Clear Sky Science · nl
PreprintToPaper-dataset: bioRxiv-preprints koppelen aan tijdschriftpublicaties
Waarom vroege onderzoeksresultaten ons allemaal aangaan
Lang voordat een wetenschappelijke ontdekking in een glanzend tijdschrift verschijnt, duikt ze vaak op als een “preprint” — een vroege, vrij gedeelde versie van het werk. Tijdens de COVID‑19-pandemie bepaalden deze preprints krantenkoppen, publieke debatten en zelfs gezondheidsbeleid. Toch is het verrassend moeilijk geweest om bij te houden welke vroege studies later formeel als tijdschriftartikel verschenen en welke dat nooit deden. Dit artikel presenteert de PreprintToPaper-dataset, een grote, zorgvuldig gecontroleerde kaart die life‑science-preprints op de bioRxiv-server verbindt met hun uiteindelijke tijdschriftpublicaties, en zo journalisten, onderzoekers en het publiek een helderder beeld geeft van hoe vroege bevindingen zich door het wetenschappelijke systeem verplaatsen.
De reis van concept naar artikel volgen
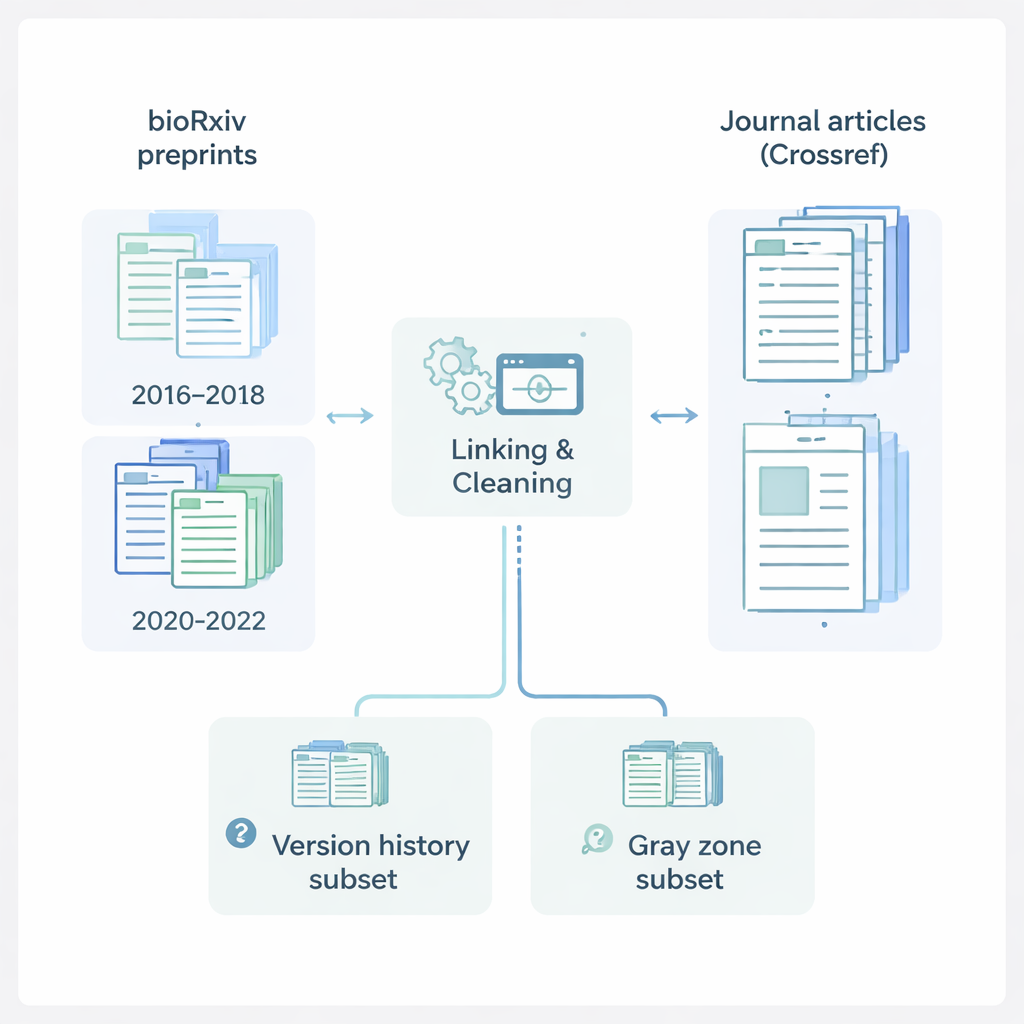
De auteurs richtten zich op bioRxiv, een belangrijke online server waar onderzoekers in de life‑sciences preprints plaatsen. Ze verzamelden gegevens over 145.517 preprints uit twee belangrijke tijdsvensters: 2016–2018, vóór de COVID‑19-pandemie, en 2020–2022, tijdens de intense publicatiegolf van de pandemie. Voor elke preprint registreerden ze details zoals titel, samenvatting, auteurs, instellingen, onderwerpgebied, licentie en indieningsdata. Vervolgens haalden ze via Crossref, een centraal register van tijdschriftartikelen, bijpassende informatie over gepubliceerde artikelen: tijdschriftnamen, publicatiedata en volledige auteurslijsten. Door deze bronnen te combineren, stelden ze een rijk, verenigd dossier samen dat een studie volgt van de eerste publieke verschijning als preprint tot de uiteindelijke vorm in een wetenschappelijk tijdschrift.
