Clear Sky Science · nl
Een grootschalige perifere bloedcel-dataset voor geautomatiseerde hematologische analyse
Waarom bloedcelafbeeldingen ertoe doen
Elke routinematige bloedtest verbergt een microscopische wereld van cellen die infecties, bloedarmoede of zelfs bloedkankers kunnen onthullen, vaak lang voordat symptomen duidelijk worden. Artsen bekijken deze cellen traditioneel met het blote oog onder een microscoop, een nauwkeurig maar tijdrovend vakmanschap. Deze studie presenteert een zeer grote, zorgvuldig gelabelde verzameling bloedcelafbeeldingen die is bedoeld om computers te leren deze cellen automatisch te herkennen. Het doel is om toekomstige bloedtesten sneller, consistenter en breder toegankelijk te maken door kunstmatige intelligentie de visuele ervaring te geven die nodig is om artsen te helpen bloeduitstrijkjes nauwkeurig te beoordelen.
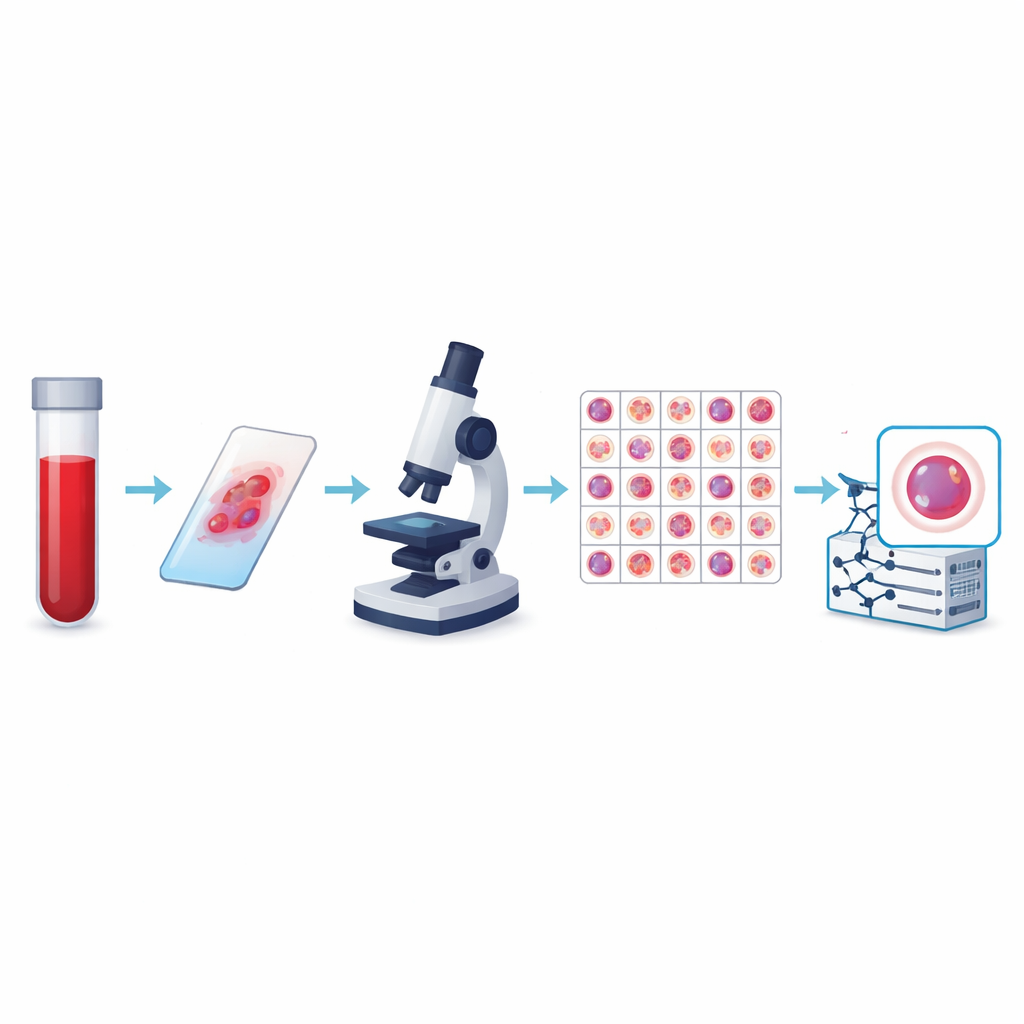
Van eenvoudige tellingen naar slimme beeldanalyse
Witte bloedcellen zijn belangrijke verdedigers in ons immuunsysteem en hun samenstelling en verschijningsvorm geven cruciale aanwijzingen over onze gezondheid. Een toename van bepaalde celtypen kan wijzen op een infectie of allergie, terwijl de plotselinge aanwezigheid van onrijpe “blast”-cellen kan waarschuwen voor leukemie. Laboratoria gebruiken al geautomatiseerde apparaten om cellen te tellen, maar subtiele vormveranderingen vereisen vaak nog het oog van een expert. Menselijke beoordelaars kunnen van mening verschillen en het één voor één bekijken van preparaten kost tijd. Nu de geneeskunde steeds meer leunt op digitale beeldvorming en kunstmatige intelligentie, is er een groeiende behoefte aan grote, betrouwbare beeldverzamelingen die computers kunnen trainen om deze karakteristieke cellenpatronen net zo betrouwbaar te herkennen als een ervaren hematoloog.
