Clear Sky Science · nl
Een multi-label dataset voor de classificatie van China’s landbouw- en landelijke scènes uit VHR-satellietbeelden
Waarom het in kaart brengen van het platteland vanuit de ruimte ertoe doet
In heel China verandert het platteland snel: nieuwe kassen verschijnen op oude akkers, zonneparken breiden zich uit over hellingen en wegen verbinden ooit geïsoleerde dorpen. Toch behandelen de meeste satellietgebaseerde kaarten dit nog steeds als één enkele eentonige categorie zoals “landbouw.” Dit artikel introduceert China‑MAS‑50k, een nieuwe open dataset die computers in staat stelt het landelijke China veel gedetailleerder te zien, met zeer scherpe satellietbeelden en meerdere labels per scène. Het biedt een basis voor beter toezicht op voedselproductie, landelijke ontwikkeling en milieuwijzigingen op nationale schaal.
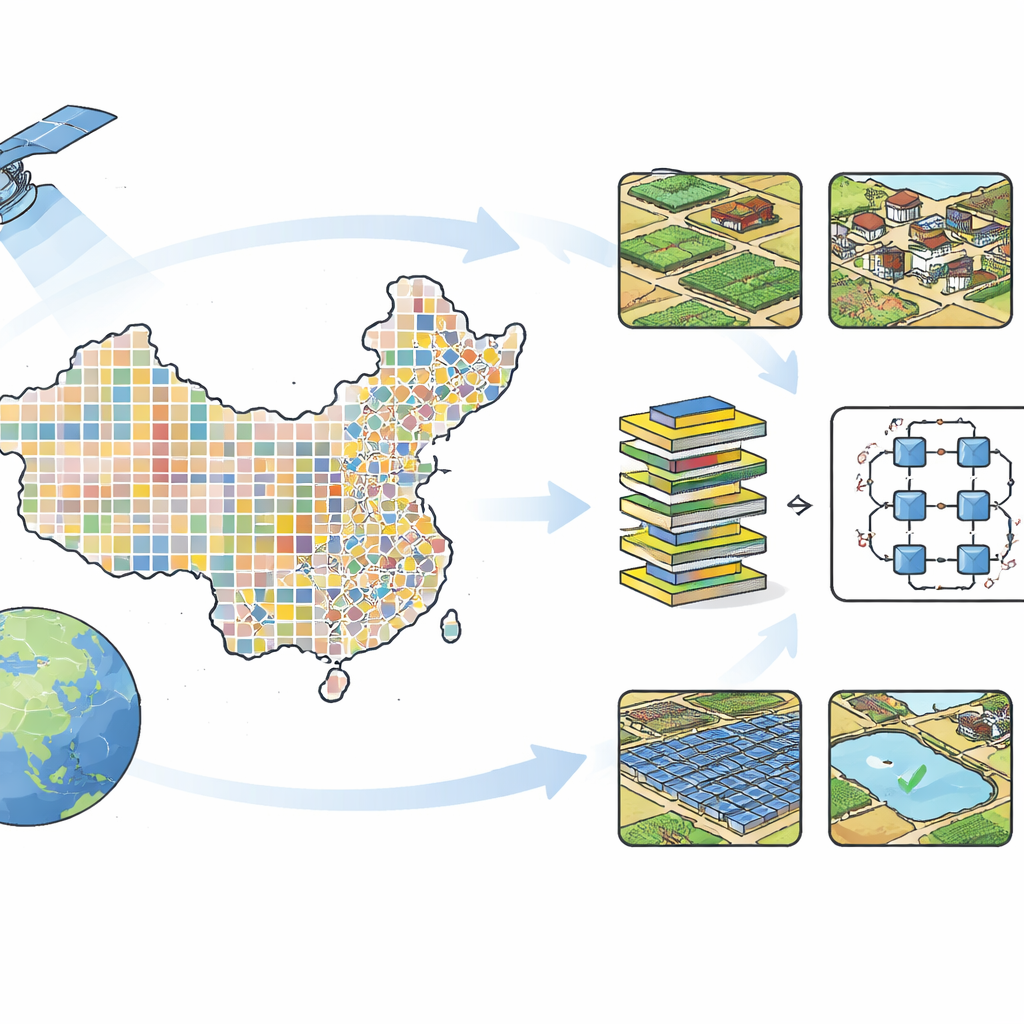
Meer dan één ding tegelijk zien
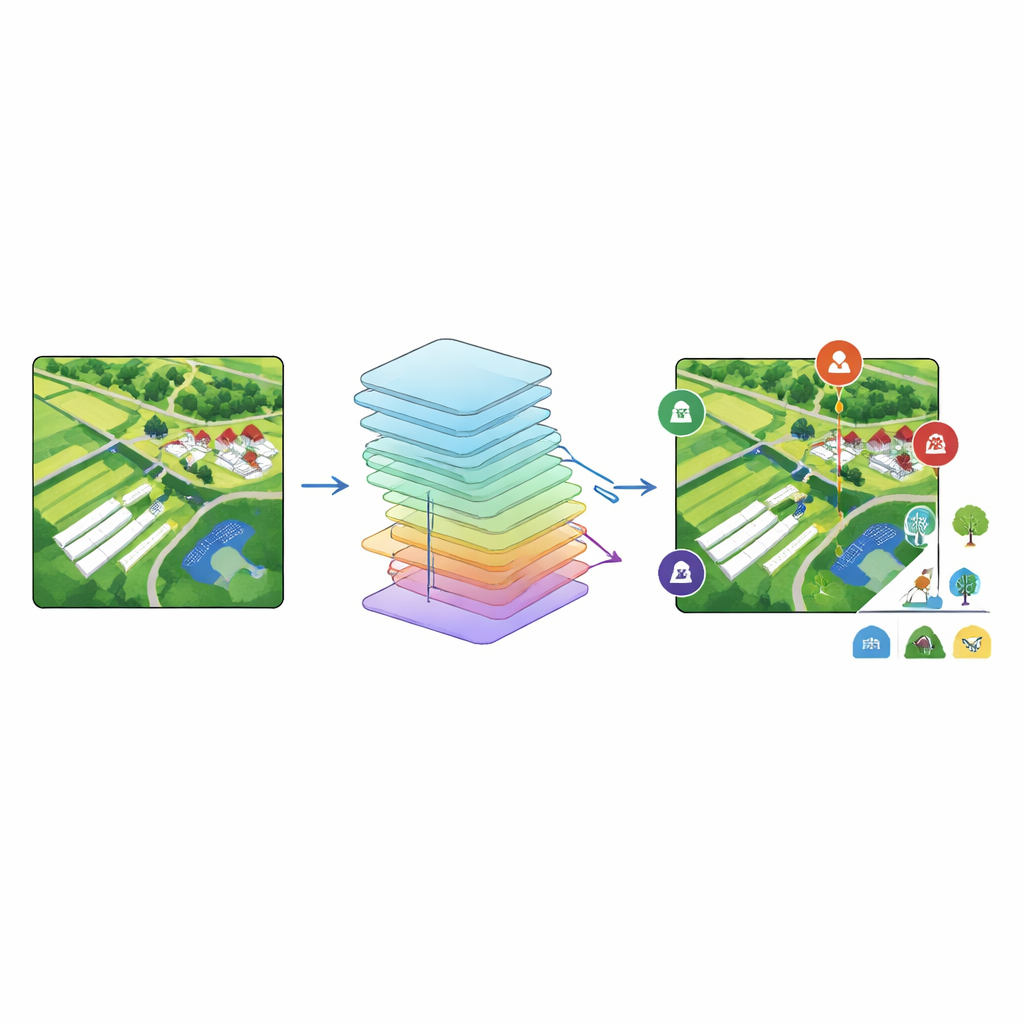
Traditionele satellietkaarten wijzen gewoonlijk slechts één label toe aan elk afbeeldingsvlak—bos, stad of akkerland bijvoorbeeld. Echte plekken zijn zelden zo simpel: een enkele luchtfoto kan tegelijk een dorp, omliggende velden, een vijver, een weg en moderne constructies zoals zonnepanelen of plastic bedekte kassen tonen. Het China‑MAS‑50k‑project omarmt deze complexiteit door elke afbeelding als een mix van elementen te behandelen. In plaats van een keuze af te dwingen, maakt het dat veel labels aan dezelfde plaat kunnen worden gekoppeld, wat beter aansluit bij hoe mensen het land daadwerkelijk zien en gebruiken.