Preprints in duidelijke groepen onderbrengen
Om dit grote corpus begrijpelijk te maken, sorteerde het team elke preprint in één van drie groepen. “Published” preprints hadden een duidelijke digitale link van bioRxiv naar een tijdschriftartikel. “Preprint Only”-items waren op de server geplaatst maar toonden geen tekenen van publicatie elders. De meest intrigerende groep, de “Gray Zone”, bevat gevallen die lijken te zijn gepubliceerd in een tijdschrift maar waarbij een officiële link op bioRxiv ontbreekt. Om vast te leggen hoe preprints in de loop van de tijd veranderen, bouwden de onderzoekers ook een aparte versiegeschiedenisbestand dat elke beschikbare versie opsomt voor preprints die een originele versie en ten minste één latere update hadden. Dit maakt het voor anderen mogelijk te bestuderen hoe titels, auteurslijsten en andere details evolueren tussen het eerste concept en de laatste preprintversie.
Verborgen matches opsporen en handmatig controleren
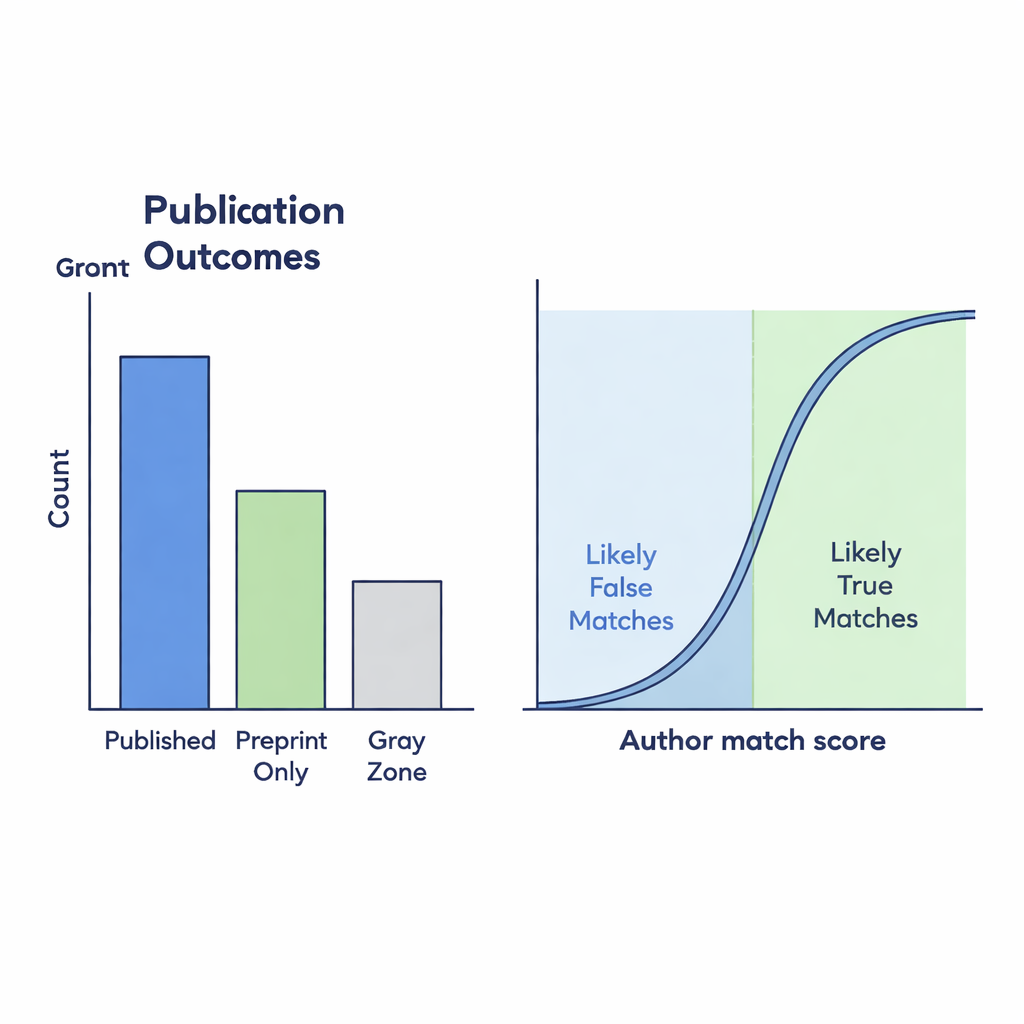
Veel preprints die eigenlijk zijn gepubliceerd, krijgen nooit een juiste teruglink op bioRxiv, wat blinde vlekken creëert voor iedereen die wetenschappelijke output wil volgen. Om deze ontbrekende verbindingen bloot te leggen, vergeleken de auteurs preprinttitels en auteurslijsten met de tijdschriftgegevens van Crossref. Ze gebruikten een gelijkenisscore tussen 0 en 1 om te meten hoe goed twee titels overeenkomen; potentiële Gray Zone-links moesten een score van minstens 0,75 hebben. Deze kandidaten verfijnden ze vervolgens met op auteurs gebaseerde maatstaven: hoe verschillend het aantal auteurs was en hoe vergelijkbaar de namen leken. Om te testen of deze geautomatiseerde regels betrouwbaar waren, onderzochten twee menselijke annotatoren handmatig 299 grensgevallen. Hun oordelen waren sterk eensluidend, en een statistisch model toonde aan dat wanneer auteurslijsten goed overeenkomen, een veronderstelde link zeer waarschijnlijk echt is.
