Clear Sky Science · nl
Hoge prestaties bij IP-zoekopdrachten door GPU-versnelling ter ondersteuning van schaalbare en efficiënte routering in datagedreven communicatienetwerken
Waarom snellere internetwegen ertoe doen
Elke foto die u deelt, video die u streamt of bericht dat u verzendt, moet door een doolhof van digitale kruispunten genaamd routers. Elke router moet snel beslissen waar elk datapakket vervolgens naartoe moet. Nu het wereldwijde internetgebruik explodeert, vinden deze beslissingen miljarden keren per seconde plaats, en zelfs kleine vertragingen kunnen leiden tot trager browsen of congestie in het netwerk. Dit artikel onderzoekt een nieuwe manier om een van de tijdrovendste stappen in dat beslissingsproces te versnellen door de enorme parallelle rekenkracht van grafische processors — dezelfde chips die videogames en AI aandrijven — te benutten om toekomstige netwerken snel en schaalbaar te houden.
Het verborgen adresboek van het internet
In het hart van elke router bevindt zich een gigantisch adresboek, de zogenaamde forwarding table, die bereikjes IP-adressen koppelt aan de volgende hop op de reis. Wanneer een pakket binnenkomt, moet de router opzoeken welke invoer het beste overeenkomt met de bestemming van het pakket, volgens de regel van de "langste prefixmatch": uit alle gedeeltelijke adresovereenkomsten kiest hij de meest specifieke. Traditionele softwarematige methoden slaan deze prefixes op in boomachtige structuren en doorlopen die stap voor stap. Dat werkt, maar naarmate tabellen groeien tot tienduizenden of honderdduizenden invoeren, wordt het proces trager en geheugenintensiever, vooral op gewone centrale processors die maar een beperkt aantal taken tegelijk afhandelen.
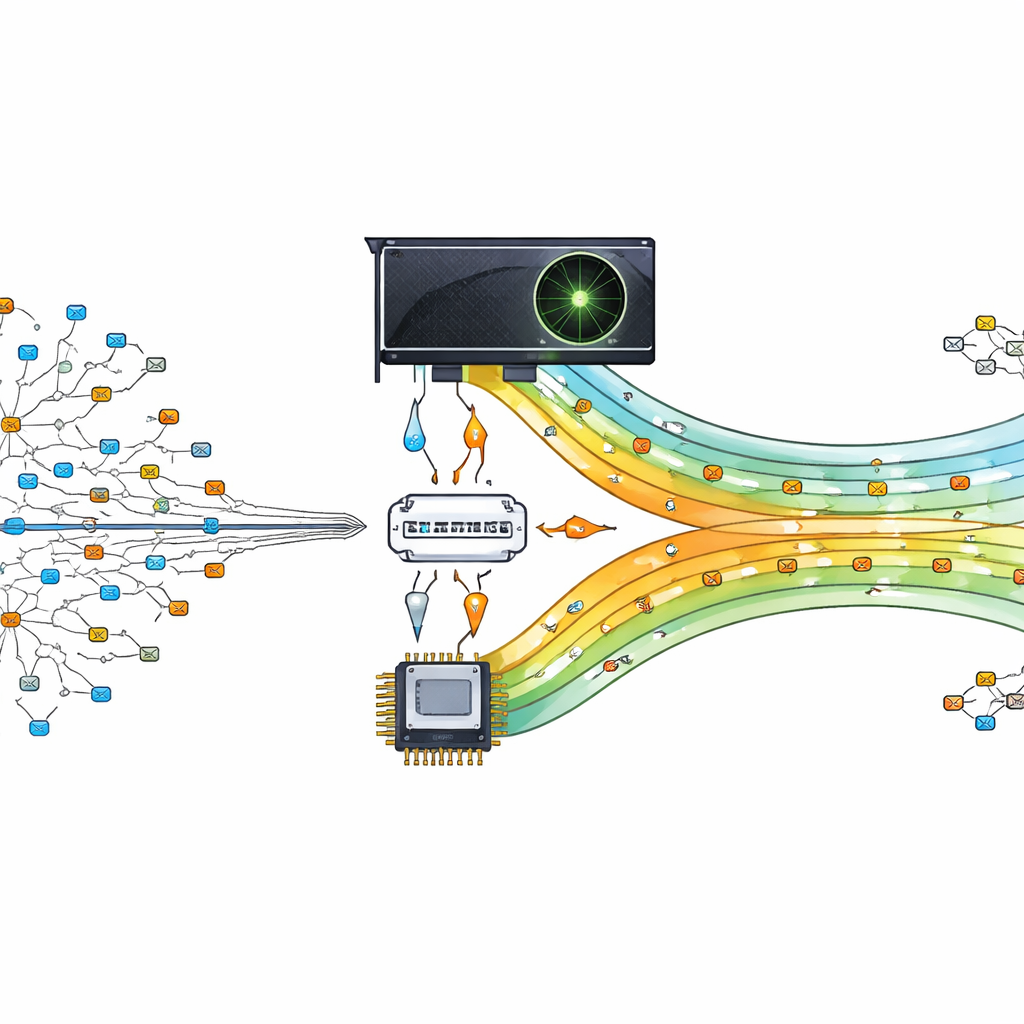
Een grafische chip als verkeersagent inzetten
