Clear Sky Science · nl
Voorspelling van wortel-geassocieerde eiwitten met een eiwit-groottaalmodel en hypergraaf-convolutionele netwerken
Waarom wortels en hun verborgen helpers ertoe doen
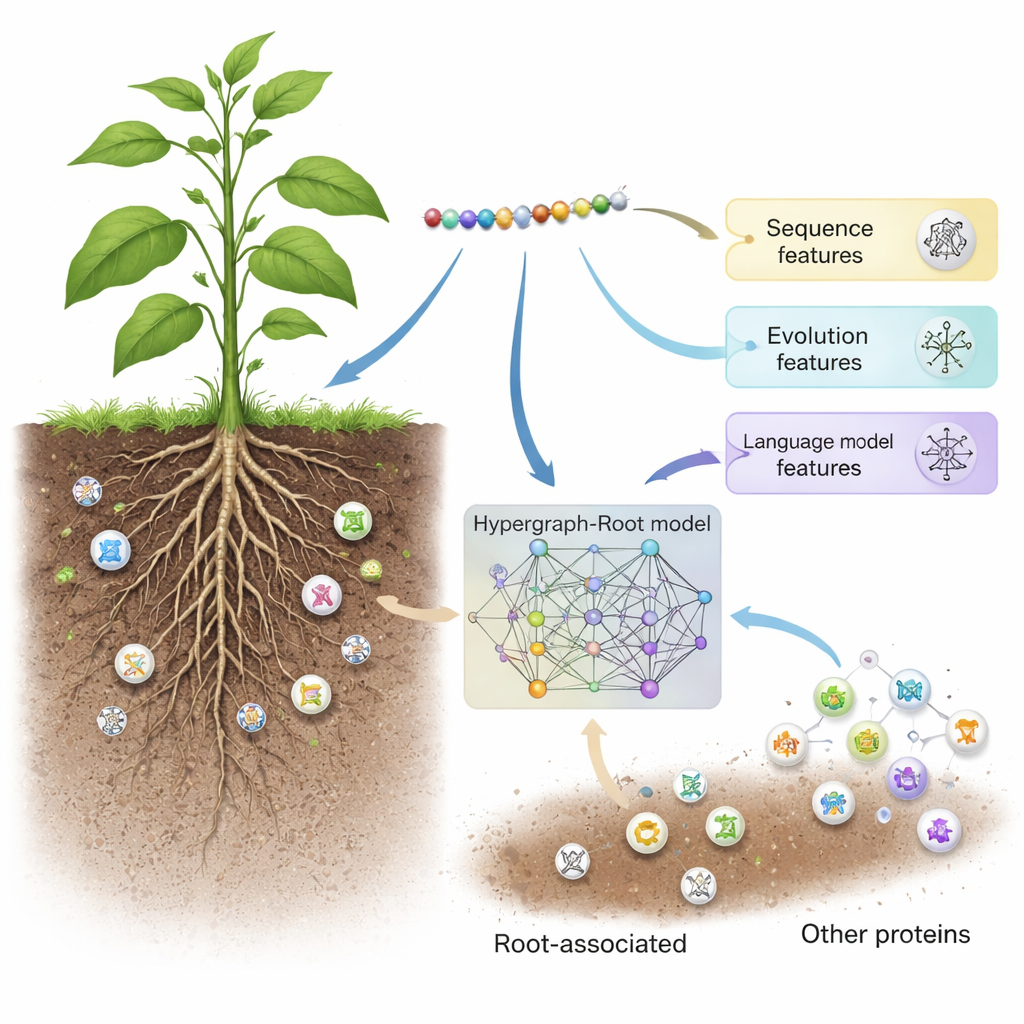
Als we denken aan het gezond houden van gewassen, denken we meestal aan bladeren en vruchten. Maar veel van het succes van een plant speelt zich buiten zicht af, in de bodem. Daar helpen speciale wortel-geassocieerde eiwitten planten water en voedingsstoffen op te nemen en om te gaan met stressfactoren zoals droogte of arme grond. Het vinden van deze cruciale eiwitten met alleen laboratoriumexperimenten is traag en duur. Deze studie introduceert een krachtig computermodel, Hypergraph-Root genoemd, dat snel eiwitsequenties kan scannen en voorspellen welke waarschijnlijk wortel-geassocieerd zijn, en zo een snellere route biedt naar hardere gewassen en betere oogsten.
