Clear Sky Science · nl
Een multimodale leer- en simulatiebenadering voor perceptie in autonome rijsystemen
Slimmere zelfrijdende auto’s
Zelfrijdende auto’s beloven veiligere wegen en minder files, maar alleen als ze de wereld om hen heen echt kunnen begrijpen. Dit artikel verkent een nieuwe manier om autonome voertuigen te helpen “zien”, “voelen” en hun omgeving te “anticiperen” meer als een aandachtige menselijke bestuurder—door verschillende sensoren te combineren, veilig te testen in een virtuele kopie van de echte wereld en de beslissingen van de auto voor mensen beter inzichtelijk te maken.
De weg zien met meerdere “zintuigen”
De meeste rijhulpsystemen leunen vandaag sterk op camera’s, die goed werken bij goed licht maar moeite hebben bij mist, regen of ’s nachts. Deze studie combineert drie verschillende sensortypen—camera’s, laserscanners (LiDAR) en radar—zodat de auto niet afhankelijk is van één kwetsbare informatiebron. Camera’s leggen rijke kleur en detail vast, LiDAR bouwt een nauwkeurige 3D-weergave van de scène en radar blijft betrouwbaar bij slecht weer. De auteurs fuseren alle drie de stromen tot één beeld van het verkeer, waardoor het voertuig een vollediger en betrouwbaarder beeld krijgt van wegen, voetgangers en andere auto’s.
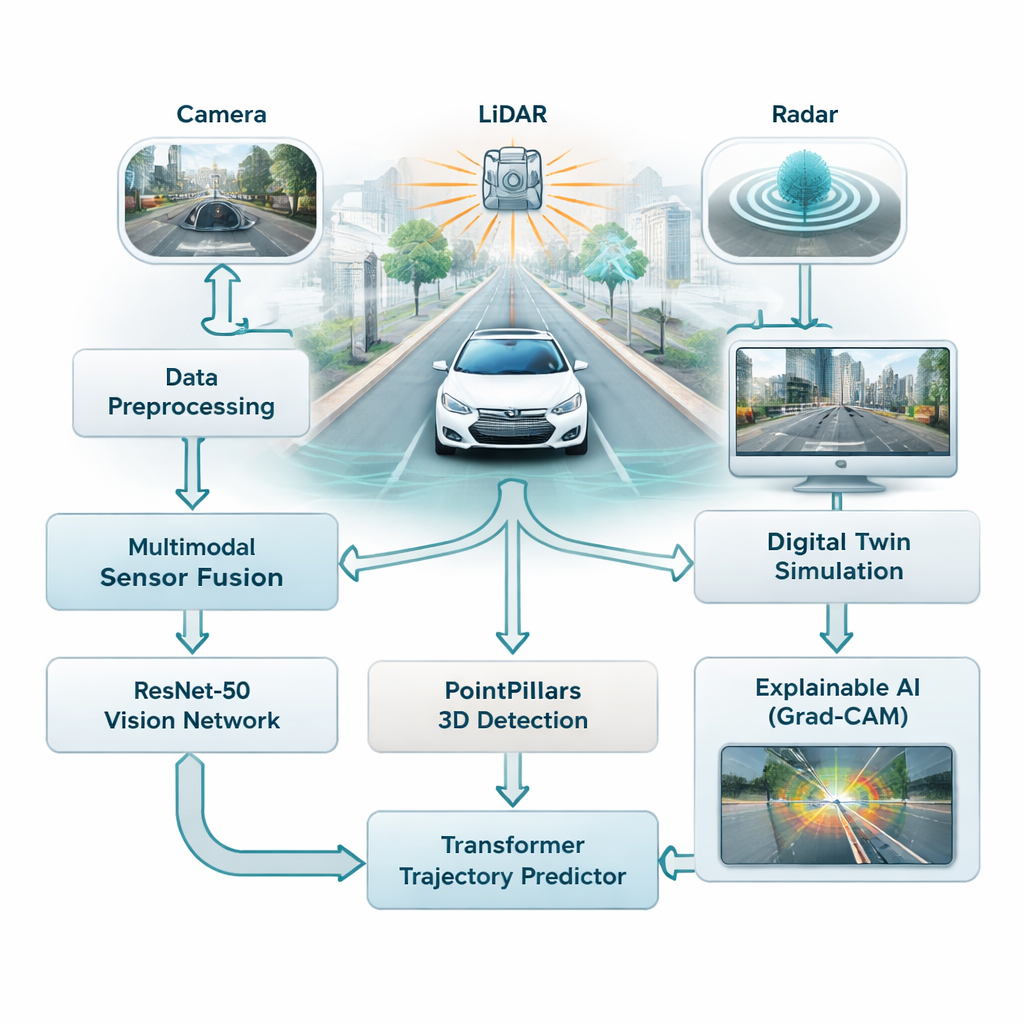
De auto leren herkennen en anticiperen
Om dit datavolume te begrijpen, gebruikt het raamwerk twee families moderne AI-modellen. Ten eerste scant een diepe afbeeldingsnetwerk genaamd ResNet-50 camerabeelden om de algemene situatie vast te leggen—hoe druk de weg is, waar rijstroken zichtbaar zijn en hoe de scène is opgebouwd. Tegelijkertijd leest een 3D-model genaamd PointPillars LiDAR-puntenwolken om voertuigen en andere objecten in drie dimensies te lokaliseren. Deze signalen worden vervolgens gevoed in een Transformer, een type AI dat oorspronkelijk voor taal is ontworpen en uitblinkt in het begrijpen van hoe dingen in de tijd veranderen. Hier leert het te voorspellen hoe nabijgelegen auto’s en andere bewegende objecten zich over de komende seconden waarschijnlijk zullen verplaatsen, waarbij zowel hun eerdere beweging als de structuur van de weg in aanmerking worden genomen.
