Clear Sky Science · nl
BRISC: Geannoteerde dataset voor segmentatie en classificatie van hersentumoren
Waarom hersenscangegevens voor iedereen belangrijk zijn
Hersentumoren behoren tot de engste diagnoses die iemand kan krijgen, en artsen vertrouwen steeds vaker op computerprogramma’s om deze gevaarlijke gezwellen in MRI-scans te detecteren en af te bakenen. Maar net als studenten die uit een leerboek met ontbrekende bladzijden moeten leren, worden veel van de huidige systemen voor kunstmatige intelligentie (AI) geremd door onvolledige of inconsistente gegevens. Dit artikel introduceert BRISC, een nieuw zorgvuldig samengesteld corpus van hersen‑MRI‑beelden dat medische AI de hoogwaardige voorbeelden biedt die nodig zijn om tumoren beter te detecteren en in kaart te brengen — werk dat uiteindelijk kan bijdragen aan snellere, betrouwbaardere diagnoses. 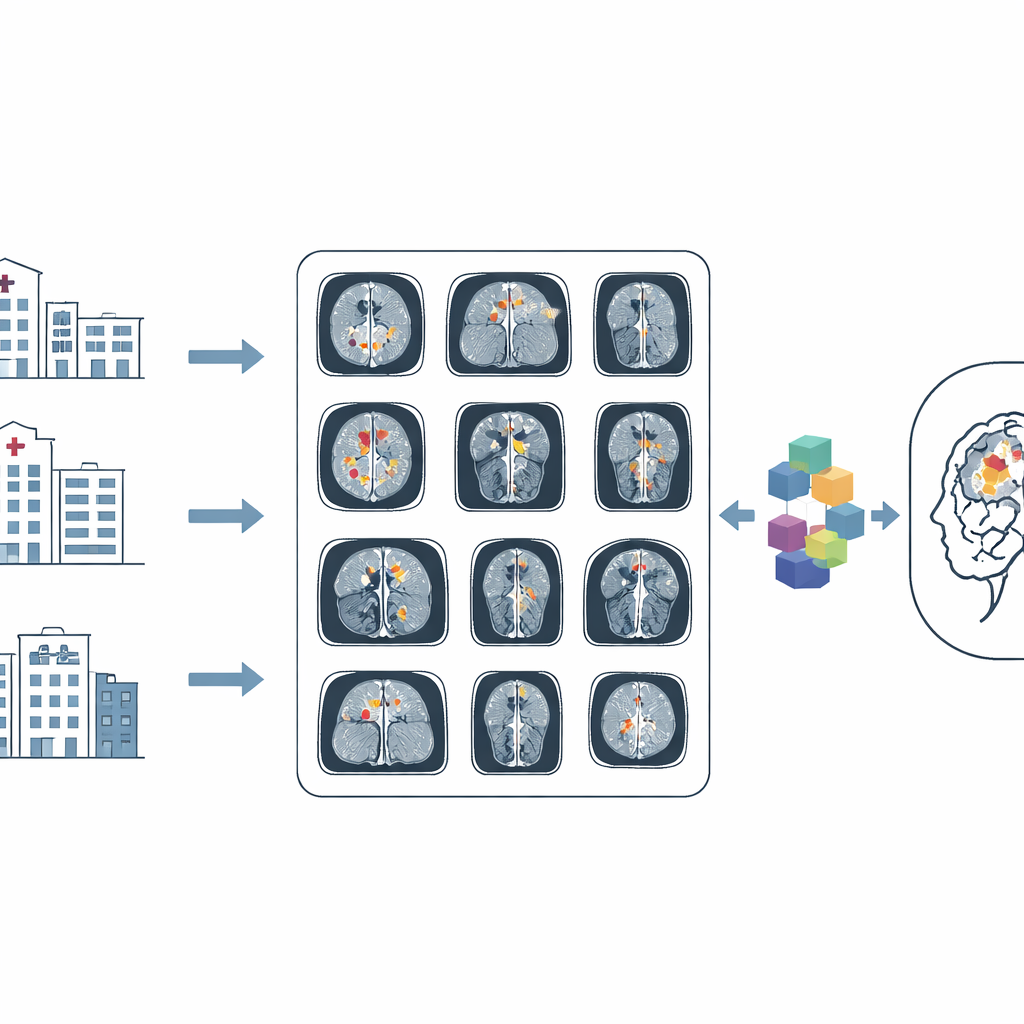
Een nieuwe bibliotheek van hersenbeelden
De BRISC‑dataset verzamelt 6.000 MRI‑hersenscans gericht op één specifiek type opname — contrastversterkte T1‑gewogen beelden — die bijzonder geschikt zijn om tumorranden goed zichtbaar te maken. Elk beeld valt in een van vier groepen: drie veelvoorkomende tumortypen (glioma, meningeoom en hypofysetumoren) plus een niet‑tumorgroep die gezonde hersenen en andere niet‑kankerachtige aandoeningen omvat. De beelden zijn afkomstig uit meerdere eerder gepubliceerde publieke collecties, maar BRISC voegt toe wat die oudere sets grotendeels misten: nauwkeurige contouren van de tumorregio’s en consistente labels, gemaakt en gecontroleerd door medische experts.
