Clear Sky Science · nl
Een dataset met histopathologiebeelden bij hoge vergroting voor de diagnose en prognose van plaveiselcelcarcinoom van de mond
Waarom dit onderzoek ertoe doet
Mondkanker kan onopvallend beginnen, als een klein zweertje in de mond dat uitgroeit tot een levensbedreigende aandoening. Artsen vertrouwen op microscoopbeelden van weefsel om te bepalen hoe ernstig een tumor is en hoe waarschijnlijk het is dat deze terugkeert of uitzaait, maar het lezen van deze beelden is traag en veeleisend. Deze studie introduceert een rijke nieuwe beeldverzameling die bedoeld is om systemen voor kunstmatige intelligentie (AI) te helpen deze preparaten samen met pathologen te interpreteren, met als langetermijndoel patiënten sneller en nauwkeuriger antwoord te geven over hun ziekte en behandelingsopties.
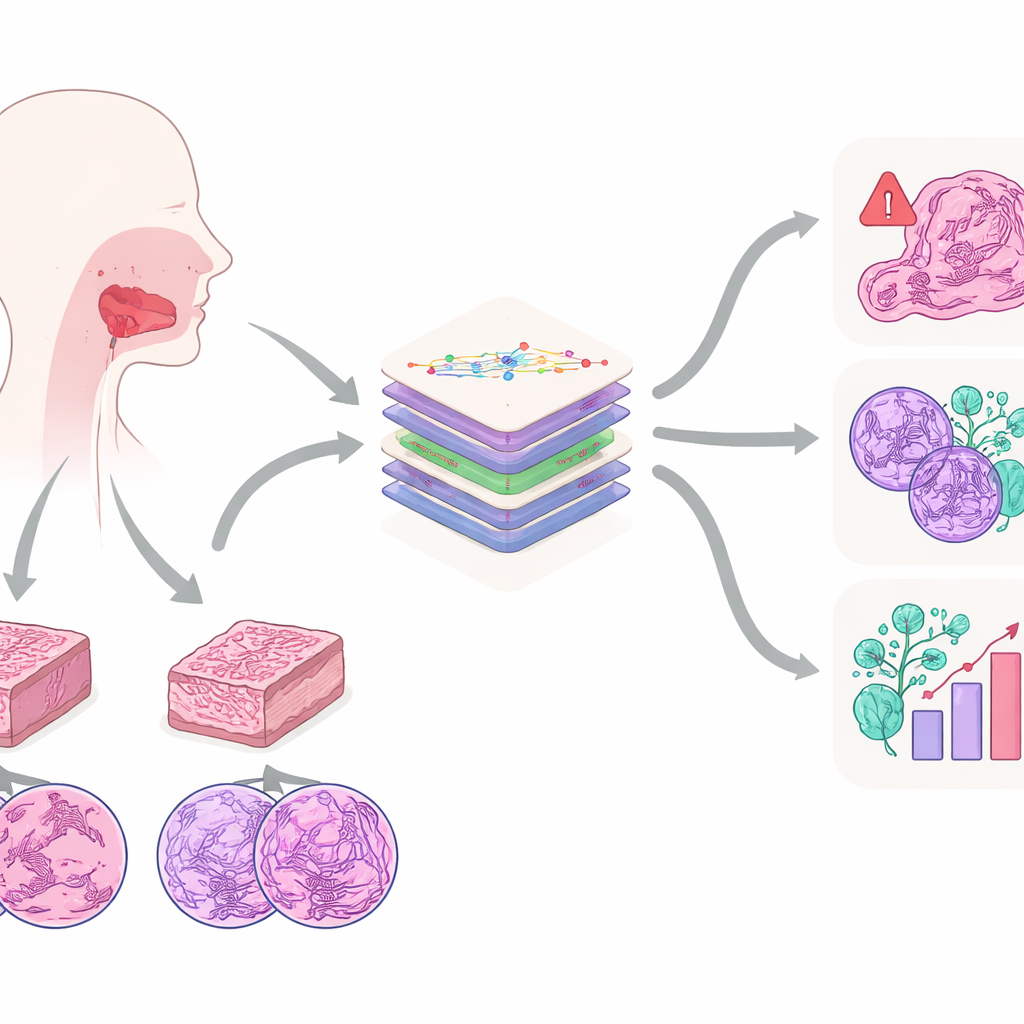
Een nadere blik op een veelvoorkomende mondkanker
Het werk richt zich op plaveiselcelcarcinoom van de mond, een van de meest voorkomende en agressieve vormen van mondkanker. Het ontstaat vaak bij mensen met een voorgeschiedenis van tabak- of alcoholgebruik en kan zich verspreiden naar omliggende weefsels en lymfeklieren in de hals. Tegenwoordig is de gouden standaard voor diagnose nog steeds het oog van de patholoog op gekleurde weefselplakjes onder de microscoop. Uit deze plakjes beoordelen experts hoe abnormaal de cellen eruitzien, hoe diep de tumor is gegroeid, of hij zenuwen of bloedvaten heeft ingenomen, en vele andere kenmerken die de overleving beïnvloeden. De auteurs stellen dat deze microscopische patronen veel meer informatie bevatten dan een mens gemakkelijk kan bijhouden, waardoor ze een ideaal doelwit vormen voor moderne AI.
