Clear Sky Science · nl
Verbeterde diepe leer‑modellen met kennisgrafen voor het voorspellen van geneesmiddelengraad
Waarom slimmere geneesmiddelvoorspellingen ertoe doen
Ziekenhuizen, apotheken en patiënten zijn afhankelijk van het beschikbaar hebben van de juiste medicijnen op het juiste moment. Te weinig bestellen kan ertoe leiden dat levensreddende geneesmiddelen niet op voorraad zijn wanneer ze dringend nodig zijn. Te veel bestellen vult de schappen met producten die verlopen en geld verspillend. Het probleem is dat de vraag naar medicijnen schommelt door griepseizoenen, nieuwe uitbraken, veranderende richtlijnen en de manier waarop artsen middelen vervangen of combineren. Dit artikel presenteert een nieuwe methode om de vraag naar medicijnen te voorspellen die zowel geavanceerde kunstmatige intelligentie als gestructureerde medische kennis benut om zorgketens betrouwbaarder en efficiënter te maken.
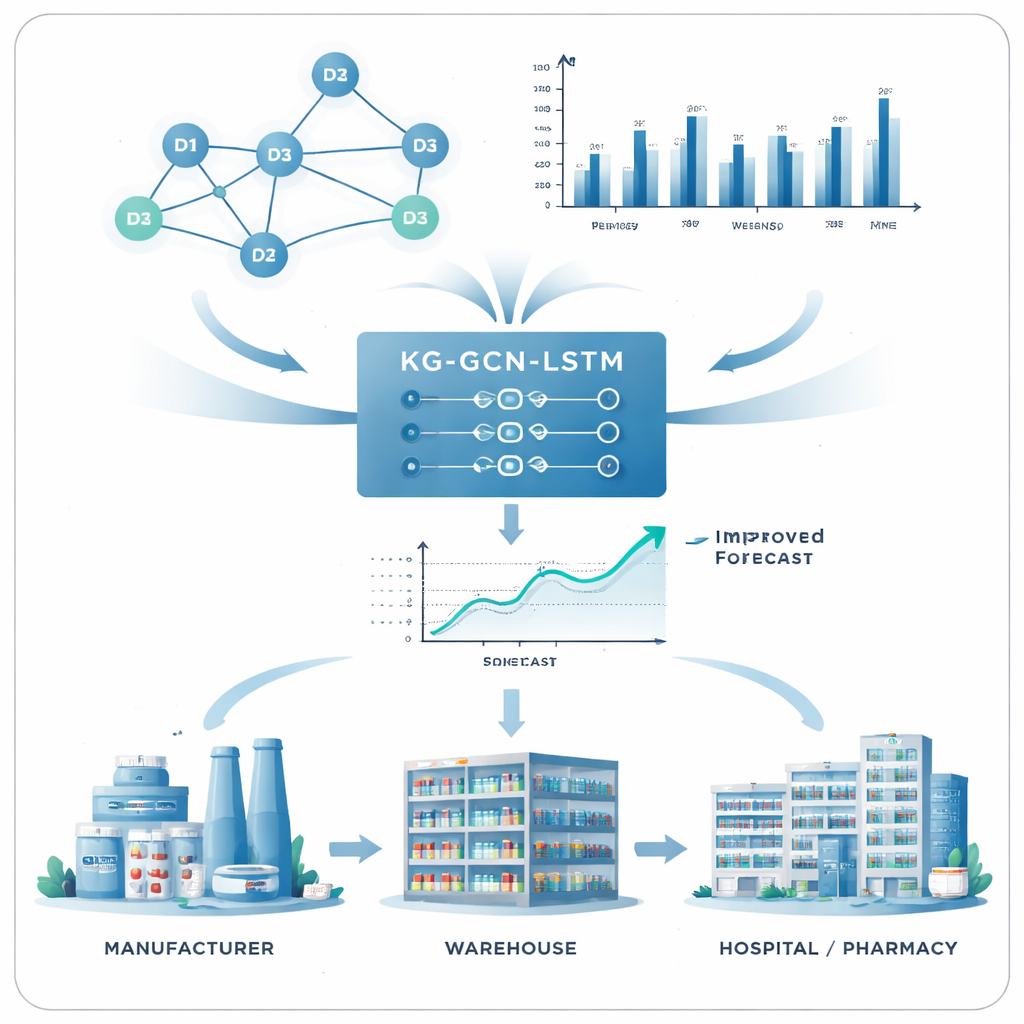
Beperkingen van de huidige voorspellingsinstrumenten
Veel ziekenhuizen en leveranciers vertrouwen nog steeds op traditionele statistische modellen die ervan uitgaan dat de vraag relatief gladde, voorspelbare trends volgt. Deze methoden behandelen elk geneesmiddel alsof het in zijn eigen wereld leeft en negeren hoe het ene middel het andere kan vervangen of aanvullen. Nieuwere machine‑learning en deep‑learning modellen, zoals neurale netwerken, kunnen beter omgaan met pieken en dalen in tijdreeksgegevens, maar ook zij richten zich meestal alleen op historische verkoopcijfers. Daardoor missen ze vaak een belangrijk deel van het verhaal: hoe artsen werkelijk kiezen tussen verschillende geneesmiddelen bij de behandeling van dezelfde aandoening, vooral wanneer er substituten of veelvoorkomende combinaties zijn.