Balanceren van gezichtspunten en tumortypen
Een belangrijk probleem bij veel bestaande collecties is onevenwichtigheid: sommige tumortypen of scanhoeken domineren, waardoor AI‑modellen slechts goed presteren op de meest voorkomende patronen die ze zien. BRISC pakt dit aan door een gelijkmatigere verdeling van zowel diagnoses als kijkrichtingen te ontwerpen. Beelden worden geleverd in drie standaard MRI‑vlakken — axiaal (van bovenaf), coronair (van voor naar achter) en sagittaal (van opzij) — met vergelijkbare aantallen in elk vlak. De vier diagnosecategorieën worden ook relatief evenwichtig gehouden in de trainings‑ en testverdelingen. Dit zorgvuldige ontwerp helpt toekomstige algoritmen tumoren vanuit meerdere hoeken en in een breder scala aan situaties te herkennen, en weerspiegelt beter wat artsen in de kliniek daadwerkelijk zien.
Zorgvuldig opschonen en deskundige afbakening
Het omzetten van ruwe scans naar een betrouwbaar onderzoeksbestand vereiste aanzienlijke schoonmaakwerkzaamheden. Het team begon met meer dan 7.000 beelden afkomstig uit een populaire online hersentumorcollectie en verwijderde beelden van slechte kwaliteit of corrupte scans, bijna‑duplicaten en reeksen die te kort waren voor betrouwbare interpretatie. Alleen contrastversterkte T1‑scans werden behouden om consistentie te waarborgen. Artsen en een radioloog beoordeelden vervolgens de beelden, corrigeerden foutieve labels en verwijderden twijfelachtige gevallen. Met een gespecialiseerd labelgereedschap tekenden ze gedetailleerde maskers rond tumorregio’s en verfijnden hun werk herhaaldelijk totdat ze sterke overeenstemming bereikten; op een testsubset was de overeenkomst tussen de eerste en de door experts goedgekeurde contouren zeer hoog. 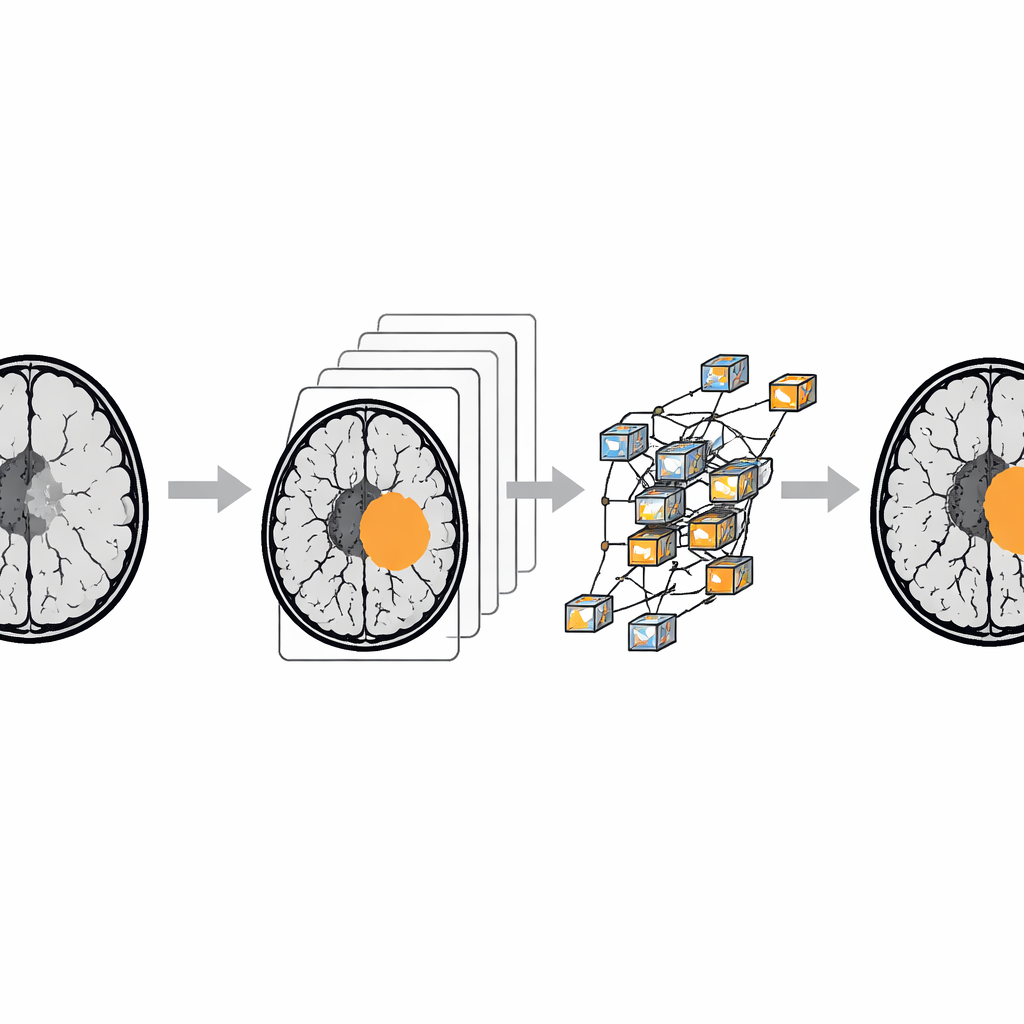
Wat de data mogelijk maakt voor AI‑modellen
