Clear Sky Science · nl
Voorspelling van overleving bij verschillende kankersoorten met behulp van machine learning-modellen
Waarom het van belang is om overleving bij kanker op nieuwe manieren te voorspellen
Kankerpatiënten en hun naasten stellen vaak een simpele maar kwellende vraag: “Hoeveel tijd heb ik nog?” Artsen proberen te antwoorden op basis van ervaring en eerdere gegevens, maar voor veel zeldzamere kankers zijn er simpelweg niet genoeg vergelijkbare gevallen om nauwkeurige voorspellingen te sturen. Deze studie onderzoekt of moderne computermethoden veilig ervaring kunnen “lenen” van veelvoorkomende kankers om de overleving bij minder vaak voorkomende vormen te voorspellen, wat mogelijk meer patiënten duidelijkere verwachtingen en beter afgestemde zorg kan bieden. 
Huidige patiënten gebruiken om toekomstige zorg te informeren
De onderzoekers werkten met een grote verzameling real-worldgegevens uit ziekenhuis-kankerregistraties in São Paulo, Brazilië. Deze dossiers omvatten meer dan een miljoen patiënten behandeld tussen 2000 en 2019 en bevatten gegevens zoals leeftijd, tumoorstadium, ontvangen behandelingen en of de persoon drie jaar na diagnose nog in leven was. Door te focussen op die driejaarsmijlpaal kon het team kankers met zeer verschillende typische levensverwachtingen vergelijken en tegelijkertijd extreem scheve gegevens vermijden, waar bijna iedereen óf overleeft óf komt te overlijden.
Computers leren overlevingspatronen herkennen
Om deze registratie om te zetten in een voorspellingsinstrument gebruikten de auteurs twee veelgebruikte machine learning-methoden, XGBoost en LightGBM. Deze methoden proberen de biologie niet direct te doorgronden; in plaats daarvan filteren ze duizenden patiëntgeschiedenissen om patronen te vinden die kenmerken zoals ziekte-stadium en timing van behandeling koppelen aan latere overleving. Eerst bouwde het team “specialistische” modellen, elk alleen getraind op één kankertype, zoals borstkanker, longkanker of maagkanker. Daarna controleerden ze hoe goed deze modellen de driejaarsoverleving voorspelden voor nieuwe patiënten met dezelfde kanker, met behulp van standaardmaatstaven die juiste herkenning van overlevers en niet-overlevers in balans brengen.
Kan de ene kanker de andere voorspellen?
De kern van de studie stelt een gedurfde vraag: kan een model dat op één kankertype is getraind, met succes de overleving bij een ander type kanker voorspellen? Om dit te testen groepeerden de onderzoekers kankers op twee manieren: de meest voorkomende kankers (huid, borst, prostaat, colorectaal, long en cervix) en kankers van het spijsverteringsstelsel (mondholte, orofarynx, slokdarm, maag, dunne darm, colorectaal en anus). In een eerste fase trainden ze afzonderlijke modellen voor elke kanker en probeerden die op de andere kankers uit, waarbij ze alleen paren selecteerden waarin zowel overleving als niet-overleving redelijk gebalanceerd werden voorspeld. In latere fasen voegden ze gegevens van geselecteerde kankers samen in gedeelde trainingssets en creëerden meer algemene modellen die putten uit patronen over verwante tumoren heen. 