Een gedetailleerd beeld van het landelijke China opbouwen
Om de dataset samen te stellen begon het team met vrij verkrijgbare, zeer‑hogeresolutiebeelden van Google Earth, grotendeels afkomstig van moderne commerciële satellieten die kenmerken van net iets meer dan een meter breed kunnen tonen. Ze legden een raster van 50 kilometer over heel China om de sampling gelijkmatig te spreiden, kozen vervolgens punten in landelijke gebieden en downloadden op elk punt kleine beelden van 512 bij 512 pixels. Afbeeldingen met te veel wolken, sneeuw, onscherpte of een uniform oppervlak werden eruit gefilterd, wat resulteerde in 55.520 heldere scènes, voornamelijk verzameld in 2023–2024. Deze tegels beslaan de uiteenlopende landschappen van het land, maar zijn vooral dicht in de intensiever bewerkte regio’s ten oosten van de beroemde “Hu‑lijn,” waar de meeste mensen en akkerlanden van China te vinden zijn.
Pixels vertalen naar betekenisvolle landtypes
De onderzoekers ontwierpen een labelsysteem met 18 categorieën, afgestemd op het landelijke leven. Het omvat natuurlijke oppervlakken zoals akkerland, bos, grasland, rivieren, meren of vijvers, kale grond en wegen en spoorlijnen, evenals door mensen gemaakte elementen zoals landelijke dorpen, fabrieken, sportvelden, parken, plastic dekbedekking, kassen, fotovoltaïsche (zonne)parken, stuifwerende netten gebruikt op bouwplaatsen en hopen vast afval. Menselijke annotatoren volgden gedetailleerde visuele richtlijnen die typische kleuren, texturen en vormen beschrijven—bijvoorbeeld schaduwen van bomen die op bos wijzen, lange heldere strepen voor kassen, donkere panelen in nette rijen voor zonneparken. Met een open annotatietool labelden drie experts elke afbeelding met alle zichtbare categorieën en controleerden elkaars werk om fouten te vangen. Het resultaat is 135.289 labels, georganiseerd zodat elke afbeelding eenvoudig kan worden gekoppeld aan de volledige lijst van landbedekkings‑types.
Testen hoe slim machines echt zijn
Met deze nieuwe benchmark evalueerden de auteurs een reeks populaire computermodellen. Daartoe behoorden klassieke machine‑learningmethoden gebaseerd op beslisbomen en diepere neurale netwerken die oorspronkelijk waren ontworpen voor taken zoals fotoherkenning. Alle modellen kregen dezelfde drie‑kleurige afbeeldingsinput en moesten voorspellen welke van de 18 categorieën in elke scène voorkwamen. In het algemeen presteerden moderne diepe netwerken beter dan de oudere benaderingen. Daarbinnen bood een model genaamd ResNeXt‑101 de beste balans in nauwkeurigheidsmaatstaven en herkende redelijk goed de meest voorkomende elementen zoals akkerland, bos en wegen. Het had echter moeite met zeldzamere kenmerken zoals stuifwerende netten, plastic dekbedekking en zonneparken, wat toont hoe moeilijk het voor algoritmen is om te leren van beperkte voorbeelden in een “long‑tailed” dataset waarin enkele klassen veel voorkomen en veel andere schaars zijn.
Wat dit betekent voor toekomstige inzichten over het platteland
China‑MAS‑50k biedt meer dan alleen een grote verzameling fraaie satellietfoto’s. Het is een zorgvuldig gecontroleerde, open bron die de ware verscheidenheid van China’s landelijke landschappen en de ongelijke verspreiding van traditionele en moderne landbouw weerspiegelt. Door meerdere labels per afbeelding toe te staan, kan het geavanceerde taken ondersteunen zoals zwak‑gecontroleerde cartografie, waarbij computers leren velden, kassen of wegen te omtrekken met alleen grove scène‑niveau tags. Het biedt ook een realistische testomgeving voor het aanpakken van klasse‑onevenwicht, een belangrijke bottleneck bij het toepassen van kunstmatige intelligentie op rommelige real‑world data. In eenvoudige bewoordingen maakt deze dataset het voor wetenschappers en planners gemakkelijker om computers te leren wat er daadwerkelijk op de grond gebeurt in het landelijke China en om te volgen hoe die plekken in de loop van de tijd blijven veranderen.
Bronvermelding: Yuan, S., Feng, Q., Niu, B. et al. A multi-label dataset for China’s agricultural and rural scenes classification from VHR satellite imagery. Sci Data 13, 384 (2026). https://doi.org/10.1038/s41597-026-06800-8
Trefwoorden: remote sensing, landelijke landschappen, landbouwkaarten, multi-label datasets, satellietbeelden