Clear Sky Science · nl
Een grootschalige dataset van keuze- en reactietijdgegevens bij intertemporele keuzes
Waarom wachten versus nu ertoe doet
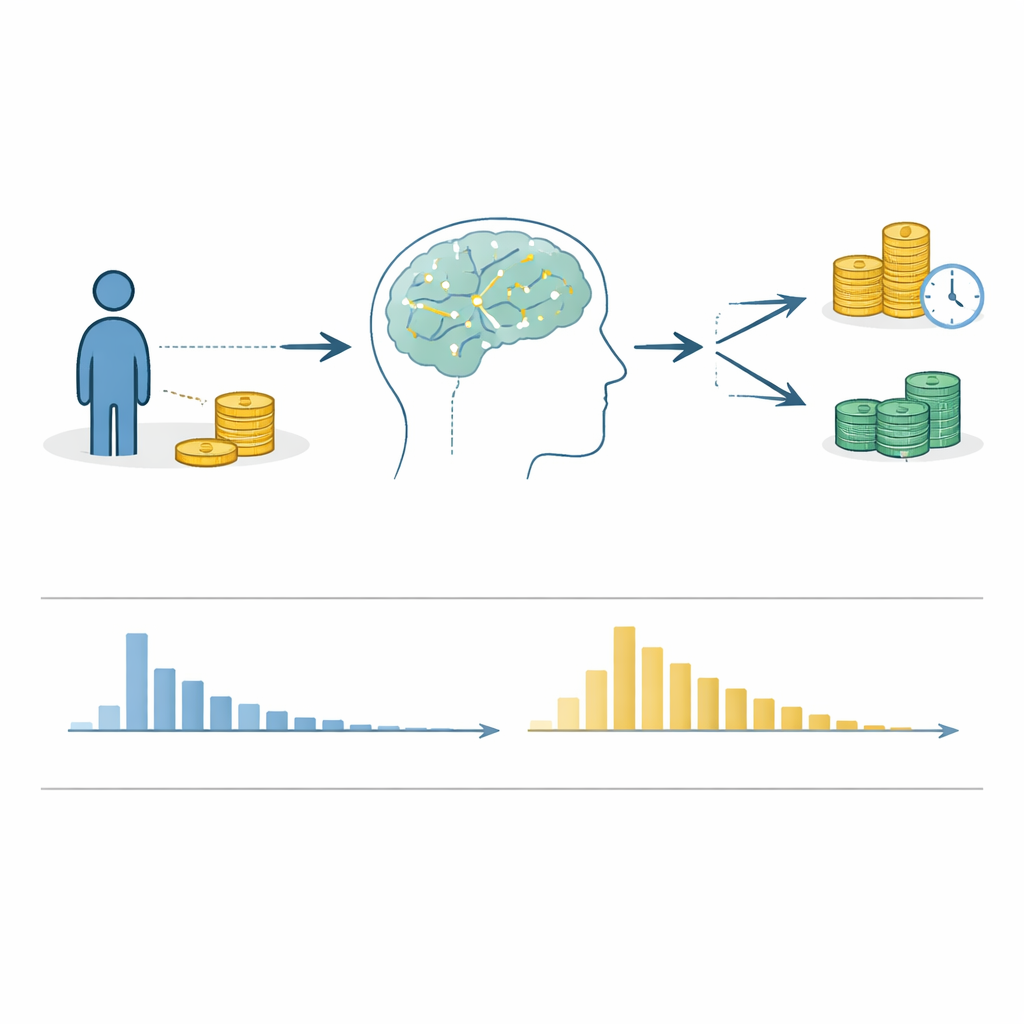
Het dagelijks leven bestaat uit keuzes tussen een kleinere beloning nu en een grotere beloning later: vandaag geld uitgeven of sparen voor pensioen, toetje eten of een dieet volhouden. Hoe we deze “nu versus later”-beslissingen nemen—bekend als intertemporele keuzes—bepaalt onze gezondheid, financiën en relaties. Wetenschappers debatteren echter nog steeds over wat er in ons hoofd gebeurt tijdens zulke beslissingen. Dit artikel introduceert een enorme nieuwe open dataset die gedetailleerde gegevens samenbrengt over hoe bijna twaalfduizend mensen zulke keuzes maakten, inclusief niet alleen wat ze kozen maar ook hoe lang ze nodig hadden om te beslissen.
Verspreide studies onder één dak brengen
Decennialang voerden economen en psychologen experimenten uit waarin mensen bijvoorbeeld kiezen tussen een kleinere geldsom op korte termijn en een grotere som later. Veel van deze studies richtten zich alleen op de uiteindelijke keuze en negeerden het besluitvormingsproces zelf. De auteurs stellen dat hiermee een belangrijke bron van inzicht wordt gemist: reactietijden—hoeveel seconden mensen nodig hebben om te beslissen. Reactietijden kunnen aanwijzingen geven over hoe makkelijk of moeilijk een keuze voelt en helpen theorieën testen over hoe het brein onmiddellijke versus toekomstige beloningen afweegt. Om verder te gaan dan geïsoleerde bevindingen, verzamelden de auteurs ruwe trial-voor-trialgegevens uit 100 afzonderlijke studies, die samen 11.852 deelnemers en 1.172.644 individuele beslissingen beslaan.
