Clear Sky Science · nl
Berekening van zinsgelijkheidscore via hybride deep learning met speciale aandacht voor ontkennende zinnen
Waarom woordbetekenis ertoe doet voor eerlijke beoordeling
Wanneer studenten vragen in hun eigen woorden beantwoorden, moeten computers die docenten helpen met nakijken meer begrijpen dan alleen gedeelde trefwoorden. Een klein woord als “niet” kan de betekenis van een zin omkeren, en als geautomatiseerde systemen die omkering missen, kunnen studenten oneerlijk beoordeeld worden. Dit artikel pakt dat probleem aan door een nieuwe manier te ontwerpen waarop computers de betekenis van zinnen kunnen vergelijken, met bijzondere aandacht voor hoe ontkennende woorden veranderen wat er wordt gezegd.
De uitdaging van kleine woorden met grote impact
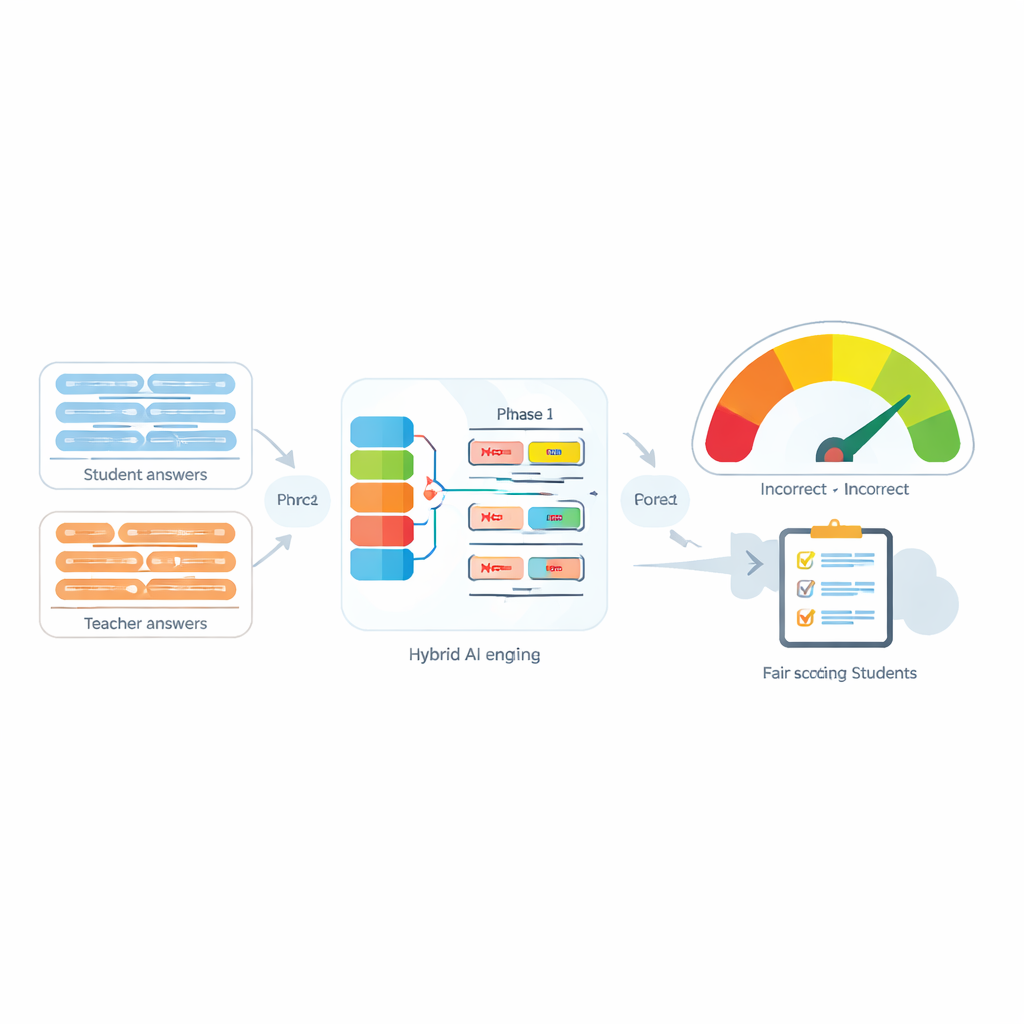
Automatische beoordelingssystemen worden steeds vaker gebruikt om de werklast van docenten te verlichten door een antwoord van een student te vergelijken met het modelantwoord van een docent. Veel moderne hulpmiddelen doen dit door elke zin om te zetten in een numerieke “vingerafdruk” en vervolgens te meten hoe dicht die vingerafdrukken bij elkaar liggen. Deze hulpmiddelen werken redelijk goed wanneer er geen ontkenning is, maar falen vaak wanneer woorden als “niet”, “nooit” of “geen” verschijnen. Bijvoorbeeld, “De methode is nauwkeurig” en “De methode is niet nauwkeurig” kunnen voor de computer verrassend gelijk lijken, hoewel ze tegenovergestelde betekenissen hebben. De auteurs tonen aan dat niet alleen de aanwezigheid van ontkenning, maar ook hoeveel ontkennende woorden er voorkomen en waar ze in een zin staan, de bedoelde betekenis volledig kunnen veranderen.