Wat de cijfers onthullen over wetenschappelijke output
De voltooide dataset laat zien hoe preprint- en publicatiepatronen veranderden vóór en tijdens de pandemie. In totaal bevat ze ruim 90.000 duidelijk gepubliceerde preprints, meer dan 35.000 die kennelijk alleen op de server blijven, en ongeveer 19.000 Gray Zone-gevallen waarbij de link naar een tijdschriftartikel detectivewerk vergde. Als alleen naar de officieel gekoppelde “Published”-groep wordt gekeken, lijkt het erop dat een veel kleiner deel van de preprints in de loop van de tijd in tijdschriftartikelen verandert. Maar wanneer waarschijnlijke Gray Zone-matches — die met sterke auteursovereenkomsten — worden meegerekend, is de daling in publicatiepercentages veel minder dramatisch. Dit suggereert dat ontbrekende links in de onderliggende infrastructuur ons een vertekend beeld kunnen geven van hoe het wetenschappelijke landschap verandert.
Waarom deze bron nuttig is buiten de vakwereld
Voor niet‑specialisten is de belangrijkste boodschap dat vroege wetenschappelijke resultaten niet simpelweg in een zwarte doos verdwijnen. Met de PreprintToPaper-dataset wordt het mogelijk te zien welke snelle bevindingen uiteindelijk peer review overleven, hoe lang die reis duurt en welke soorten studies nooit het preprintstadium verlaten. Beleidsmakers kunnen deze informatie gebruiken om te beoordelen hoe goed open‑sciencepraktijken werken; journalisten kunnen beter inschatten hoe solide een bepaald resultaat is; en onderzoekers kunnen tools ontwikkelen die een overweldigende stroom van artikelen filteren en samenvatten. Kortom: deze dataset verandert een chaotische vloed van vroege onderzoeksresultaten in een beter traceerbaar, verantwoordelijk verslag van hoe ideeën van eerste plaatsing naar gepolijste publicatie bewegen.
Bronvermelding: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Trefwoorden: preprints, wetenschappelijke publicatie, open science, COVID-19-onderzoek, bibliometrie