Een kaart toevoegen van hoe geneesmiddelen zich verhouden
De auteurs pakken dit probleem aan door een “kennisgraaf” voor farmaceutica te bouwen — een soort kaart die geneesmiddelen, symptomen en ziekten met elkaar verbindt. In deze graaf stelt elke knoop een geneesmiddel of symptoom voor, en elke verbinding een reële relatie, zoals dat het ene antibioticum het andere kan vervangen, of dat een vitamine vaak samen met een verkoudheidsmiddel wordt voorgeschreven. Door de voorspelling te funderen in deze gestructureerde kaart kan het model zien dat als de vraag naar het ene middel stijgt of daalt, de vraag naar nauwe substituten of typische partners ook kan veranderen. Dit verandert verspreide verkoopgegevens in een verbonden beeld van hoe behandelingen in de praktijk op elkaar inwerken.
Hoe het hybride AI‑model werkt
Om deze kaart en de verkoopgeschiedenis om te zetten in voorspellingen, stelt de studie een hybride model voor genaamd KG‑GCN‑LSTM. Eerst stroomt informatie via een graph convolutional network (GCN) langs de verbindingen van de kennisgraaf, zodat de representatie van elk geneesmiddel niet alleen zijn eigen geschiedenis weerspiegelt maar ook het gedrag van verwante geneesmiddelen. Een speciale “clipping”-stap richt het model vervolgens weer op het doelmedicijn, waardoor ruis van minder relevante buren wordt verminderd. Daarna verwerkt een long short‑term memory‑netwerk (LSTM) — een type recurrent neuraal netwerk ontworpen voor reeksen — de verrijkte wekelijkse vraaggegevens om patronen in de tijd te leren, zoals seizoensinvloeden, geleidelijke groei en plotselinge pieken. Ten slotte zet een eenvoudige uitvoerlaag deze aangeleerde patronen om in voorspellingen van de toekomstige vraag.
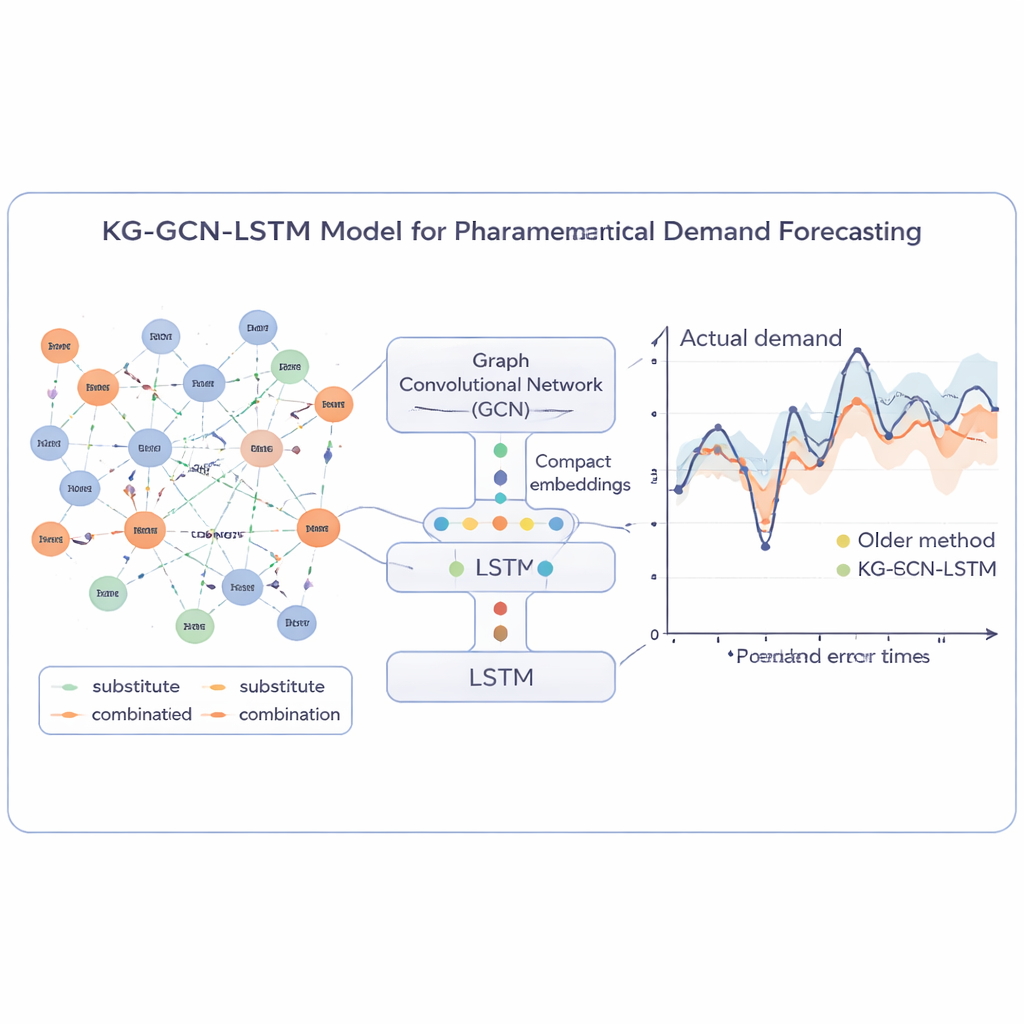
Praktische tests in een drukke apotheek