Een veilige virtuele testbaan opbouwen
In plaats van risicovolle situaties direct op openbare wegen te testen, koppelen de onderzoekers hun systeem aan een digitale tweeling—een virtuele replica van echte stadsstraten gebaseerd op een grote openbare dataset uit Boston en Singapore. In deze gesimuleerde wereld worden de sensoren, bewegingen en omgeving van de auto afgespeeld en naar wens aangepast, terwijl de AI probeert objecten te volgen en hun toekomstige paden te voorspellen. Het systeem kan deze “wat als?”-scenario’s in realtime uitvoeren, met reactietijden onder 50 milliseconden, waardoor ingenieurs randgevallen kunnen onderzoeken zoals plots remmen, scherpe bochten of drukke kruispunten zonder iemand in gevaar te brengen.
Een kijkje in de “zwarte doos” van de AI
Een veelgehoorde kritiek op deep learning is dat het moeilijk kan zijn te begrijpen waarom het model een bepaalde beslissing nam. Om dit aan te pakken gebruiken de auteurs een methode genaamd Grad-CAM, die de delen van een afbeelding benadrukt die de uitvoer van het model het meest beïnvloedden. Deze warmtekaarten tonen bijvoorbeeld of het netwerk zich concentreert op een andere auto, een voetganger of een wegbelijning bij het inschatten van trajecten. Hoewel deze verklaringsstap offline draait en niet in de realtime-lus van de auto, helpt het ingenieurs en veiligheidsevaluatoren te verifiëren dat het systeem op de juiste aanwijzingen let, wat cruciaal is voor het opbouwen van vertrouwen bij het publiek.
Hoeveel beter rijdt het?
Getest op honderden stedelijke rijsituaties detecteert het voorgestelde raamwerk 3D-objecten nauwkeurig en voorspelt het beweging preciezer dan eenvoudige fysicaregels die constante snelheid of constante versnelling veronderstellen. De voorspellingsfouten—hoe ver de voorspelde posities afwijken van de werkelijkheid—zijn significant kleiner dan die van dergelijke baselines en liggen dicht bij een sterk recurrent AI-model, terwijl het toch snel genoeg draait voor realtime gebruik. Zorgvuldige experimenten die verschillende netwerkontwerpen vergelijken tonen dat een dieper afbeeldingsmodel en een detector van middeldiepte de beste balans tussen nauwkeurigheid en snelheid bieden, en dat het systeem na modelcompressie op kleinere boordcomputers kan worden ingezet.
Wat dit betekent voor alledaagse bestuurders
Voor niet-specialisten is de boodschap dat veiligere, betrouwbaardere zelfrijdende auto’s waarschijnlijk voortkomen uit een aanpak die meerdere sensoren combineert, voorspelt hoe de scène zal evolueren en grondig wordt getest in realistische virtuele werelden. Door perceptie, voorspelling, simulatie en voor mensen begrijpelijke verklaringen in één ontwerp samen te brengen, brengt dit werk autonome voertuigen dichter bij het gedrag van voorzichtige, transparante partners op de weg in plaats van mysterieuze machines.
Bronvermelding: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
Trefwoorden: autonoom rijden, sensorfusie, baanvoorspelling, 3D-objectdetectie, digitale tweelingsimulatie