Een dataset bouwen die nuance leert
Om een systeem te trainen dat ontkenning echt begrijpt, hadden de auteurs eerst data nodig die deze lastige gevallen benadrukt. Zij creëerden de Negation-Sentence-Similarity Dataset, met 8.575 zinnenparen uit vier informatica-domeinen: besturingssystemen, databases, computernetwerken en machine learning. Voor elk paar gaven mensen een gelijkenheidsscore die al rekening houdt met ontkenning. De dataset registreert bovendien hoeveel ontkennende woorden elke zin gebruikt en welk type ontkenningspatroon er optreedt, zoals een enkele “niet”, een even of oneven aantal ontkenningen, of complexere gevallen waarin ontkenning samenwerkt met verbindingswoorden als “omdat” of “maar”. Deze gedetailleerde labeling geeft het model expliciete aanwijzingen over hoe ontkenning de betekenis vormt.
Een hybride motor die veel gezichtspunten samenvoegt
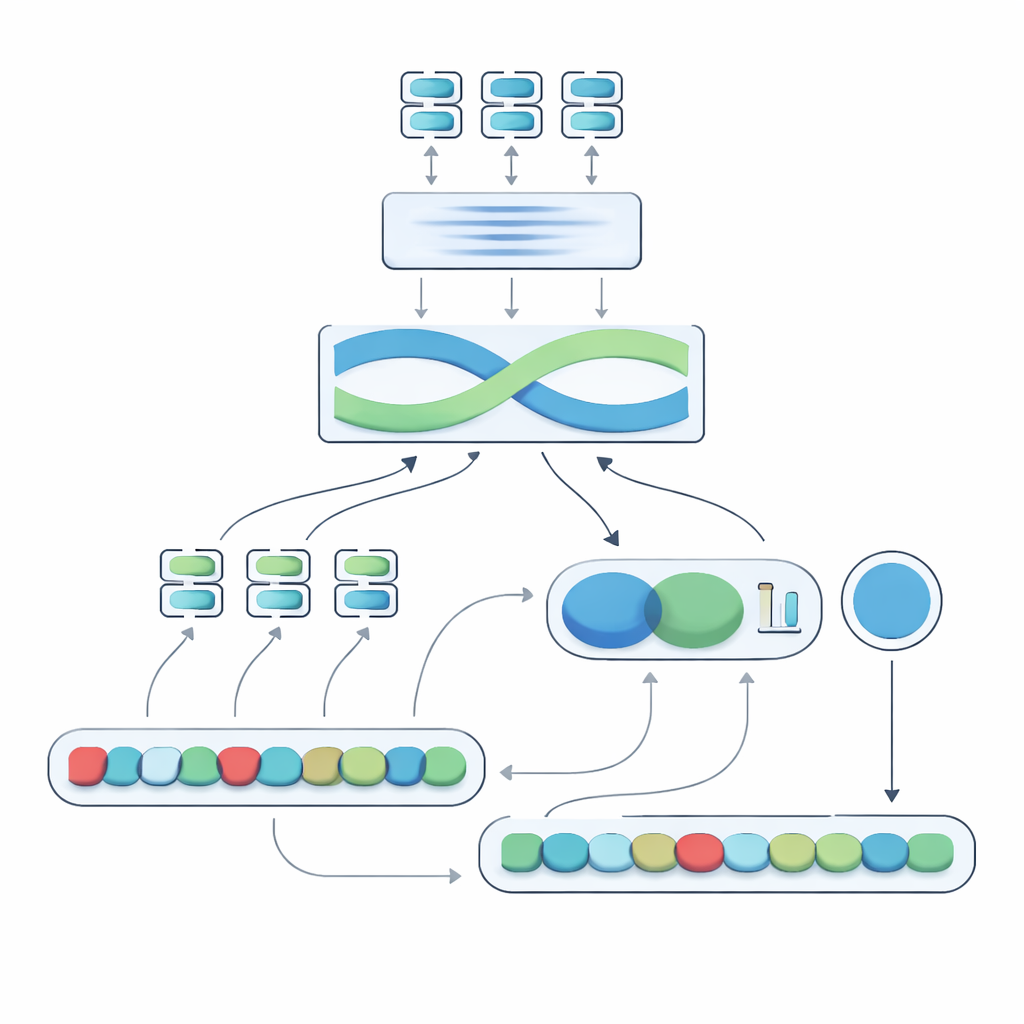
De kern van het voorgestelde systeem, genoemd de Negation-Aligned Similarity Scorer, is een tweefasenmotor. In de eerste fase voert het systeem elke zin door verschillende taalmodellen, die elk net iets andere aspecten van betekenis vastleggen. Hun output wordt aan elkaar gekoppeld en vervolgens door een bidirectioneel recurrent netwerk geleid dat naar de zin als geheel kijkt en woordvolgorde en lokale context in aanmerking neemt. Dit levert een compacte samenvatting van elke zin op die beter is afgestemd op subtiele formuleringen, inclusief waar ontkennende woorden zich bevinden ten opzichte van andere woorden.
Het model leren de omkering door ontkenning te voelen
In de tweede fase vergelijkt het systeem de twee zinsamenvattingen en voegt expliciete informatie over ontkenning toe. Het kijkt hoeveel de samenvattingen van elkaar verschillen, hoeveel ze overlap hebben, en combineert die signalen met drie eenvoudige kenmerken: het verschil in het aantal ontkennende woorden, of de zinnen een oneven of even aantal ontkenningen hebben (wat negatieve betekenis kan omkeren of opheffen), en of ontkenning ongeveer op corresponderende posities voorkomt. Al deze aanwijzingen worden samengevoegd in een klein voorspellingsnetwerk dat een gelijkenheidsscore tussen 0 en 100 uitspuugt. End-to-end getraind op de samengestelde dataset, wordt deze score gevoelig voor de manier waarop ontkenning betekenis herschikt in plaats van “niet” als slechts een ander woord te behandelen.