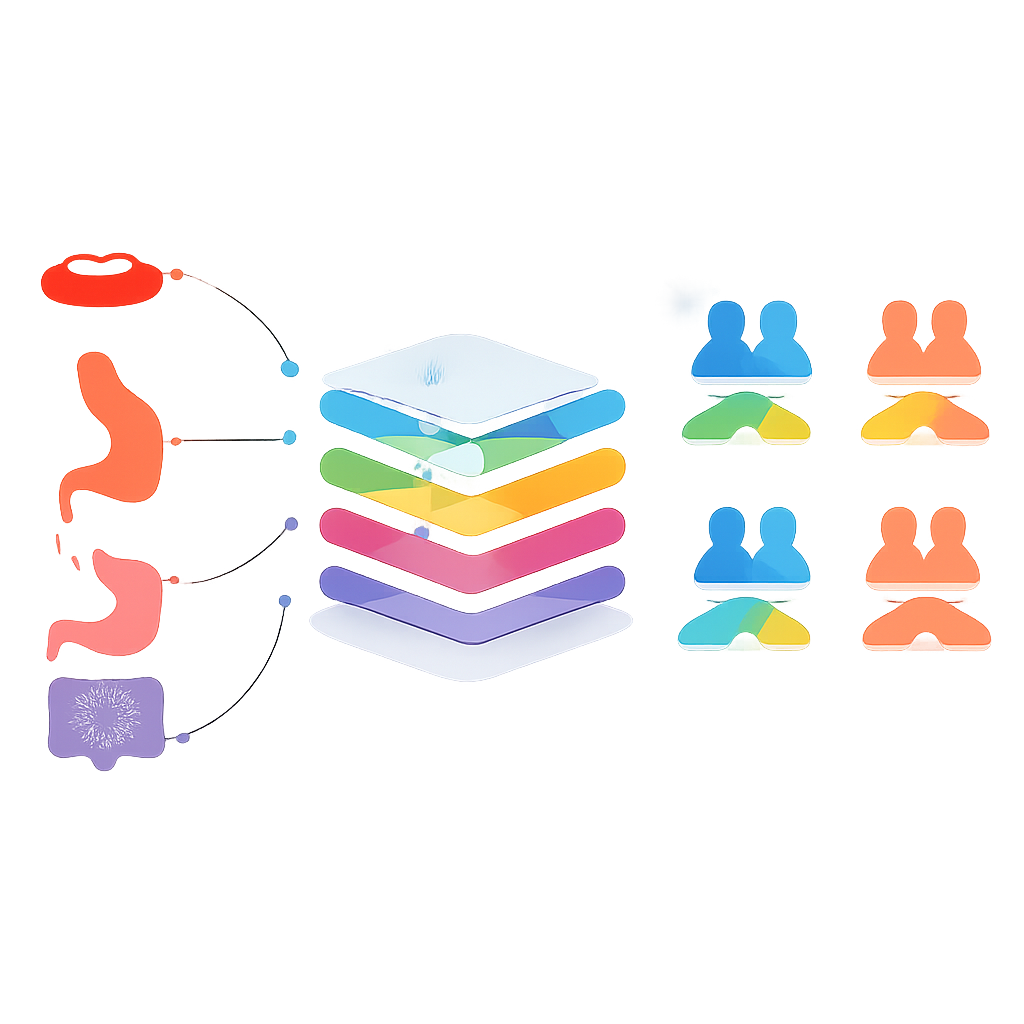
Waar cross-cancer leren helpt — en waar niet
Voor de veelvoorkomende kankers bleek het combineren van gegevens over typen heen de beste specialistische modellen niet te verslaan. Een enkel model getraind op alle zes veelvoorkomende kankers voorspelde bijvoorbeeld minder nauwkeurig dan modellen die per kanker waren toegesneden. Het verhaal was anders voor sommige kankers van het spijsverteringsstelsel. Wanneer gegevens van mondholte-, slokdarm- en maagkankers werden samengevoegd, voorspelde het resulterende model de driejaarsoverleving voor maagkanker iets beter dan het maag-specifieke model, met een gebalanceerde nauwkeurigheid net boven de 80 procent. Statistische tests lieten echter zien dat deze verbetering niet duidelijk van toeval te onderscheiden was, wat betekent dat het gedeelde model en het specialistische model in wezen gelijk stonden. Vergelijkbare “bijna maar net niet duidelijk beter” resultaten deden zich voor bij mondholte-, dunne darm- en colorectale kankers, vaak met afwegingen tussen het correct identificeren van overlevenden versus niet-overlevenden.
Wat dit betekent voor patiënten met zeldzame kankers
Hoewel cross-cancer modellen zelden beter presteerden dan de beste ziektespecifieke modellen, kwamen ze vaak dichtbij — en gebruikten alleen informatie geleend van andere kankersoorten. Voor zeldzame kankers die geen grote, hoogwaardige datasets hebben, is dit een bemoedigend teken: in de toekomst kunnen artsen mogelijk steunen op modellen getraind op meer voorkomende kankers om zinvolle overlevingsschattingen te bieden wanneer specialistische tools niet te bouwen zijn. De auteurs waarschuwen dat deze methoden nog niet klaar zijn voor routinematig klinisch gebruik en dat ze in andere regio’s moeten worden getest en gecombineerd met diepgaandere biologische gegevens. Toch wijst het werk op een toekomst waarin geen patiënt zonder richtlijn hoeft te staan alleen omdat zijn of haar kanker zeldzaam is.
Bronvermelding: Cardoso, L.B., Egydio, J.E., Toporcov, T.N. et al. Cross-cancer survival prediction using machine learning models. Sci Rep 16, 9623 (2026). https://doi.org/10.1038/s41598-025-34133-w
Trefwoorden: voorspelling van kankeroverleving, machine learning in oncologie, cross-cancer modellering, zeldzame kankers, klinische registraties