Clear Sky Science · nl
Hybride kenmerkenselectie met een nieuw diep leermodel voor COVID-19-risicovoorspelling
Waarom het voorspellen van COVID-19-risico nog steeds belangrijk is
Hoewel de wereld leert samenleven met COVID-19 is het virus niet verdwenen. Er blijven nieuwe varianten opduiken, ziekenhuizen kunnen nog steeds onder druk komen te staan en kwetsbare mensen lopen een hoger risico op ernstige ziekte of overlijden. Artsen hebben daarom snelle en betrouwbare manieren nodig om in te schatten hoe waarschijnlijk het is dat een besmette patiënt ernstig ziek wordt. Dit artikel presenteert een nieuw computermodel dat ziekenhuisgegevens en geavanceerde kunstmatige intelligentie gebruikt om COVID-19-risico nauwkeuriger te voorspellen, waardoor clinici mogelijk beter kunnen beslissen wie intensiever moet worden gevolgd, vroegtijdig behandeld of intensive care nodig heeft.
Van ruwe patiëntgegevens naar bruikbare signalen
De studie begint met een zeer grote klinische dataset: meer dan één miljoen anonieme patiënten, elk beschreven met 21 eenvoudige, meestal ja-of-nee kenmerken zoals leeftijdsgroep, onderliggende aandoeningen en andere risicofactoren. Gegevens uit de praktijk zijn rommelig, dus de eerste stap is ze te "schoonmaken". De auteurs passen een wiskundige truc toe die log-scaling heet, waarmee extreme waarden worden samengedrukt en clusters van zeer kleine waarden worden uitgerekt. Deze transformatie maakt de gegevens stabieler en makkelijker te verwerken voor algoritmen, en verkleint de kans dat ongebruikelijke getallen of schaarse indicatoren het model misleiden.
Het kiezen van de meest veelzeggende signalen