Het bouwen van een enorme bibliotheek van bloedcellen
De auteurs creëerden wat momenteel de grootste openbare verzameling perifere bloedcelafbeeldingen is, de KU-Optofil PBC-dataset. Deze bevat 31.489 hoge-resolutiefoto’s van individuele cellen verdeeld over 13 groepen, waaronder veelvoorkomende verdedigers zoals lymfocyten en gesegmenteerde neutrofielen, maar ook zeldzamere maar medisch kritieke typen zoals blasts, myelocyten en reactieve lymfocyten. Alle afbeeldingen zijn afkomstig van gekleurde bloeduitstrijkjes die onder gestandaardiseerde condities in één ziekenhuis zijn voorbereid en met hetzelfde beeldvormingssysteem zijn gefotografeerd. Die consistentie zorgt ervoor dat computers die van de data leren een stabiele, goed gecontroleerde weergave van elk celtype zien in plaats van een lappendeken van incompatibele beelden.
Expert-oog en zorgvuldige curatie
Om de dataset betrouwbaar te maken, is elke afbeelding onafhankelijk gelabeld door twee ervaren laboratoriummedewerkers, waarbij een derde expert eventuele meningsverschillen beslechtte. Statistische controles toonden zeer sterke overeenstemming tussen beoordelaars voor elk belangrijk celtype, inclusief perfecte overeenstemming voor sommige typen. Het team hanteerde ook strikte regels om te beslissen welke afbeeldingen behouden werden en verwijderde wazige, overlappende of slecht gekleurde cellen. De uiteindelijke afbeeldingen hebben allemaal dezelfde afmetingen en kleurformaat en zijn georganiseerd in trainings-, validatie- en testmappen zodat andere onderzoekers algoritmen eerlijk kunnen vergelijken. Extra bestanden koppelen elke afbeelding aan een anonieme patiënt, wat studies mogelijk maakt die testen of een model echt generaliseert van de ene persoon naar de andere.