De auteurs stellen voor dit zware zoekwerk uit te besteden aan een graphics processing unit (GPU), een chip die is ontworpen om duizenden kleine taken parallel uit te voeren. Hun ontwerp behandelt de GPU als een assistent van de hoofdprocessor. De centrale processor bereidt de routeringstabel voor en organiseert deze, en stuurt vervolgens compacte versies van de gegevens naar de GPU. Wanneer pakketten binnenkomen, worden hun bestemmingsadressen opgesplitst en naar de GPU verzonden, waar veel threads gelijktijdig naar de beste match zoeken. Door honderden of duizenden zoekopdrachten parallel te laten verlopen, kan de router gelijke tred houden met moderne, datagedreven communicatie-eisen.
Adressen verkleinen om beslissingen te versnellen
Een belangrijk inzicht van het werk is dat kortere adressen sneller doorzoekbaar zijn. In plaats van ruwe IP-adressen te gebruiken, comprimeren de auteurs ze met een verliesvrije methode genaamd Huffman-codering, die kortere codes toewijst aan de meest voorkomende adrespatronen. Dit vermindert het gemiddelde aantal bits dat nodig is om elke invoer weer te geven, wat zowel het geheugenverbruik als de hoogte van de onderliggende zoekstructuur verkleint. Vervolgens slaan ze de prefixes op in een "multibit"-boom die meerdere bits tegelijk onderzoekt in plaats van slechts één, wat het aantal benodigde stappen verder terugdringt. Om aan te sluiten bij de sterke punten van de GPU transformeren ze deze boom in eenvoudige eendimensionale arrays, waarbij complexe pointer-chasing wordt vervangen door regelmatige indexberekeningen die duizenden threads efficiënt kunnen uitvoeren.
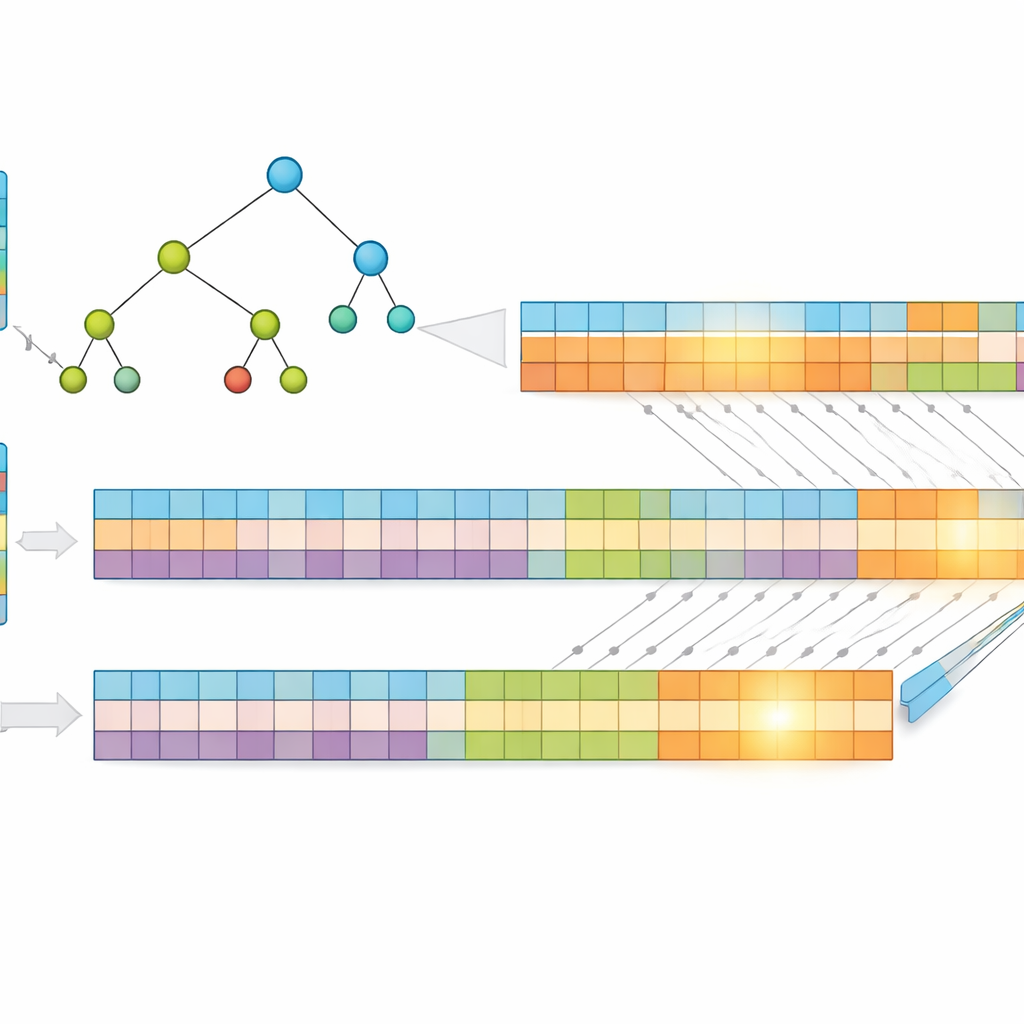
Het probleem splitsen voor massale paralleliteit
Om de prestaties nog verder op te voeren, splitsen de onderzoekers elk gecomprimeerd adres in twee gelijke helften en bouwen twee afzonderlijke bomen — één voor de eerste helft, één voor de tweede. Wanneer een pakket aankomt, doorzoekt de GPU beide bomen parallel. Elke zoekopdracht levert een kleine set mogelijke matches terug, en het definitieve antwoord wordt verkregen door de doorsnede van deze sets te nemen om de gedeelde, meest specifieke prefix te vinden. Omdat het werk wordt verdeeld en gelijktijdig verwerkt, hangt de benodigde tijd voornamelijk af van de maximale prefixlengte en het aantal bits dat per stap wordt bekeken, niet van het aantal invoeren in de tabel. Tests met echte internetrouteringsgegevens tonen aan dat dit ontwerp een nagenoeg constante zoektijd behoudt, zelfs naarmate de tabel groeit.