Niet elke geregistreerde variabele is even nuttig voor voorspelling, en te veel zwakke signalen kunnen een AI-systeem juist verwarren. De onderzoekers voeren daarom kenmerkenselectie uit, een proces dat minder bruikbare informatie wegfiltert en de meest informatieve factoren behoudt. Hun hybride aanpak combineert twee ideeën: één maat kijkt hoe goed een kenmerk hoge-risico- en lage-risicopatiënten scheidt, en een andere controleert hoe sterk kenmerken onderling overlappen. Door deze twee gezichtspunten op een gemeenschappelijke schaal te wegen, bevoordeelt de methode kenmerken die zowel krachtig als niet-redundant zijn. Deze snoei versnelt het trainen, vermindert overfitting en concentreert het model op de meest klinisch relevante patronen.
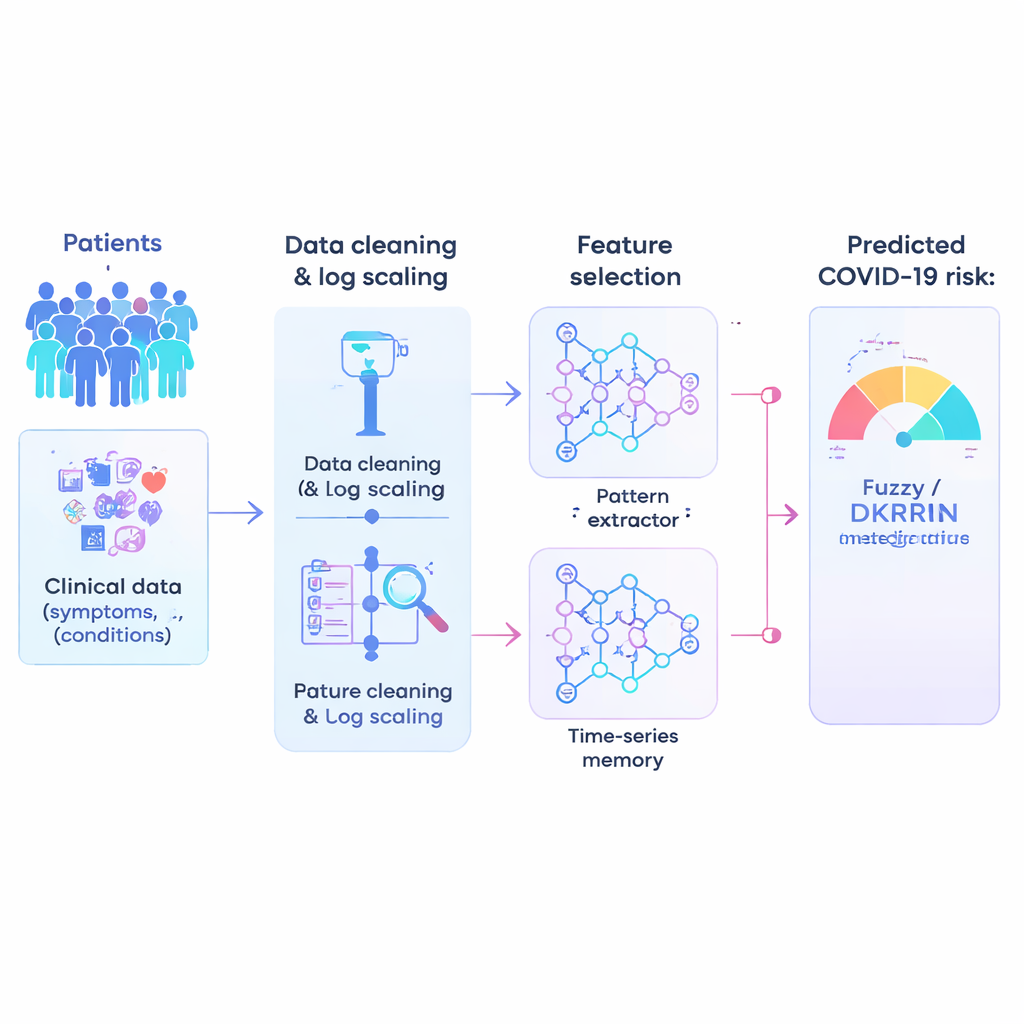
Patroonherkenning mengen met vagerekenen
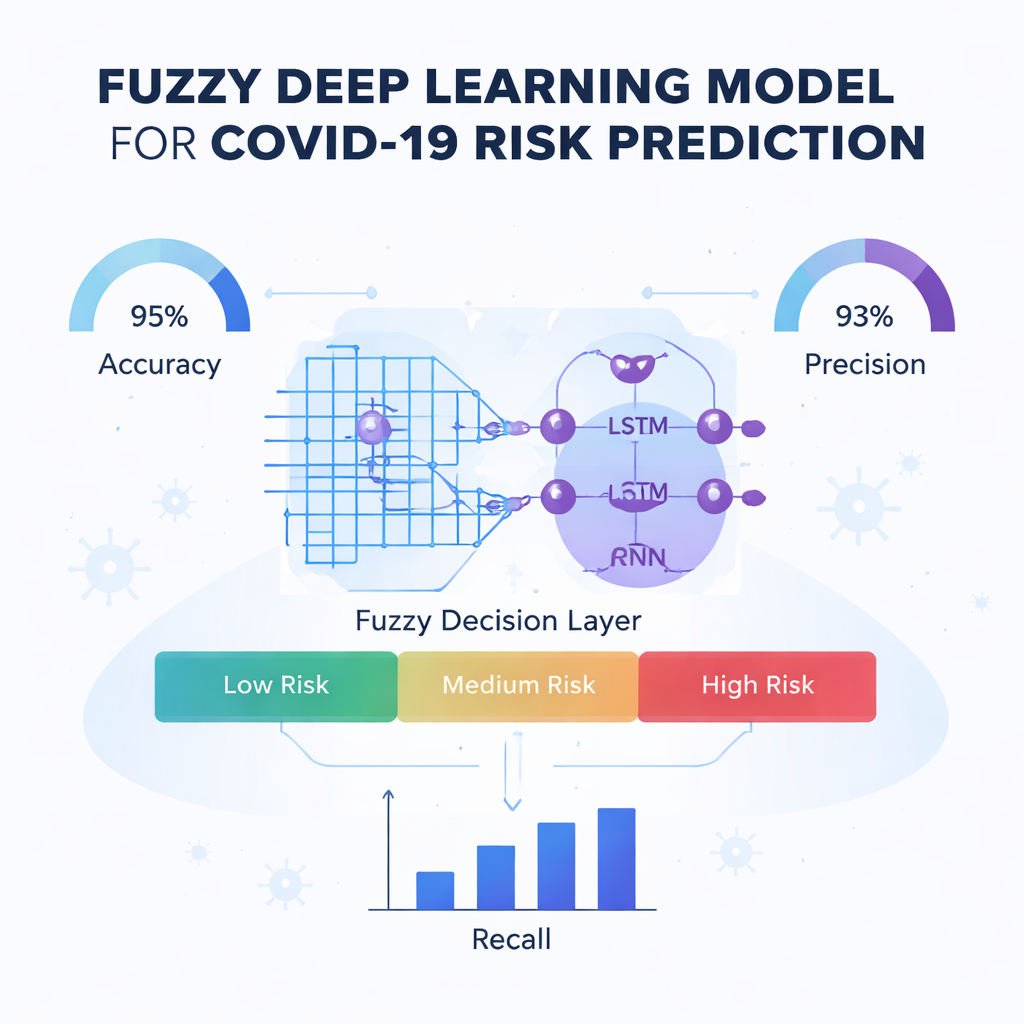
De kern van het artikel is een nieuwe voorspellingsmotor die de Fuzzy-Deep Kronecker Recurrent Neural Network heet, of Fuzzy-DKRNN. Het combineert verschillende aanvullende technieken. Een component, een Deep Kronecker Network, is ontworpen om compacte, gestructureerde patronen in de klinische gegevens te ontdekken. Een andere component, een diep recurrent netwerk, is goed in het vastleggen van afhankelijkheden en trends, bijvoorbeeld wanneer een combinatie van factoren over tijd het risico beïnvloedt. Daarbovenop leggen de auteurs een systeem van vage logica. In plaats van alleen harde ja-of-nee-beslissingen te nemen, drukken vage regels uitspraken uit zoals "als meerdere risicofactoren redelijk hoog zijn, is de patiënt waarschijnlijk hoog-risico." Elke regel heeft een mate van zekerheid, waardoor het model om kan gaan met de onzekerheid en grijstinten die in de geneeskunde vaak voorkomen.
Hoe goed presteert het model?
