Clear Sky Science · nl
Toepassingsanalyse van boomgebaseerd ensembleleren voor modellen die luchtverontreiniging voorspellen
Waarom schonere lucht slimere voorspellingen nodig heeft
Mensen in grote steden staan vaak op met de vraag of de buitenlucht veilig is voor een hardlooprondje, het woon-werkverkeer of om kinderen buiten te laten spelen. Weerapps tonen tegenwoordig luchtkwaliteitsindices naast de temperatuur, maar die cijfers zijn alleen zo goed als de achterliggende modellen. Deze studie stelt een praktische vraag met echte gevolgen: welke moderne kunstmatige-intelligentie-instrumenten doen het beste werk bij het gelijktijdig voorspellen van meerdere belangrijke luchtverontreinigende stoffen, en waarom?
De stadslucht dag na dag volgen
De onderzoekers richtten zich op vier van China’s grootste gemeenten — Beijing, Shanghai, Tianjin en Chongqing — omdat ze verschillende klimaten en vervuilingspatronen bestrijken, van winterse smog tot zomers ozon. Ze verzamelden meer dan vijfduizend dagelijkse waarnemingen van 2021 tot 2024, elk met meetwaarden van zes sleutelverontreinigende stoffen (waaronder fijnstof, grof stof, stikstofdioxide, zwaveldioxide, koolmonoxide en ozon) en weergegevens zoals temperatuur, luchtvochtigheid, wind, neerslag en luchtdruk. Om meer uit deze observaties te halen, voegden ze extra aanwijzingen toe: hoe vervuiling van voorgaande dagen kan doorwerken, hoe temperatuur en wind samen invloed hebben op het verspreiden van vuile lucht, en hoe gecombineerde maten van deeltjes en gassen de gezondheidsrisico’s beter kunnen weerspiegelen.
Digitale “bomen” leren de lucht lezen
In plaats van traditionele fysica- zwaardere weermodellen gebruikten het team een familie van datagedreven instrumenten die bekendstaan als boomgebaseerde machine learning. Deze algoritmen nemen beslissingen door gegevens herhaaldelijk in vertakkingen te splitsen, een beetje als een twintig-vragen-spel dat stap voor stap het eindantwoord nadert. De studie vergeleek drie varianten: een eenvoudige beslisboom; een random forest, dat de uitkomsten van veel bomen gemiddeld om ruis te verminderen; en gradient boosting, dat bomen één voor één opbouwt om eerdere fouten geleidelijk te corrigeren. De wetenschappers stemden elke methode zorgvuldig af en gebruikten een tijdbewuste teststrategie zodat de modellen van eerdere dagen leerden en op latere dagen werden geëvalueerd, wat echte voorspellingsomstandigheden weerspiegelt.
Welke modellen uitblinken voor welke verontreinigende stoffen
De confrontatie liet zien dat er geen enkele methode is die in alles uitblinkt, maar er kwamen wel koplopers naar voren. Random forests waren buitengewoon nauwkeurig voor fijn en grof stof en voor zwaveldioxide, en verklaarden ongeveer 99 procent van de variatie in hun niveaus — dicht bij wat instrumenten zelf kunnen meten. Voor koolmonoxide en stikstofdioxide kwam een vorm van gradient boosting bijna in de buurt van de prestaties van het bos, wat suggereert dat deze stapsgewijze correctiebenadering goed past bij verkeer- en verbrandingsgerelateerde emissies die snel pieken en dalen. Verrassend genoeg hield de eenvoudige beslisboom, ondanks zijn eenvoud, goed stand bij het voorspellen van ozon, een verontreinigende stof die zich vormt door zonlichtgedreven chemie en de neiging heeft drempelachtige patronen te volgen die door vertakkingsregels kunnen worden opgevangen.
In het zwarte gat kijken
Om deze krachtige modellen voor beleidsdoeleinden nuttig te maken, moesten de auteurs laten zien niet alleen hoe goed ze voorspellen, maar waarom. Ze gebruikten een techniek genaamd SHAP, die elke invoer — zoals temperatuur, windsnelheid of een andere verontreinigende stof — eenbijdragescore toekent voor elke voorspelling. Deze analyse bracht enkele onthullende verbanden aan het licht. Koolmonoxide bleek een belangrijke hulpbron bij de opbouw van fijnstof, consistent met zijn rol als marker van onvolledige verbranding die dampen produceert die tot deeltjesvorming leiden. Temperatuur verhoogde sterk de ozonvorming, wat weerspiegelt hoe hete, zonnige dagen de productie versterken. Vochtige lucht die met zwaveldioxide interageert bleek de deeltjesgroei vaak te remmen, en harde wind hielp kleine deeltjes weg te keren tot een bepaalde drempel, waarbij turbulente menging ze lokaal juist kon vasthouden. Deze patronen koppelen de wiskunde terug aan reële atmosferische processen en bieden aanwijzingen voor gerichte beheersmaatregelen.
