Clear Sky Science · nl
Een hybride intelligent beoordelingsmodel voor Engels vertaalonderwijs met verbeterde BERT en SVM
Waarom slimmer beoordelen van vertalingen ertoe doet
Jaarlijks besteden taaldocenten talloze uren aan het nakijken van vertalingen van studenten. Bepalen of een zin “goed genoeg” is, is traag, subjectief en kan sterk verschillen per docent. Dit artikel onderzoekt of kunstmatige intelligentie die last kan verlichten—door snelle, consistente scores en aanwijzingen over wat er misging te bieden—zonder de docent te vervangen. Het presenteert een nieuw computermodel, genaamd BERT-SVM EduScore, speciaal ontwikkeld om de kwaliteit van Engelse vertalingen in een educatieve context te beoordelen.
Van ruwe woordvergelijking naar dieper begrip
Decennialang beoordeelden computers vertalingen vooral door te tellen hoeveel woorden of korte zinnen overeenkomen met een referentieantwoord. Bekende hulpmiddelen zoals BLEU of METEOR doen dit zeer snel, maar ze hebben moeite met de flexibiliteit van natuurlijke taal: twee zinnen kunnen dezelfde betekenis hebben met heel verschillende formuleringen. In de klas, waar studenten experimenteren met synoniemen en gevarieerde zinsstructuren, kunnen deze ouderwetse metrics geldige parafrasen onterecht bestraffen en weinig aanwijzingen geven over specifieke fouten. Onderzoekers zijn daarom overgestapt op nieuwere methoden die betekenissen vergelijken in plaats van oppervlakkige woorden, gebruikmakend van krachtige taalmodellen die op enorme tekstverzamelingen zijn getraind.
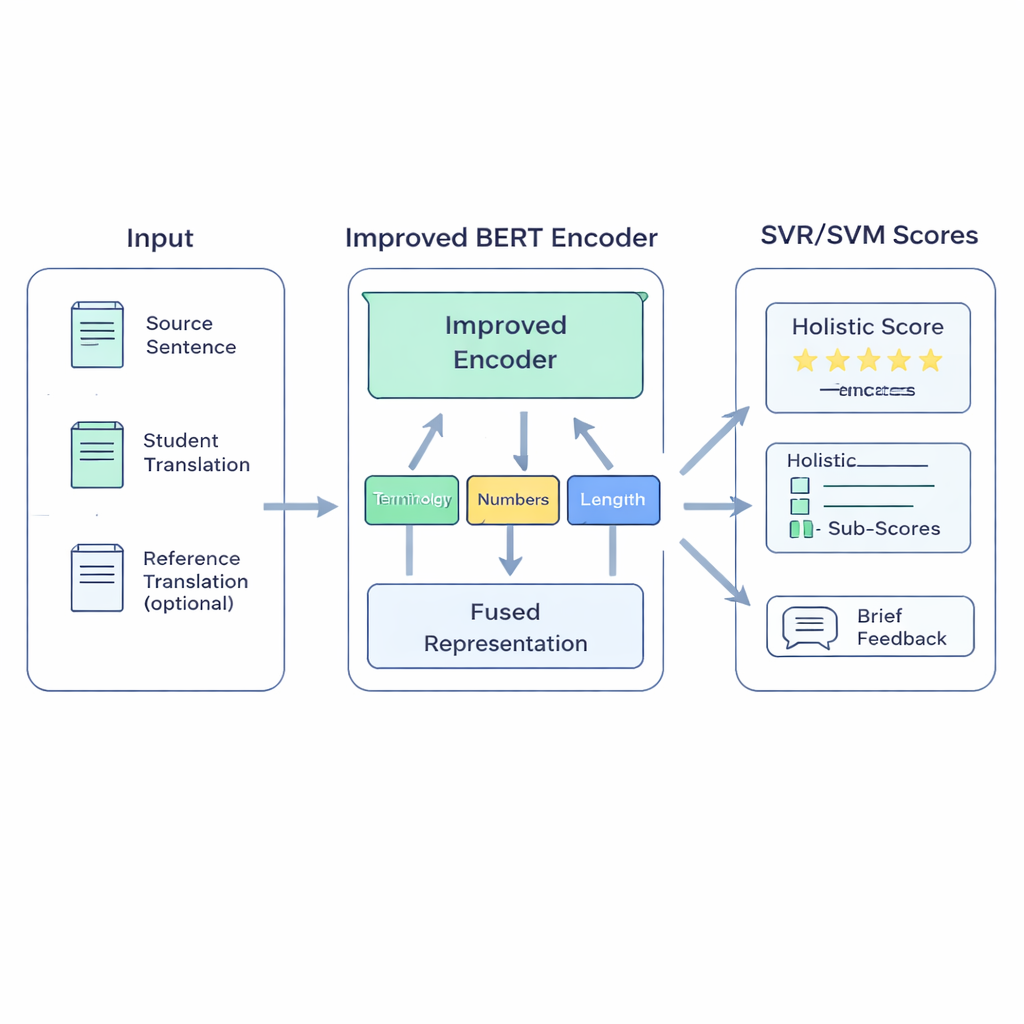
Een hybride model gebouwd voor de klas