Om te laten zien hoe BRISC kan worden gebruikt, trainden de auteurs een reeks populaire AI‑modellen op twee taken. De eerste taak vraagt een model elk beeld in te delen in een van de vier diagnosecategorieën. Moderne beeldherkenningssystemen, met name de EfficientNet‑familie, bereikten zeer hoge nauwkeurigheid — ze labelden de overgrote meerderheid van de scans correct en presteerden bijzonder goed bij het onderscheiden van beelden zonder tumor. De tweede taak vraagt modellen het tumorgebied pixel voor pixel in te kleuren op de MRI‑slice. Hier behaalden meer geavanceerde segmentatienetwerken, waaronder transformer‑gebaseerde architecturen die uitblinken in het modelleren van context, de beste scores en tekenden ze tumoren nauwkeurig af over de drie belangrijkste tumortypen.
Hoe dit werk het veld verder brengt
Simpel gezegd is BRISC een goed georganiseerde, openbare "oefenplaats" voor computers die leren hersen‑MRI’s te lezen. Het biedt duizenden zorgvuldig geschoonde scans, realistische variatie in tumortypen en kijkhoeken, en door experts getekende tumorcontouren die algoritmen precies leren waar ziekte aanwezig is. Hoewel de dataset bedoeld is voor onderzoek — en niet als zelfstandige diagnostische tool voor patiënten — vormt het een solide basis voor het bouwen en vergelijken van nieuwe AI‑systemen. Naarmate onderzoekers modellen verfijnen met BRISC en soortgelijke bronnen, kunnen artsen mogelijk op een dag meer betrouwbare digitale assistenten naast zich hebben, die helpen hersentumoren vroeger op te sporen en behandelingen met grotere zekerheid te plannen.
Bronvermelding: Fateh, A., Rezvani, Y., Moayedi, S. et al. BRISC: Annotated Dataset for Brain Tumor Segmentation and Classification. Sci Data 13, 361 (2026). https://doi.org/10.1038/s41597-026-06753-y
Trefwoorden: MRI hersentumor, medische beeldvorming AI, tumorsegmentatie, datasetchurn, radiologie deep learning