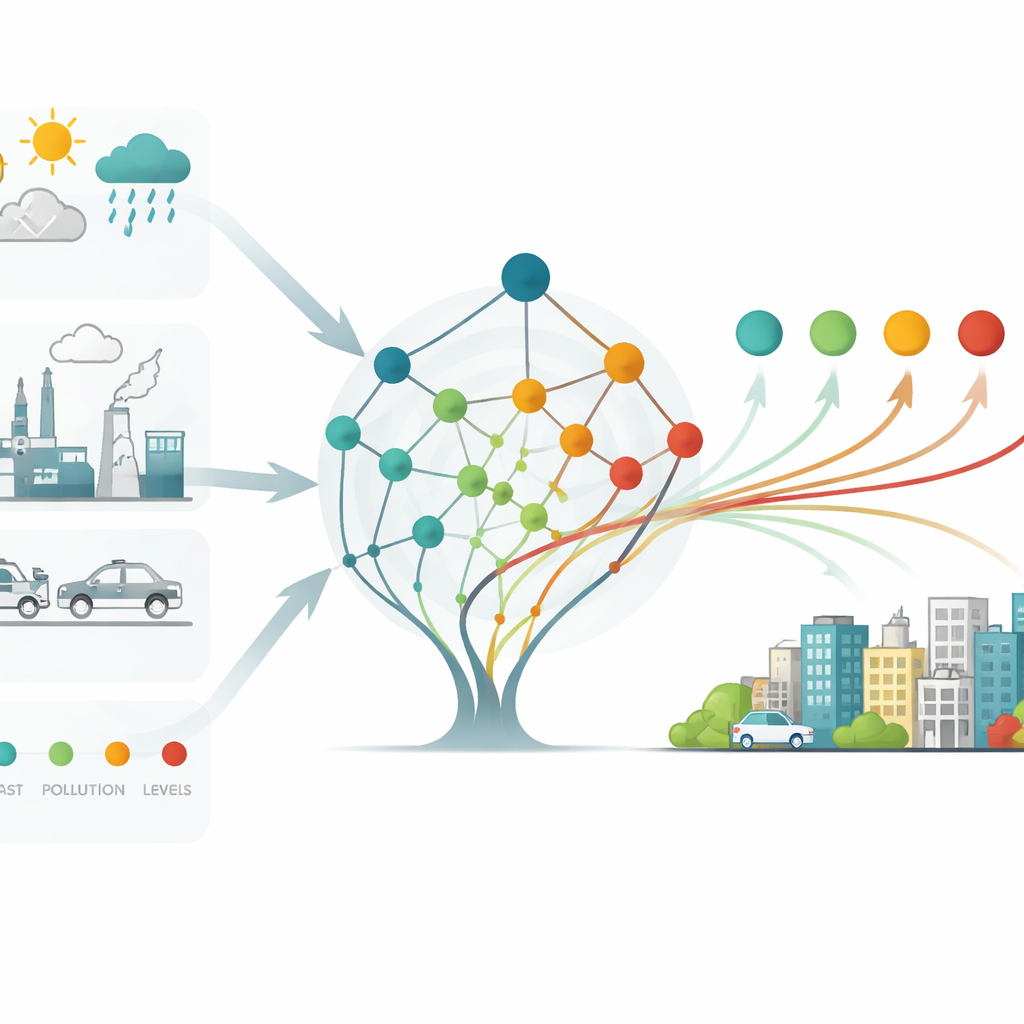
Van onderzoekscode naar stedelijke waarschuwingssystemen
Ondanks indrukwekkende nauwkeurigheid merken de auteurs op dat de modellen nog moeite hebben tijdens de ernstigste smogepisoden en worden beperkt door grove beschrijvingen van waar emissies vandaan komen en door het relatief korte tijdvenster van de data. Ze stellen voor traditionele weer-chemie-simulaties te combineren met machine learning en de SHAP-inzichten te gebruiken om slimmere noodreacties te ontwerpen wanneer vervuiling piekt. Hun raamwerk wordt al gebruikt in een regionaal luchtkwaliteitswaarschuwingssysteem dat Beijing en aangrenzende steden bedient. In praktische termen laat de studie zien dat zorgvuldig gekozen en goed verklaarde kunstmatige intelligentie stadsbestuurders eerder en betrouwbaarder kan waarschuwen voor slechte luchtdagen — en duidelijker kan aangeven welke bronnen eerst aan te pakken zijn.
Bronvermelding: Zhu, X., Li, B., Cao, Y. et al. Applicability analysis of tree-based ensemble learning for air pollutant prediction models. Sci Rep 16, 9602 (2026). https://doi.org/10.1038/s41598-025-32652-0
Trefwoorden: luchtkwaliteitsvoorspelling, stedelijke luchtverontreiniging, machine-learningmodellen, random forest, meercomponentige voorspelling