Clear Sky Science · nl
Een dataset voor video-superresolutie van Chinese traditionele opera gebaseerd op de “Real-world+” degradatiefusie
Oude operafilms weer tot leven brengen
Veel opnamen van Chinese traditionele opera bestaan alleen in kwetsbare, lage‑kwaliteit videovorm. Tijd, stof en herhaaldelijk kopiëren hebben gezichten vervaagd, kostuums dof gemaakt en scènes vol visuele ruis gezet. Dit artikel introduceert een nieuwe manier om zulke video’s digitaal te “reinigen” en scherper te maken — niet door elk filmpje met de hand te herstellen, maar door een gespecialiseerde trainingscollectie voor kunstmatige intelligentie op te bouwen. Het doel is computers te leren hoe ze wazige, verouderde beelden kunnen omzetten in helderdere, levendigere beelden en zo een belangrijk deel van het culturele geheugen van de wereld te behouden.
Waarom oude operavideo’s er zo slecht uitzien
Chinese traditionele opera, waaronder bekende stijlen zoals Pekingopera en Kunqu, is door UNESCO erkend als onderdeel van het gedeelde culturele erfgoed van de mensheid. Toch hebben veel van de overgebleven video's van deze uitvoeringen een lange en ruwe reis achter de rug. Ten eerste voegt de oorspronkelijke filmapparatuur onscherpte en camerageluid toe. Vervolgens veroorzaakt opslag op film, tape of schijven krassen, vervorming en gegevensverlies. Ten slotte zorgen herhaald kopiëren, compressie voor internet en onstabiele netwerkoverdracht voor blokkerige artefacten, flikkering en het wegvallen van frames. Het resultaat is niet slechts een eenvoudige onscherpte, maar een verwarde mix van veel verschillende soorten schade, wat het voor restauratiemethoden erg moeilijk maakt te raden hoe de oorspronkelijke scène eruit had moeten zien.
Parren van vage en scherpe frames opbouwen
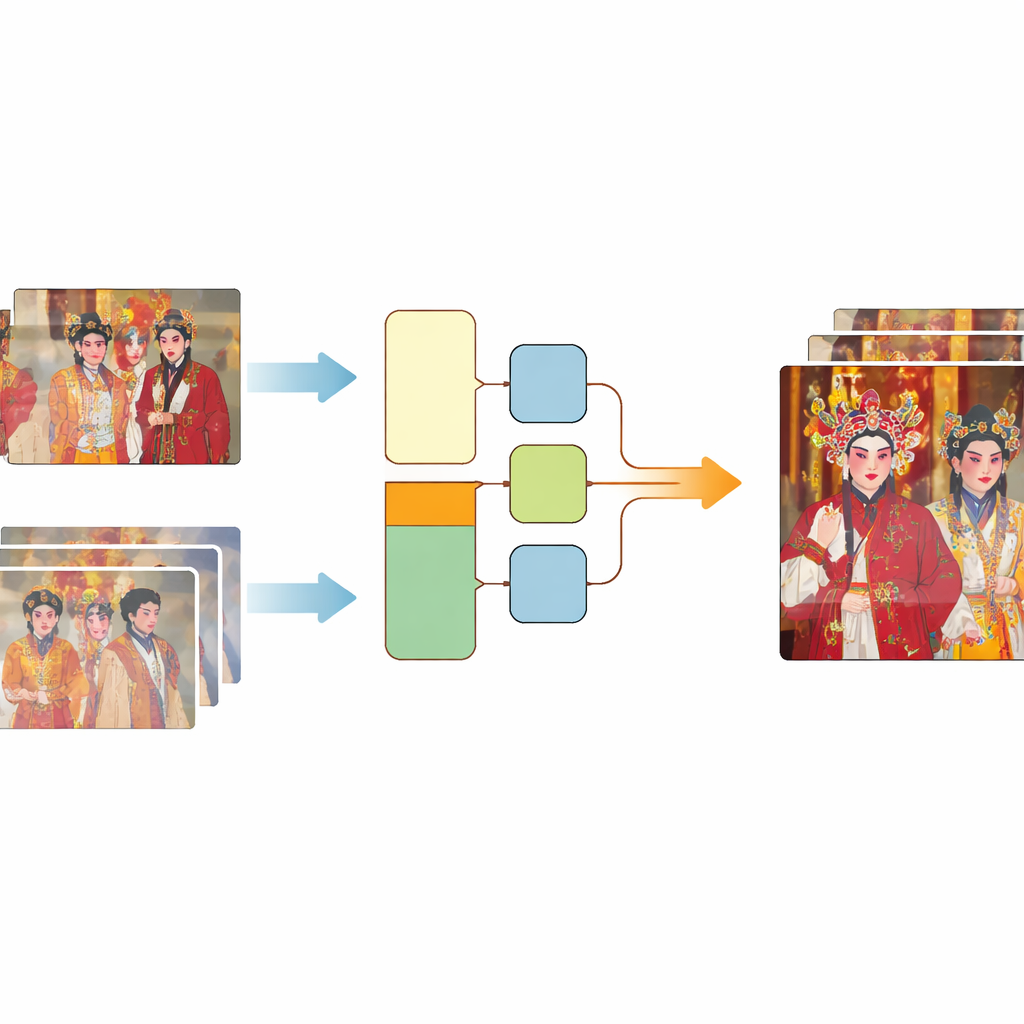