De data opsporen en uniformeren
Het team voerde eerst een grote, systematische zoektocht door de wetenschappelijke literatuur in twee hoofd-databases om elk gepubliceerd experiment te vinden dat een standaard computergebaseerde intertemporele keuze-taak gebruikte met duidelijk gedefinieerde geldbedragen en wachtijden. Uit meer dan vierduizend initiële treffers pasten ze strikte criteria toe om studies uit te sluiten die niet bij de taak pasten, niet peer-reviewed waren, niet-menselijke proefpersonen gebruikten, niet in het Engels waren of geen primaire data bevatten. Na dit selecteren bleven 1.709 potentieel geschikte artikelen over. Voor elk van deze vonden de onderzoekers ofwel bestaande open databestanden of namen ze rechtstreeks contact op met auteurs; uiteindelijk stuurden ze meer dan 1.600 formele dataverzoeken om de onderliggende trial-niveau informatie te verkrijgen.
Hoe de gecombineerde dataset eruitziet
Uit deze inspanning verkregen de auteurs 112 datasets uit 98 publicaties en, na definitieve toestemmingen en kwaliteitscontroles, brachten ze 100 datasets uit 87 artikelen vrij. Elke regel van het gecombineerde bestand correspondeert met één keuze-trial en bevat wat werd aangeboden (een kleinere-kortere en een grotere-latere hoeveelheid), welke optie werd gekozen en hoe lang de persoon nodig had om te reageren. Aanvullende velden beschrijven de deelnemer (zoals leeftijd en land), hoe de taak werd uitgevoerd (online versus in het lab, of keuzes daadwerkelijk werden uitbetaald, of er tijdsdruk was) en hoe data gefilterd moeten worden (bijvoorbeeld trials met ontbrekende waarden). Alle data worden in gangbare formaten geleverd en delen dezelfde variabelenstructuur, waardoor het voor andere onderzoekers eenvoudig is ze met verschillende softwaretools te analyseren.
De data achter de schermen controleren
Aangezien de dataset veel onafhankelijke studies combineert, voerden de auteurs uitgebreide technische controles uit om te garanderen dat de cijfers logisch zijn. Ze vergeleken de gerapporteerde steekproefgroottes en aantallen trials in elk artikel met wat daadwerkelijk in de bestanden voorkomt, documenteerden eventuele afwijkingen en inspecteerden patronen van ontbrekende reacties. Ze verifieerden dat de kleinere-kortere optie daadwerkelijk kleiner en eerder was dan de grotere-latere optie en volgden op met oorspronkelijke auteurs wanneer iets niet klopte. Ze testten ook of de keuzes van mensen zich zinnig gedroegen—bijvoorbeeld of grotere beloningen en kortere wachttijden over het algemeen de kans vergrootten dat een optie werd gekozen. Voor reactietijden screeneden ze op onmogelijke waarden, zoals negatieve tijden of beslissingen die onwaarschijnlijk snel of traag waren, en onderzochten ze of de meeste deelnemers het typische patroon vertoonden van veel snelle reacties en minder langzame.
Een levende bron voor toekomstige inzichten
De auteurs hebben een statische snapshot van deze grootschalige dataset vrijgegeven, gekoppeld aan het artikel, evenals een levende online database die zal blijven groeien naarmate meer onderzoekers hun data bijdragen. Naast het gecombineerde hoofdbestand zijn alle individuele datasets, waar toestemming dat toelaat, ook beschikbaar als afzonderlijke downloads. Hoewel de oorspronkelijke ruwe verwerkingsscripts niet in alle gevallen worden gedeeld, zijn de resulterende data gedocumenteerd en gelicentieerd voor breed hergebruik in niet-commercieel werk. Deze bron opent de deur voor wetenschappers om nieuwe modellen te testen van hoe mensen huidige en toekomstige beloningen afwegen, te onderzoeken waarom resultaten soms verschillen tussen omgevingen en groepen, en betrouwbaardere theorieën van besluitvorming te ontwerpen. Voor de niet-specialistische lezer is de belangrijkste conclusie dat onderzoekers nu een krachtige, gedeelde basis hebben om te begrijpen waarom wachten op een betere toekomst zo moeilijk kan zijn—en hoe die moeilijkheid varieert van persoon tot persoon en van situatie tot situatie.
Bronvermelding: Pongratz, H., Schoemann, M. A large-scale dataset of choice and response-time data in intertemporal choice. Sci Data 13, 323 (2026). https://doi.org/10.1038/s41597-026-06947-4
Trefwoorden: intertemporele keuze, verdiscontering over tijd, reactietijden, besluitvorming, open dataset