Verborgen werkpaarden in de bodem
Plantwortels doen meer dan een plant vastzetten. Ze voelen voortdurend hun omgeving, nemen mineralen op en communiceren met bodemmicroben. Wortel-geassocieerde eiwitten staan centraal in dit alles: ze bepalen hoe wortels groeien, hoe ze reageren op hitte, droogte of voedingsstoffentekorten, en hoe ze omgaan met behulpzame microben. Omdat deze eiwitten sterk van invloed zijn op opbrengst en veerkracht, zijn ze belangrijk voor telers en veredelaars, ook al zien ze ze nooit direct. Toch blijven veel van zulke eiwitten onontdekt, grotendeels omdat traditionele methoden—zoals proteomics en genexpressiestudies—kostbare instrumenten, complexe analyses en nauwgezette experimenten vereisen.
Van eiwitsequenties naar aanwijzingen
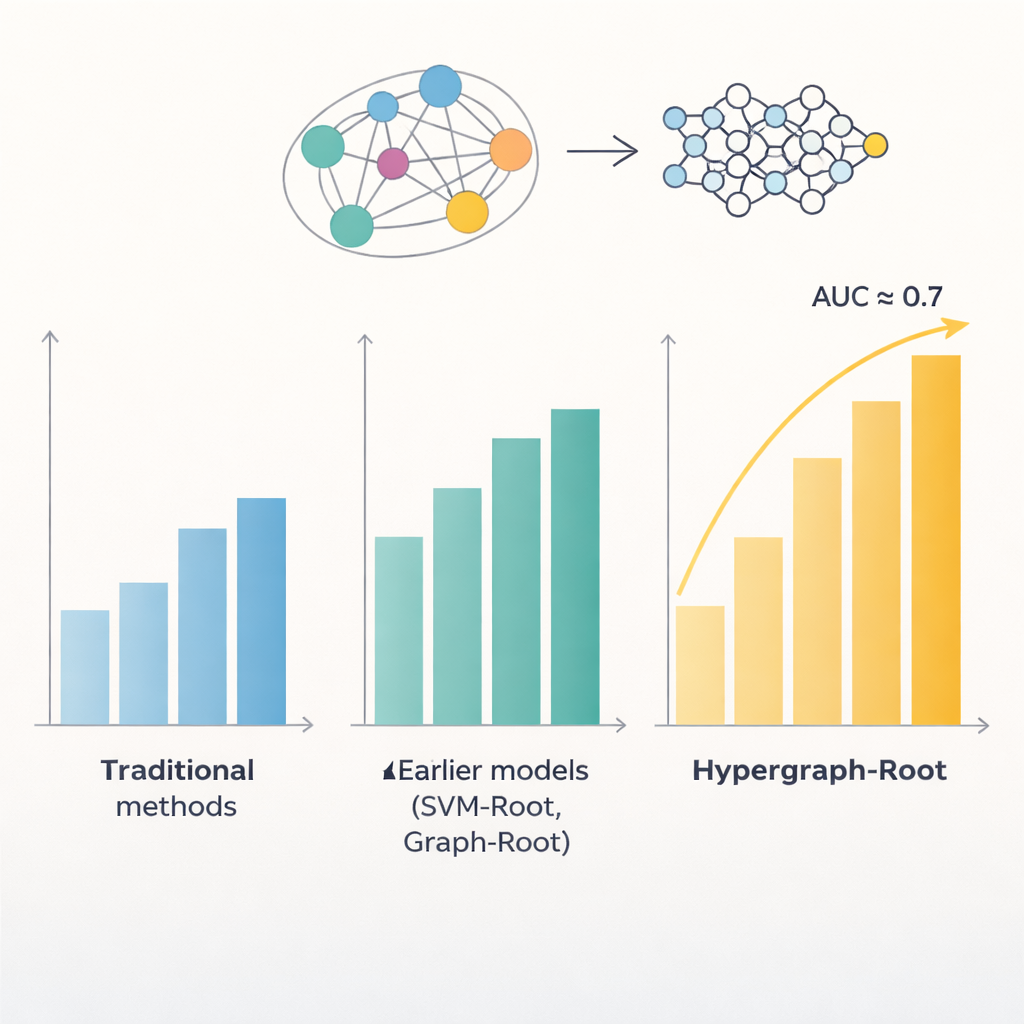
Eiwitten zijn opgebouwd uit reeksen aminozuren, en patronen in die reeksen onthullen vaak waar een eiwit in de plant werkt en wat het doet. Eerdere computermodellen probeerden deze patronen te gebruiken om wortel-geassocieerde eiwitten te herkennen, maar zij haalden accuratessepercentages onder de 80 procent. Eén probleem was dat ze de relaties tussen aminozuren vrij eenvoudig behandelden, meestal als paren. Een ander was dat ze vertrouwden op beperkte soorten kenmerken die uit sequenties werden gehaald. De auteurs redeneerden dat rijkere representaties van elk eiwit, samen met slimere manieren om aminozuurrelaties te modelleren, subtielere patronen gerelateerd aan wortelfuncties zouden kunnen onthullen.