Moderne video-“superresolutie”-methoden trainen computers om een scherp, gedetailleerd frame te voorspellen uit een frame van lage kwaliteit. Om deze vaardigheid te leren hebben ze veel voorbeelden nodig waarbij een vaag frame precies overeenkomt met dezelfde scène in hoge kwaliteit. Bestaande trainingsverzamelingen vertrouwen meestal op vereenvoudigde, kunstmatige beschadiging of op echte opnamen die niet precies uitgelijnd zijn tussen lage‑ en hoge‑kwaliteitsversies. De auteurs creëerden een nieuwe bron, CTOVSR, door te starten met vier traditionele operafilms die professioneel waren gerestaureerd van originele rollen en een zeer hoge resolutie bereikten. Vervolgens vonden ze bijpassende standaarddefinitieversies van dezelfde uitvoeringen die online waren uitgebracht. Deze versies van lagere kwaliteit hadden het volledige real‑world verouderingsproces doorgemaakt en waren daardoor ideale “voor” beelden.
Elk frame zorgvuldig uitlijnen
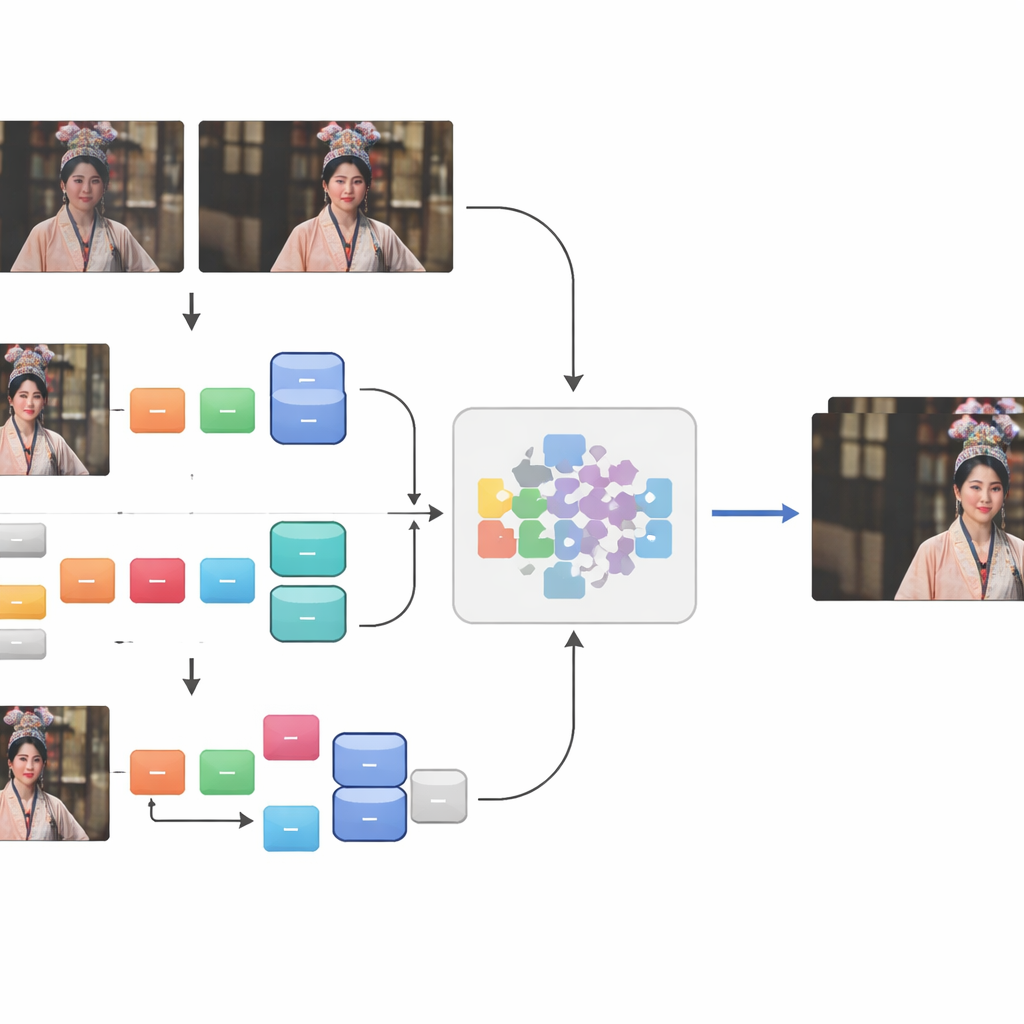
Het matchen van de gerestaureerde en de verouderde video’s was verre van eenvoudig. Verschillen in framerate, ontbrekende shots, toegevoegde watermerken, zwarte randen en verschuivende beeldverhoudingen betekenden dat eenvoudige automatische methoden niet volstonden. Het team extraheerde bruikbare segmenten en voerde daarna een zorgvuldige, driedelige uitlijning uit. Eerst gebruikten ze een aangepast hulpmiddel, eye_comparer, om handmatig timingproblemen te herstellen zoals frameverlies, frames in de verkeerde volgorde en “ghost” frames bij scènetransities. Vervolgens losten ze ruimtelijke mismatches op door frames in beeldbewerkingssoftware over elkaar te leggen, de inhoud precies uit te lijnen en randen, logo’s en ondertitels weg te snijden terwijl ze zo veel mogelijk van de scène behouden. Ten slotte voerden ze een automatische controle uit met een similariteitsmaat en behielden alleen frameparen die vrijwel identiek waren in structuur. Dit proces leverde 250 hoogwaardige real‑world sequentieparen op die honderden duizenden frames bestrijken.
