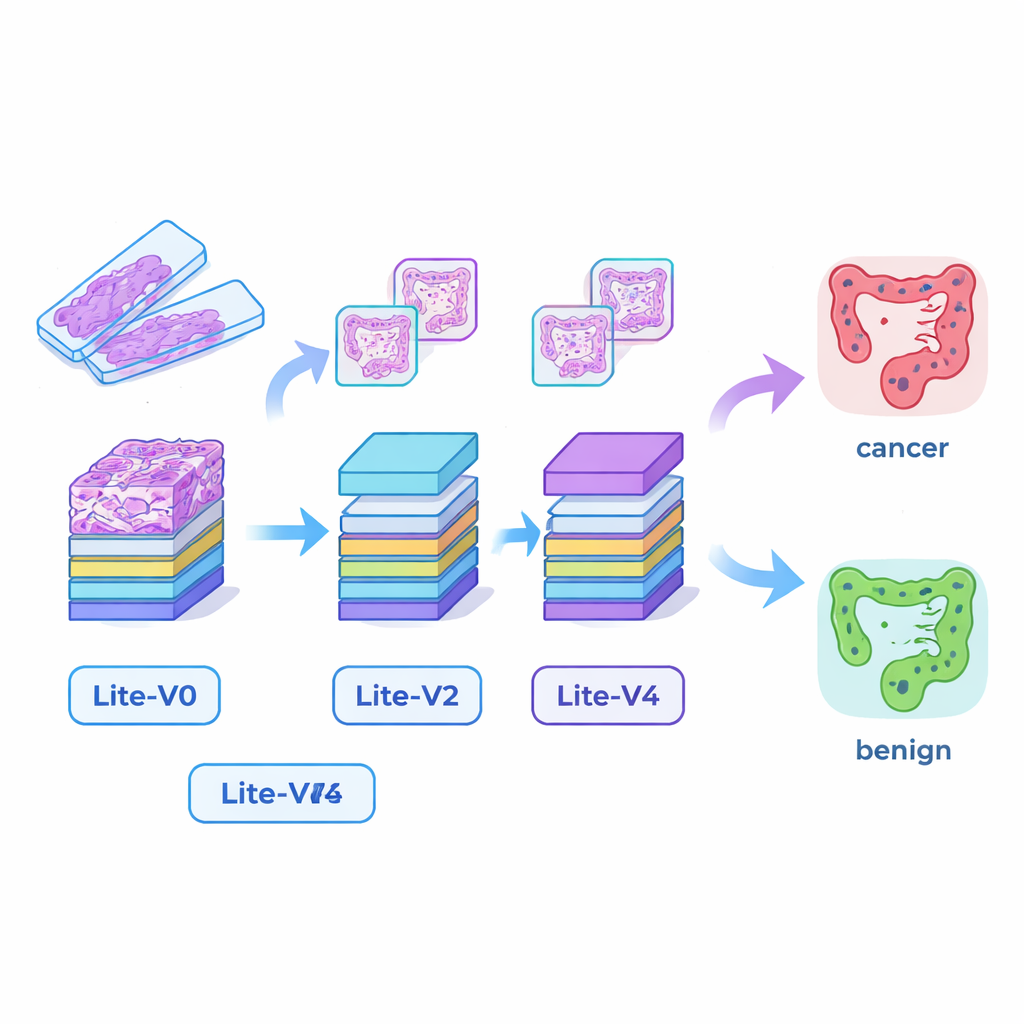
Kleine maar capabele AI‑“ogen” bouwen
Veel succesvolle medische AI‑systemen vertrouwen op zeer grote deep learning‑modellen die krachtige grafische kaarten en veel geheugen vereisen, waardoor ze moeilijk inzetbaar zijn in kleinere ziekenhuizen of aan het bed van de patiënt. Om die kloof te overbruggen ontwierpen de onderzoekers vier compacte convolutionele neurale netwerken—Lite‑V0, Lite‑V1, Lite‑V2 en Lite‑V4. Elk model bekijkt dezelfde invoerbeeldpatches, maar ze verschillen in hoeveel lagen en filters ze gebruiken om visuele kenmerken zoals randen, texturen en klierstructuren te detecteren. Alle vier delen een eenvoudige, transparante opzet: herhaalde blokken van standaardconvolutie, normalisatie en pooling, gevolgd door een kleine “beslissingskop” die de waarschijnlijkheid van kanker of goedaardig weefsel uitstuurt. Het doel was te onderzoeken hoeveel nauwkeurigheid je uit modellen kunt persen die klein genoeg zijn om comfortabel op eenvoudige klinische hardware te draaien.