Wat de experimenten onthullen
Het team vergeleek hun op GPU gebaseerde methode met diverse bekende benaderingen, waaronder klassieke binaire bomen, gecomprimeerde bomen en andere GPU-versnelde schema's zoals hashing en binaire zoekbomen. Op echte routeringsdatasets leverde hun systeem dramatische verbeteringen: ongeveer 83–91 procent sneller dan populaire op centrale processors gebaseerde boommethodes, en 89–97 procent sneller dan eerdere GPU-methoden. Compressie verminderde ook het geheugenverbruik met ongeveer een derde gemiddeld, waarmee de druk op het beperkte on-chip geheugen afnam en de zoekstructuren van de GPU ondiep en efficiënt bleven. Belangrijk is dat de prestaties van de methode stabiel bleven bij verschillende groottes van routeringstabellen, wat haar geschiktheid voor groeiende netwerken onderstreept.
Wat dit betekent voor alledaagse gebruikers
Voor niet‑specialisten komt het erop neer dat de auteurs laten zien hoe je een grafische chip kunt omvormen tot een uiterst efficiënte verkeersagent voor internetgegevens, door slim te verkleinen en op te splitsen wat adresinformatie betreft. Door compressie, slimmere boomindelingen en massale parallelle zoekopdrachten te combineren, vindt hun aanpak veel sneller dan veel bestaande technieken de beste route voor elk pakket, zonder te vertragen naarmate de adresboeken van het internet groter worden. Hoewel het werk voornamelijk is gedemonstreerd voor het huidige adresstelsel, kunnen dezelfde ideeën worden uitgebreid naar de grotere adresruimten van morgen, wat helpt om toekomstige online diensten responsief te houden terwijl onze vraag naar data blijft groeien.
Bronvermelding: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Trefwoorden: GPU-routering, IP-zoekopdracht, netwerkschaalbaarheid, pakketdoorsturing, parallelle verwerking