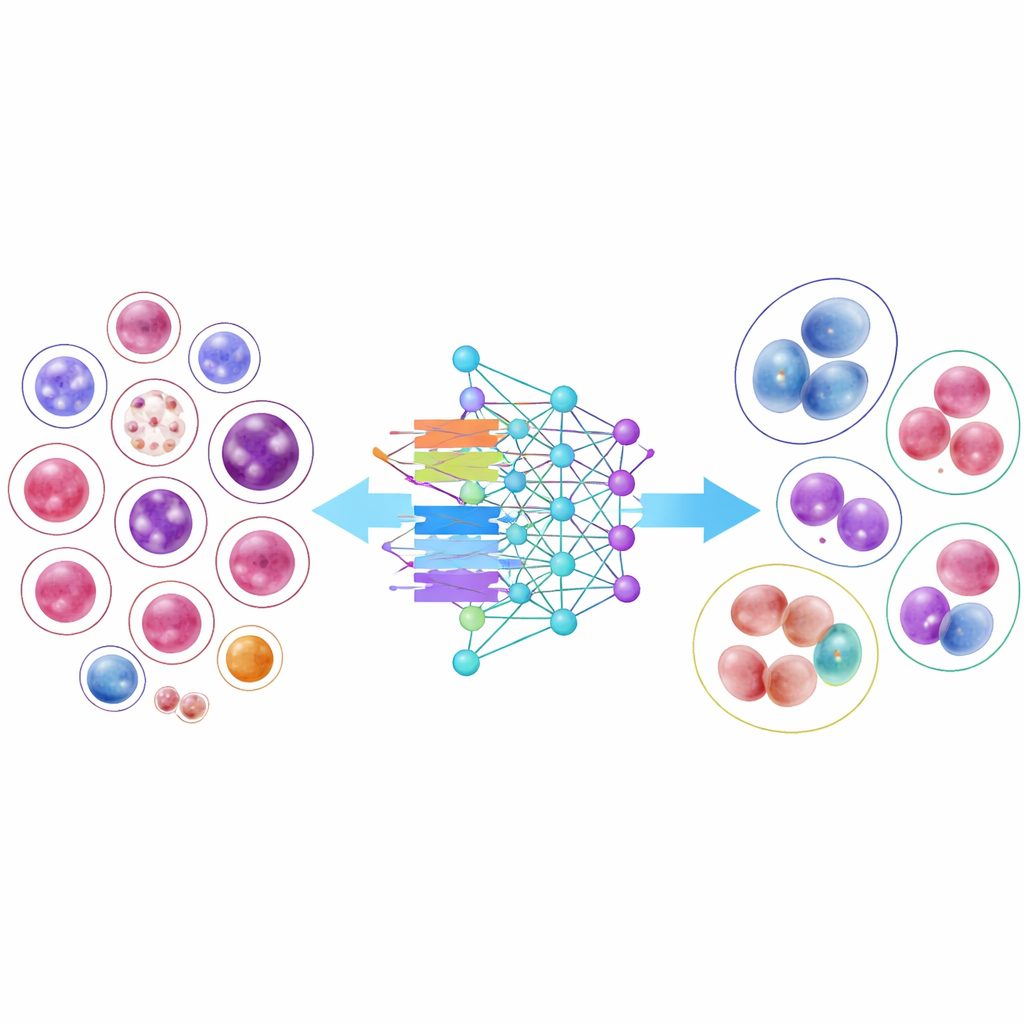
AI-modellen op de proef stellen
Om aan te tonen hoe nuttig deze bibliotheek kan zijn, trainden de onderzoekers 14 moderne beeldherkenningsmodellen, van klassieke convolutionele neurale netwerken tot nieuwere transformer-gebaseerde ontwerpen. Verschillende compacte, efficiënte modellen presteerden verrassend goed, en één architectuur, DenseNet-121, classificeerde cellen in gemiddeld meer dan 95 procent van de gevallen correct. De resultaten lieten echter ook een belangrijke praktische uitdaging zien: veelvoorkomende celtypen met duizenden voorbeelden werden vrijwel perfect herkend, terwijl zeer zeldzame cellen met slechts enkele tientallen afbeeldingen veel moeilijker te classificeren bleven. Zelfs wanneer de onderzoekers de training aanpasten om meer nadruk te leggen op deze schaarse klassen, daalde de algehele nauwkeurigheid en waren de verbeteringen voor zeldzame typen bescheiden, wat het probleem benadrukt van leren uit beperkte voorbeelden.
Wat dit betekent voor toekomstige bloedtesten
Voor niet-specialisten is de kernboodschap dat dit werk de ruwe visuele ervaring levert die computersystemen nodig hebben om betrouwbare partners te worden bij het lezen van bloeduitstrijkjes. Door een grote, diverse en zorgvuldig gecontroleerde bibliotheek van bloedcelafbeeldingen samen te stellen en aan te tonen dat veel verschillende AI-modellen ervan kunnen leren, leggen de auteurs de basis voor hulpmiddelen die diagnoses kunnen versnellen, menselijke fouten kunnen verminderen en expertise toegankelijker kunnen maken voor klinieken met minder specialisten. Tegelijkertijd herinneren de gemengde resultaten bij zeldzame celtypen ons eraan dat zelfs grote datasets blinde vlekken hebben en dat het verbeteren van de zorg voor patiënten met ongebruikelijke of vroegstadige aandoeningen verdere uitbreiding en verfijning van deze beeldverzamelingen vereist.
Bronvermelding: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Trefwoorden: beeldvorming van bloedcellen, medische AI, hematologie, deep learning, medische datasets