Het voorgestelde BERT-SVM EduScore-systeem combineert twee ideeën: diep taalkundig begrip en klassieke, robuuste statistiek. Allereerst gebruikt het een verbeterde versie van het BERT-taalmodel om drie tekststukken te lezen: de oorspronkelijke zin, de vertaling van de student en, indien beschikbaar, een referentievertaling. BERT zet deze om in een rijke numerieke samenvatting die niet alleen laat zien welke woorden aanwezig zijn, maar ook hoe goed de betekenissen op elkaar aansluiten. Daarnaast voegt het systeem een kleine set handmatige controles toe waar docenten om geven—zoals of technische termen consistent zijn vertaald, of getallen en eenheden behouden zijn gebleven, of de interpunctie logisch is en of de lengte van de vertaling overeenkomt met het origineel.
Hoe het systeem leert te scoren als een docent
Deze signalen worden vervolgens gevoed aan Support Vector Machines, een familie algoritmen die bekendstaat om goed te werken met beperkte data. Het ene deel voorspelt een totaalscore; andere delen kunnen afzonderlijke scores geven voor aspecten zoals juistheid of vloeiendheid, of vertalingen indelen in kwaliteitsklassen. Om het model aan te laten sluiten op klaslokaaltaal, hertrainen de auteurs eerst BERT op teksten die lijken op studentenwerk—een aanpak die domeinadaptatie wordt genoemd. Ze scherpen verder BERTs gevoel voor overeenkomst en verschil door het te laten oefenen in het onderscheiden van goede en licht bewerkte slechte versies van zinnen. Ten slotte, wanneer hoogwaardige automatische metrics zoals COMET of BLEURT beschikbaar zijn, leert het systeem sommige van hun oordelen na te bootsen, waarbij het hun sterke punten overneemt terwijl het afgestemd blijft op menselijke beoordelingen.
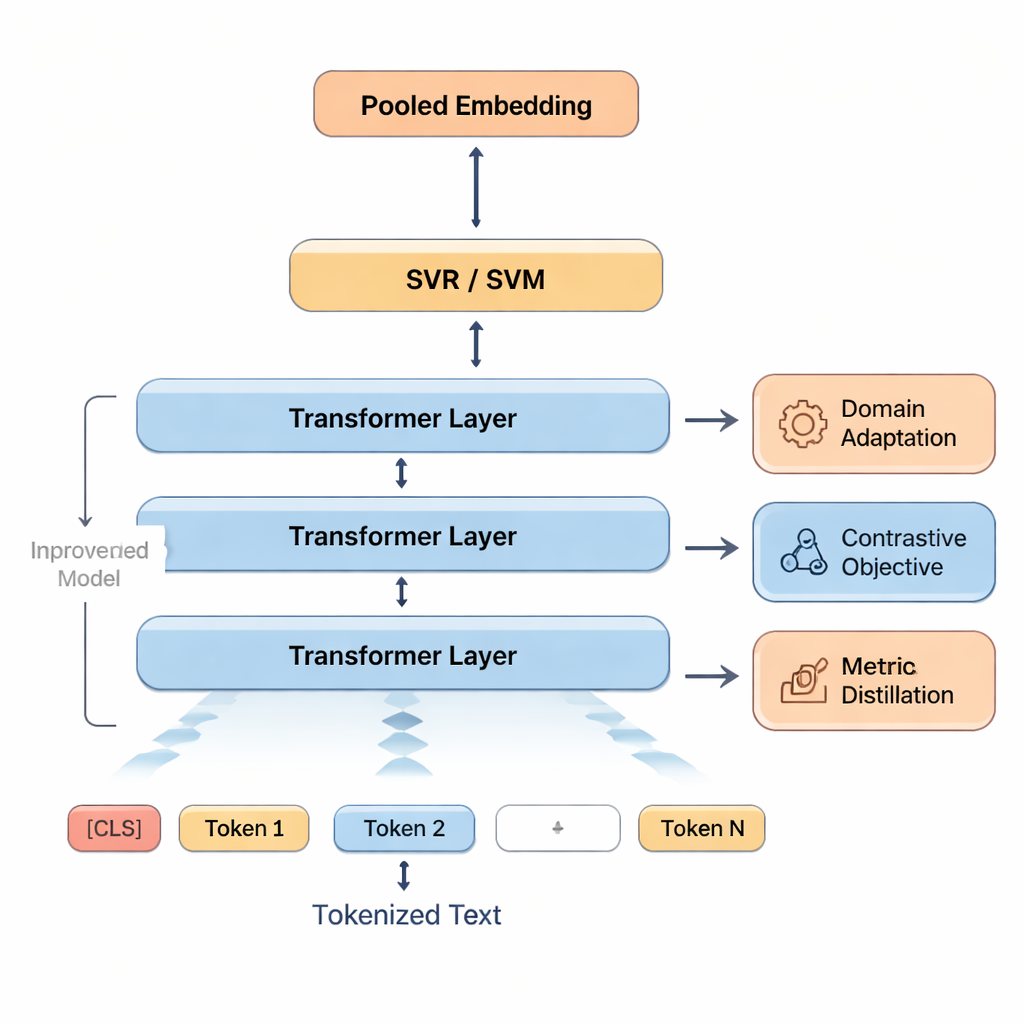
Het model op de proef gesteld