De auteurs testen hun Fuzzy-DKRNN-model grondig tegen verschillende state-of-the-art alternatieven, waaronder systemen gebaseerd op thoraxröntgenbeelden, traditionele machine learning en andere deep learning-benaderingen. Met behulp van standaardmaten zoals nauwkeurigheid, precisie, recall en F1-score komt hun methode consistent als beste uit de bus. In de beste configuratie classificeert het model ongeveer 91% van de gevallen correct, met een hoge capaciteit zowel om patiënten te detecteren die ernstig ziek zullen worden als om onnodige alarmen te voorkomen bij degenen die dat niet zullen. Deze verbeteringen blijven gelden wanneer de hoeveelheid trainingsdata en interne validatie-instellingen worden gevarieerd, wat suggereert dat de aanpak robuust is en niet subtiel afgestemd op één specifieke situatie.
Wat dit betekent voor patiënten en ziekenhuizen
Kort gezegd laat dit werk zien dat het combineren van zorgvuldige gegevensopschoning, slimme selectie van sleutelrisicofactoren en een hybride van deep learning met vage logica betrouwbaardere COVID-19-risicovoorspellingen kan opleveren op basis van routinematige klinische informatie. Zo'n hulpmiddel vervangt artsen niet, maar kan dienen als een vroegwaarschuwingsassistent—patiënten signaleren die extra waakzaamheid verdienen, het inzetten van schaarse middelen zoals intensivecarebedden sturen, en uiteindelijk helpen onnodige sterfgevallen te verminderen. Dezelfde strategie kan ook worden aangepast voor andere ziekten waarbij vroege risicodetectie uit complexe klinische data cruciaal is.
Bronvermelding: P, G.S., Kathiravan, M., Shanthi, S. et al. Hybrid feature selection with novel deep learning model for COVID-19 risk prediction. Sci Rep 16, 4106 (2026). https://doi.org/10.1038/s41598-026-35013-7
Trefwoorden: COVID-19-risicovoorspelling, diep leren, vage logica, klinische besluitvorming, medische AI-modellen