Trucs lenen uit taal en netwerken
Hypergraph-Root begint met het beschrijven van elk eiwit op drie complementaire manieren. Het gebruikt traditionele sequentiescoreschema's (BLOSUM62 en position-specific scoring matrices) die vastleggen hoe aminozuren elkaar over evolutie heen vervangen. Vervolgens voegt het een derde, modernere beschrijving toe van een eiwit-taalmodel genaamd ProtT5—software getraind op miljoenen eiwitsequenties, vergelijkbaar met hoe een tekstvoorspellingsmodel op menselijke taal wordt getraind. ProtT5 levert een rijke numerieke “embedding” voor elk aminozuur die structurele en functionele aanwijzingen codeert. Samen geven deze drie zichten een gedetailleerd vingerafdruk van elk eiwit in de studie.
Complexe verbindingen binnen eiwitten in kaart brengen
Om verder te gaan dan eenvoudige paargewijze vergelijkingen voorspelden de onderzoekers hoe dicht aminozuren bij elkaar liggen in de 3D-structuur van een eiwit en gebruikten die informatie om een hypergraaf te bouwen—een netwerk waarin één verbinding meer dan twee aminozuren tegelijk kan koppelen. Een gespecialiseerd neuraal netwerk, het hypergraaf-convolutionele netwerk, verwerkt dit structuurbewuste netwerk en verfijnt de eiwitvingerafdrukken tot hoger-niveaufuncties. Een multi-head attention-module leert vervolgens welke delen van het eiwit de meest bruikbare signalen bevatten om te beslissen of het wortel-geassocieerd is. Ten slotte zet een standaard classifier deze gedistilleerde kenmerken om in een waarschijnlijkheidsscore: wortel-geassocieerd of niet. Over veel trainingsruns en zowel gebalanceerde als ongebalanceerde testsets behaalde Hypergraph-Root accuratesse boven 83 procent en een area under the ROC curve (AUC) rond 0,9, waarmee het duidelijk beter presteerde dan eerdere modellen.
Wat het model onthult en waarom dat belangrijk is
Naast ruwe nauwkeurigheid leverde het model inzichten over welke informatie het meest telt. Kenmerken uit het ProtT5-taalmodel droegen meer bij dan traditionele sequentie- en evolutionaire kenmerken, wat suggereert dat grote, vooraf getrainde modellen subtiele biologische signalen kunnen vastleggen die oudere methoden missen. Het hypergraafcomponent bleek ook belangrijk: het verwijderen ervan of het vervangen door een eenvoudiger grafmodel verminderde de prestatie. Toen de onderzoekers Hypergraph-Root toepasten op eiwitten die eerder niet als wortel-geassocieerd waren gelabeld, belichtte het een handvol waarvan de bekende functies—zoals membraantransport en eiwitlabeling in wortels—sterk suggereren dat ze een rol spelen in wortelbiologie. Deze kandidaten geven experimentele biologen nu duidelijke shortlists om in het lab te testen.
Van slimme voorspellingen naar sterkere gewassen
In alledaagse termen is Hypergraph-Root als een deskundige bibliothecaris voor plantenbiologie: alleen gegeven de “letters” van een eiwit, schat het in of dat eiwit waarschijnlijk in de wortels werkt. Door inzichten uit taalmodellen, evolutionaire geschiedenis en complexe structurele relaties te combineren, verbetert het sterk ten opzichte van eerdere voorspellingshulpmiddelen. Hoewel het experimenten niet vervangt, kan het duizenden mogelijkheden terugbrengen tot een beheersbaar aantal, wat tijd en geld bespaart. Op de lange termijn kunnen zulke modellen de ontdekking van wortel-geassocieerde eiwitten versnellen die gewassen helpen overleven bij hitte, droogte of arme bodems—een belangrijke stap naar veerkrachtigere landbouw in een veranderend klimaat.
Bronvermelding: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Trefwoorden: wortel-geassocieerde eiwitten, plantenbio-informatica, deep learning, eiwit-taalmodellen, gewasbestendigheid