Reële schade mengen met gesimuleerde slijtage
Hoewel deze zorgvuldig uitgelijnde paren echte, reële degradatie vastlegden, waren ze nog steeds te weinig om de volledige variëteit aan manieren waarop video kan verslechteren te dekken. Om het trainingsmateriaal te verbreden voegden de auteurs een tweede ingrediënt toe: synthetische schade toegepast op 41 aanvullende high‑definition operavideo’s. Ze simuleerden ruimtelijke schade — zoals onscherpte en ruis — via een tweefasige keten van degradatiestappen, en temporele schade door de video’s te comprimeren met een veelgebruikte oudere standaard die weerspiegelt hoe veel online clips historisch gecodeerd werden. Door dit synthetische gedeelte te fusen met de “Real‑world+” paren, stelden ze de CTOVSR‑dataset samen, die 900 strikt uitgelijnde laag‑hoog kwaliteitsvideoparen bevat, elk 100 frames lang en met een breed scala aan opera’s, scènes en lichtomstandigheden.
De waarde van de nieuwe collectie aantonen
Om te testen of CTOVSR computers daadwerkelijk helpt oude video’s te herstellen, trainden de auteurs meerdere state‑of‑the‑art superresolutiemodellen uitsluitend met deze dataset. Ze vergeleken de uitkomsten met eenvoudige herschaalmethoden en vonden dat de getrainde modellen veel duidelijkere beelden produceerden, met scherpere kostuumdetails, beter leesbare gezichtsschmink en minder zichtbare artefacten. Een ablatiestudie toonde aan dat het combineren van reële en synthetische schade aanzienlijk beter was dan het gebruik van slechts één van beide. De onderzoekers probeerden hun getrainde modellen ook op volledig nieuw materiaal: verouderde operaklips gevonden online en zelfs performancevideo’s uit andere culturen, zoals Italiaanse opera en Indiase klassieke dans. Menselijke beoordelaars waardeerden de verbeterde frames duidelijk hoger dan de originele of eenvoudig opgewaardeerde versies, wat suggereert dat modellen die op CTOVSR zijn getraind kunnen generaliseren voorbij het specifieke materiaal in de dataset.
Erfgoed bewaren met slimmer data‑gebruik
In eenvoudige bewoordingen introduceert dit werk niet opnieuw een herstelsalgoritme; het biedt in plaats daarvan het zorgvuldig voorbereide “oefenmateriaal” dat zulke algoritmen nodig hebben om te leren. Door beschadigde en hoogwaardige versies van traditioneel operamateriaal zorgvuldig te koppelen en ze vervolgens te verrijken met realistisch gesimuleerde slijtage, geeft de CTOVSR‑dataset kunstmatige intelligentie een veel beter begrip van hoe oude video’s vervallen en hoe ze eruit zouden moeten zien na herstel. Deze aanpak biedt een praktische weg om niet alleen het visuele leven van Chinese traditionele opera nieuw leven in te blazen, maar ook om vele andere vormen van onvervangbare historische video te beschermen tegen het wegvallen in digitale vergetelheid.
Bronvermelding: Xi, W., Qin, B., Zhang, Y. et al. A Chinese Traditional Opera Video Super-Resolution Dataset Based on the “Real-world+” Degradation Fusion. Sci Data 13, 387 (2026). https://doi.org/10.1038/s41597-026-06776-5
Trefwoorden: video-superresolutie, digitale behoud van erfgoed, Chinese traditionele opera, beeldherstel, gedegigreerde videodatasets