Een rijker beeld bouwen uit weefselbeelden
Om deze informatie te ontsluiten, maakte het team de Multi‑OSCC‑dataset: microscoopbeelden van 1.325 patiënten die tussen 2015 en 2022 in één ziekenhuis behandeld werden voor mondkanker. Voor elke patiënt bereidden pathologen twee weefselblokken voor—één uit het midden van de tumor en één van de invasieve rand—en legden vervolgens hoge‑resolutiebeelden vast op drie zoomniveaus, vergelijkbaar met het bekijken van een stad vanuit een vliegtuig, vanaf een dak en vanaf een straathoek. Dit leverde zes zorgvuldig gekozen beelden per patiënt op, elk met sleutelstructuren zoals nestjes kankercellen, concentraties keratine en sterk afwijkende celkernen. Naast de beelden verzamelden de onderzoekers gedetailleerde medische dossiers en langetermijnfollow‑up om te bepalen welke tumoren terugkeerden of uitzaaiden.
Zes vragen die artsen echt belangrijk vinden
Wat Multi‑OSCC onderscheidt, is dat het echte klinische vragen weerspiegelt in plaats van te focussen op één enkel label. Elke patiënt in de dataset is geannoteerd voor zes belangrijke uitkomsten. Een daarvan is of de tumor binnen twee jaar na de operatie terugkeerde, een kritieke periode waarin de meeste recidieven optreden. Een andere is of kankercellen al in de halslymfeklieren waren doorgebroken, wat beslissingen over uitgebreide nekoperaties stuurt. Vier aanvullende labels brengen in kaart hoe goed-gedifferentieerd de tumorcellen zijn, hoe diep de tumor infiltreert en of deze bloedvaten heeft betrokken of langs zenuwen is gegroeid—subtiele maar krachtige aanwijzingen voor hoe gevaarlijk de tumor is. Dit ontwerp stelt AI‑modellen in staat niet alleen te leren “kanker versus normaal,” maar een vollediger portret van risico en ernst.
AI leren complexe preparaten te lezen
De onderzoekers evalueerden vervolgens hoe verschillende AI‑strategieën met deze veeleisende dataset omgaan. Ze vergeleken verschillende moderne beeldherkenningsbackbones, waaronder klassieke convolutionele netwerken en nieuwere transformer‑gebaseerde modellen, en vonden dat transformermodellen die specifiek op pathologiebeelden waren voorgetraind het beste presteerden. Ze testten manieren om informatie van de zes beelden per patiënt te combineren en ontdekten dat een eenvoudige strategie—kenmerken uit elk beeld extraheren en deze vervolgens concatenëren—beter werkte dan meer geavanceerde fusieschema's. Ook onderzochten ze hoe kleurstandaardisatie van de kleuring de prestaties beïnvloedde, waarbij bleek dat het behoud van de originele kleur cruciaal was voor het voorspellen van terugkeer, terwijl milde kleurnormalisatie hielp bij de andere diagnostische taken.
Beperkingen, verrassingen en wat volgt
Een verrassing was dat het trainen van één enkel AI‑model om alle zes vragen tegelijk aan te pakken nog niet beter presteerde dan modellen die afzonderlijk voor elke taak waren getraind. Een andere was dat gedetailleerde microscooppatches, hoewel rijk aan cellulaire details, nog steeds het brede architecturale beeld missen dat volledige‑slidebeelden bieden. Desondanks presteerden modellen die op de Multi‑OSCC‑beelden waren getraind duidelijk beter dan modellen die alleen klinische gegevens zoals leeftijd, gewoonten en medische voorgeschiedenis gebruikten, vooral bij het voorspellen van tumorrecidief. De auteurs positioneren Multi‑OSCC als een beginpunt: een openbare, goed gedocumenteerde dataset die anderen kunnen gebruiken om methoden te ontwikkelen en te vergelijken. Voor patiënten is de langetermijnbelofte dat toekomstige hulpmiddelen die op deze bron zijn gebouwd artsen kunnen helpen betrouwbaarder te signaleren welke mondkankers waarschijnlijk zullen terugkeren of uitzaaien, wat leidt tot meer op maat gemaakte behandelingen en uiteindelijk betere overlevingskansen.
Bronvermelding: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Trefwoorden: mondkanker, histopathologiebeelden, kunstmatige intelligentie, deep learning, datasets voor medische beeldvorming