De onderzoekers testten hun benadering op meer dan een half miljoen verkooprecords van een Indonesische apotheek, met meer dan 200 producten. Ze schonen en aggregeerden de gegevens naar wekelijkse vraag, filterden artikelen met zeer korte geschiedenis eruit en construeerden de kennisgraaf met behulp van internationale geneesmiddeldocumentatie en bekende medicijn‑medicijninteracties. Het nieuwe model werd vervolgens vergeleken met een breed scala aan gevestigde technieken, van klassieke ARIMA en support vector regression tot moderne deep‑learning systemen zoals CNN‑LSTM, N‑BEATS en TimeMixer. Over verschillende standaard foutmaten leverde het kennisverrijkte model de meest nauwkeurige voorspellingen, met een vermindering van de relatieve fout met ongeveer 3,6 procentpunt vergeleken met een sterke deep‑learning baseline, en het evenaarde de prestaties van de nieuwste TimeMixer‑aanpak terwijl het beter interpreteerbaar was en geschikter voor geneesmiddelen met beperkte geschiedenis.
Wat dit betekent voor patiënten en zorgverleners
Voor niet‑specialisten is de kernboodschap eenvoudig: wanneer voorspellingsinstrumenten niet alleen begrijpen “hoeveel van elk geneesmiddel is verkocht” maar ook “hoe geneesmiddelen zich tot elkaar verhouden in reëel medisch gebruik”, kunnen ze toekomstige behoeften beter inschatten. Het KG‑GCN‑LSTM‑model laat zien dat het verweven van domeinkennis met AI kan helpen tekorten en overmatige voorraden te verminderen, waardoor apotheken essentiële medicijnen op voorraad kunnen houden zonder onnodig kapitaal te binden. Hoewel het bouwen en onderhouden van hoogwaardige kennisgrafen inspanning vergt, wijst deze studie op een toekomst waarin slimmere, kennisbewuste algoritmen stilletjes zorgen voor veerkrachtigere en kosteneffectievere zorgketens.
Bronvermelding: Chen, X., Lu, G., Zhang, H. et al. Knowledge graph-enhanced deep learning for pharmaceutical demand forecasting. Sci Rep 16, 4776 (2026). https://doi.org/10.1038/s41598-026-35113-4
Trefwoorden: voorspellen van medicijnvraag, zorgketen, kennisgraaf, graph neural networks, tijdreeksvoorspelling