Indrukwekkende scores in het lab
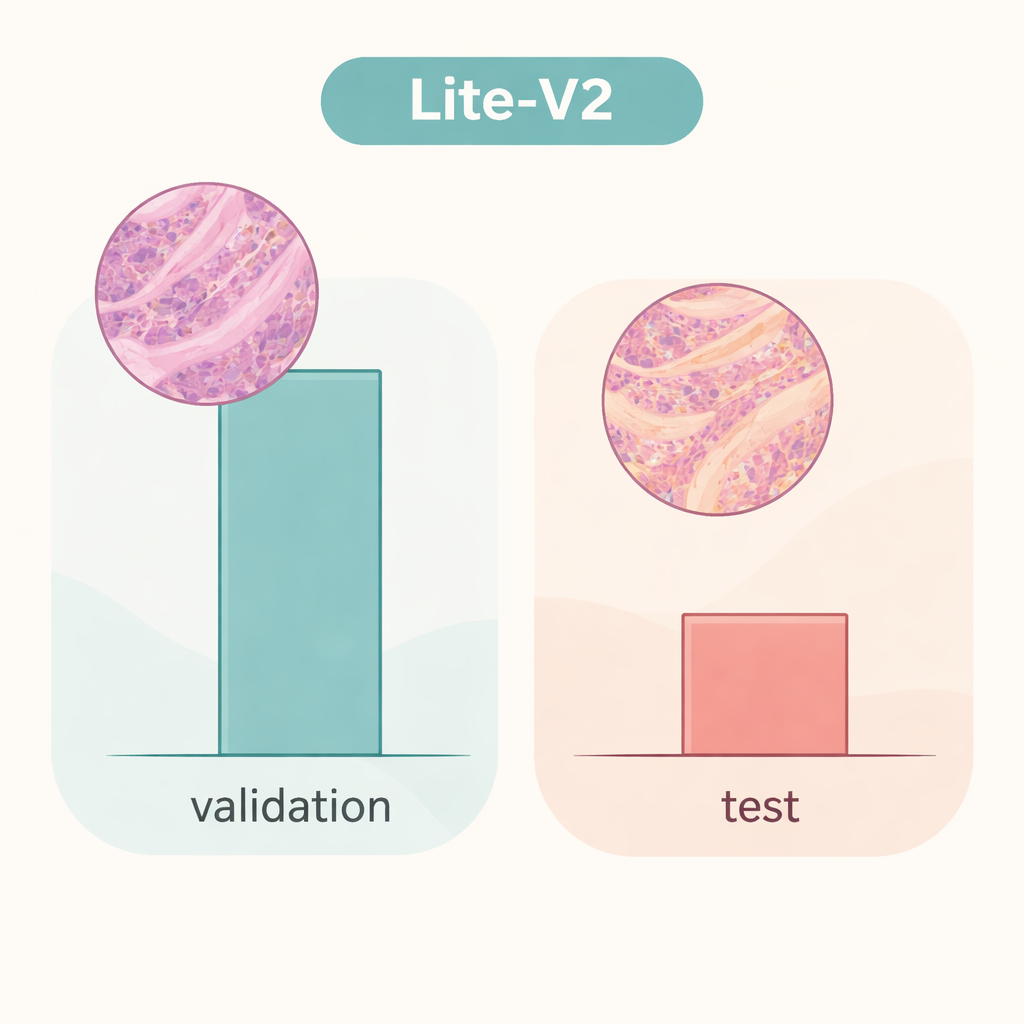
Het team trainde en vergeleek alle vier modellen op een vaste splitsing van de dataset, met algemeen aanvaarde maatstaven: nauwkeurigheid, een gebalanceerde F1‑score die fouten in beide klassen even zwaar weegt, verwarringsmatrices en diagnostische grafieken zoals ROC‑ en precisie‑recallcurves. Een middelgroot model, Lite‑V2, bleek de beste prestaties te leveren. Ondanks dat het slechts ongeveer 1,5 megabyte groot is en ongeveer 128.000 trainbare parameters heeft, behaalde het bijna foutloze resultaten op de interne validatieset, met een macro F1‑score rond 0,999 en vrijwel perfecte sensitiviteit en specificiteit. Met andere woorden: binnen deze zorgvuldig voorbereide omgeving kon Lite‑V2 vrijwel altijd kanker van goedaardig colonweefsel onderscheiden, terwijl het snel en licht genoeg bleef voor gebruik op bescheiden computers.
Wanneer real‑world variatie de betovering verbreekt
Het verhaal verandert echter dramatisch wanneer hetzelfde Lite‑V2‑model wordt getest op een onafhankelijke set afbeeldingen die subtiel verschillen op manieren die lijken op snedes uit een ander laboratorium—wat onderzoekers een “domeinverschuiving” noemen. Op deze ongeziene testset daalde de totale nauwkeurigheid naar ongeveer 50% en viel de gebalanceerde F1‑score terug naar ongeveer 0,33. Het model bleef veel kankervoorbeelden herkennen maar had grote moeite met goedaardig weefsel, dat vaak als kwaadaardig werd bestempeld. Dit laat zien dat het netwerk details had geleerd die sterk verbonden waren met de oorspronkelijke gegevensbron—zoals kleuringsstijl of scannerkenmerken—in plaats van robuuste, overdraagbare ziektekenmerken. Het werk benadrukt dat schitterende resultaten op interne validatie een vals gevoel van zekerheid kunnen geven als modellen niet worden getest met echt verschillende data.
Wat dit betekent voor toekomstige AI‑diagnosetools
Voor een algemeen publiek is de conclusie tweeledig. Ten eerste kunnen compacte AI‑systemen inderdaad prestaties op expertniveau behalen bij colonweefselbeelden en tegelijk klein en efficiënt genoeg zijn voor brede inzet, wat de deur opent naar snellere screening en ondersteuning van overbelaste pathologen. Ten tweede, en even belangrijk, een model dat op de thuisset “perfect” lijkt, kan ernstig falen wanneer het afbeeldingen van een nieuw ziekenhuis tegenkomt. De auteurs pleiten ervoor dat toekomstig werk zich moet richten op het robuust maken van deze lichtgewicht modellen tegen veranderingen in kleuring, scanners en patiëntenpopulaties—met strategieën zoals kleuring‑robuuste training, domeinaanpassing en grotere multicenterdatasets. Tot die tijd moet AI worden gezien als een veelbelovende assistent en niet als een autonoom beslissingsinstrument bij kankerdiagnose.
Bronvermelding: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
Trefwoorden: dikkedarmkanker, histopathologie, deep learning, lichtgewicht CNN, domeinverschuiving