De onderzoekers evalueren BERT-SVM EduScore op een grote publieke dataset met Engels–Chinese machinevertalingen die door mensen zijn beoordeeld. Hoewel dit geen huiswerkopdrachten van studenten zijn, lijken de beoordelingen op zinsniveau op klaslokaalscores en vormen ze een realistische stresstest. Het nieuwe systeem wordt vergeleken met traditionele woordgebaseerde scores, nieuwere betekenisgebaseerde scores en verschillende sterke neurale modellen. Het stemt niet alleen nauwer overeen met menselijke beoordelingen—met hogere overeenstemming en kleinere gemiddelde fouten—maar draait ook snel genoeg om ruwweg 44 zinnen per seconde te verwerken op standaard grafische hardware. Zorgvuldige experimenten tonen aan dat het aanpassen van BERT aan het juiste type tekst de grootste verbetering brengt, terwijl de extra leertechnieken consistente, kleinere winst opleveren zonder het systeem merkbaar te vertragen.
Wat dit kan betekenen voor docenten en studenten
In eenvoudige bewoordingen laat de studie zien dat een zorgvuldig ontworpen hybride van deep learning en klassieke methoden vertalingen betrouwbaarder kan beoordelen dan bestaande automatische hulpmiddelen, terwijl het snel genoeg blijft voor realtime gebruik in de klas. BERT-SVM EduScore is nog geen plug-invervanging voor menselijke docenten: het is alleen getest op machinevertalingen, niet op echt studentenwerk, en het is nog niet door klasproeven of eerlijkheidstests gegaan. Maar de resultaten suggereren dat zo’n systeem binnenkort docenten zou kunnen helpen door stabiele scores te bieden en waarschijnlijk problematische punten te markeren—zoals fout vertaalde terminologie of ontbrekende getallen—zodat menselijke feedback zich kan richten op diepere, creatievere aspecten van vertalen.
Bronvermelding: Lin, C. A hybrid intelligent assessment model for English translation education with improved BERT and SVM. Sci Rep 16, 5466 (2026). https://doi.org/10.1038/s41598-026-35042-2
Trefwoorden: vertalingsbeoordeling, taalonderwijs, BERT, support vector machines, kwaliteitsinschatting