Hoe goed de nieuwe scorer in de praktijk presteert
Om hun aanpak te testen, evalueren de auteurs deze zowel op hun eigen dataset als op een veelgebruikt benchmark voor zinsgelijkheid. Vergeleken met sterke transformer-gebaseerde baselines die standaardmethoden gebruiken, behaalt de nieuwe scorer een lagere voorspellingsfout en een veel hogere classificatiekwaliteit, met een F1-score dicht bij 0,97. In zorgvuldig gekozen voorbeelden geeft het lage gelijkenheidsscores wanneer ontkenning duidelijk de betekenis omkeert en hoge scores wanneer dubbele ontkenning de betekenis effectief opheft, terwijl concurrerende modellen nog steeds de neiging hebben gelijkenis te overschatten. Een ablatiestudie bevestigt dat beide sleutelelementen — de sequentie-bewuste recurrente laag en de expliciete ontkenningskenmerken — belangrijk zijn voor deze prestatieverbetering.
Wat dit betekent voor studenten en toekomstige hulpmiddelen
Voor een algemene lezer is de conclusie simpel: de manier waarop we “niet” zeggen doet ertoe, en machines kunnen worden geleerd om dat op te merken. Door meerdere taalmodellen, contextuele verwerking en eenvoudige tellingen en posities van ontkennende woorden te combineren, biedt de voorgestelde scorer een eerlijkere en betrouwbaardere manier om te beoordelen wanneer twee zinnen echt hetzelfde betekenen. Dit kan geautomatiseerde beoordelingssystemen helpen ernstige fouten te vermijden, zoals het behandelen van “is niet toegestaan” alsof het “is toegestaan” is. Hoewel de methode meer rekenkracht vereist en nog steeds gericht is op technische domeinen, wijst het op toekomstige hulpmiddelen die de fijnmazige logica van alledaagse taal beter vatten, waardoor geautomatiseerde taalkundige technologieën zowel slimmer als betrouwbaarder worden.
Bronvermelding: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Trefwoorden: zinsgelijkheid, ontkenning in taal, geautomatiseerd nakijken, verwerking van natuurlijke taal, deep learning modellen