Clear Sky Science · nl
StatLLM: Een dataset voor het evalueren van de prestaties van grote taalmodellen bij statistische analyse
Waarom dit van belang is voor dagelijkse datagebruikers
Nu kunstmatige intelligentiehulpmiddelen zoals chat‑gebaseerde assistenten deel uitmaken van het dagelijkse werk, vragen steeds meer mensen deze systemen om cijfers te berekenen, experimenten uit te voeren en gegevens te analyseren. Maar wanneer een AI de code voor een statistische studie schrijft—bijvoorbeeld om te controleren of een nieuwe medische behandeling werkt of om schoolprestaties te onderzoeken—hoe weten we dan of het werk correct is gedaan? Dit artikel introduceert StatLLM, een publieke dataset ontworpen om te testen hoe goed grote taalmodellen omgaan met echte statistische analysetaken, waardoor onderzoekers en praktijkmensen een helderder beeld krijgen van wanneer AI‑geschreven code te vertrouwen is en wanneer voorzichtigheid geboden is.
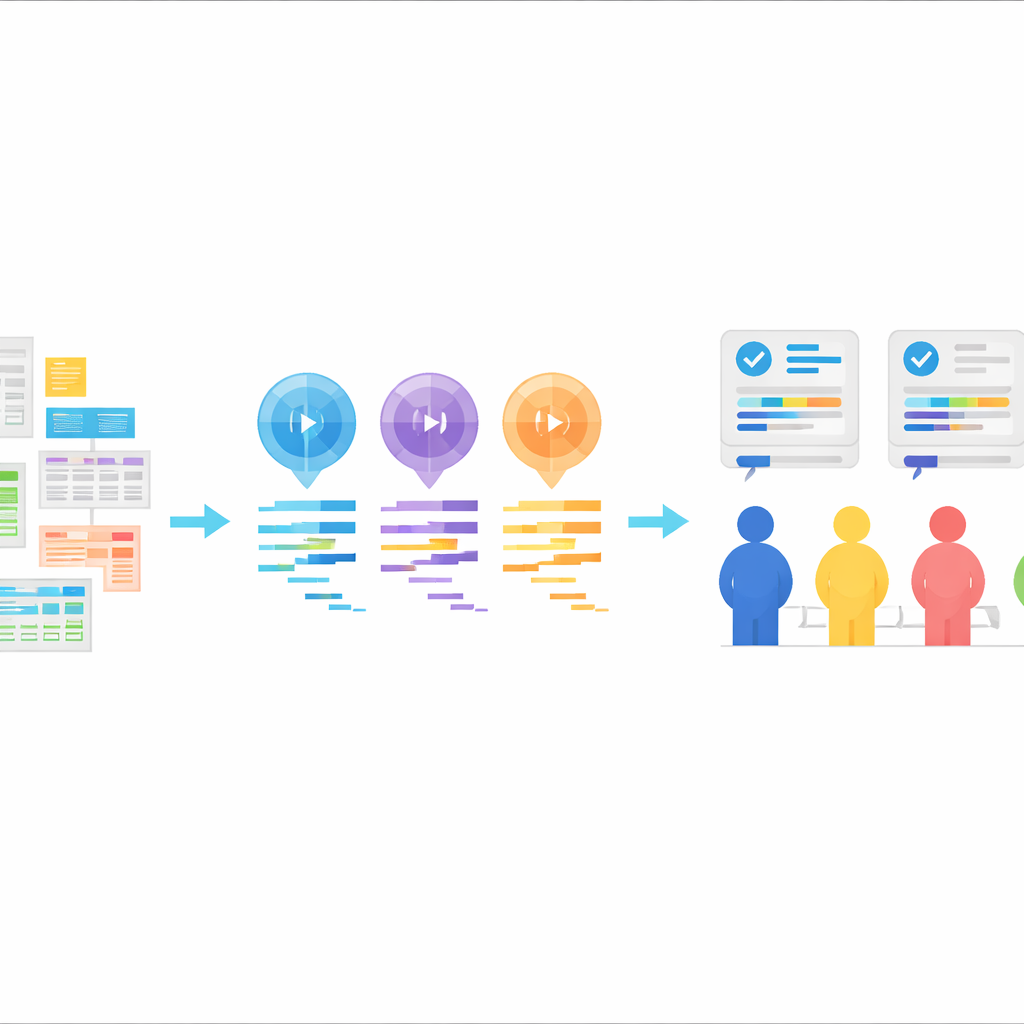
Een nieuwe testomgeving voor door AI geschreven statistische code
De kern van StatLLM is een zorgvuldig samengestelde verzameling van 207 statistische analysetaken, opgebouwd uit 65 echte datasets uit vakgebieden zoals onderwijs, geneeskunde, bedrijfsleven, financiën, techniek en sport. Elke taak bevat een probleembeschrijving in gewone taal, een gedetailleerde uitleg van de dataset en de variabelen, en een kort SAS‑script dat door menselijke experts is geschreven en geverifieerd. De taken bestrijken wat een sterke bachelor‑ of masterstudent statistiek zou leren: van eenvoudige gegevenssamenvattingen en grafieken tot regressieanalyses, overlevingsanalyse en meer geavanceerde methoden. Dit biedt een realistische test in klaslokaal‑ en industriesetting om te beoordelen of AI‑hulpmiddelen praktische vragen begrijpen en vertalen naar verantwoorde analysetappen.
AI de code laten schrijven en die vervolgens nakijken
Middels deze taken lieten de auteurs drie grote taalmodellen—GPT‑3.5, GPT‑4 en Llama‑3.1 70B—SAS‑code genereren. Elk model kreeg dezelfde ingrediënten: een beschrijving van de taak, een beschrijving van de dataset, het daadwerkelijke data‑bestand en een expliciete instructie om SAS‑code te produceren. De modellen werden in een “zero‑shot” opzet gebruikt, wat betekent dat ze vooraf geen voorbeelden van correcte SAS‑code te zien kregen. Hun reacties werden opgeschoond zodat alleen de code overbleef, zonder verklarende tekst. Deze opzet bootst een veelvoorkomend praktijkpatroon na: een gebruiker beschrijft wat hij wil, de AI levert code, en die code wordt vervolgens uitgevoerd in een statistisch pakket.
Menselijke experts als gouden standaard
Om te beoordelen hoe goed de door AI geschreven code werkelijk was, organiseerde het team een rigoureuze menselijke beoordeling. Negen ervaren SAS‑gebruikers vormden drie groepen, die elk op één aspect van de prestatie focusten: of de code logisch correct en leesbaar was, of deze daadwerkelijk zonder fouten draaide, en of de resulterende output de oorspronkelijke vraag duidelijk en juist beantwoordde. Voor elke taak werden de SAS‑programma’s van de drie modellen door elkaar gehusseld zodat de beoordelaars niet konden zien welk model welke code had geproduceerd. Scores werden toegekend op een schaal van vijf punten en gecombineerd tot een totaalscore, wat een genuanceerd beeld geeft van sterke en zwakke punten over honderden model–taakcombinaties. Deze expertbeoordelingen zijn nu beschikbaar naast alle code en taken in de StatLLM‑dataset.
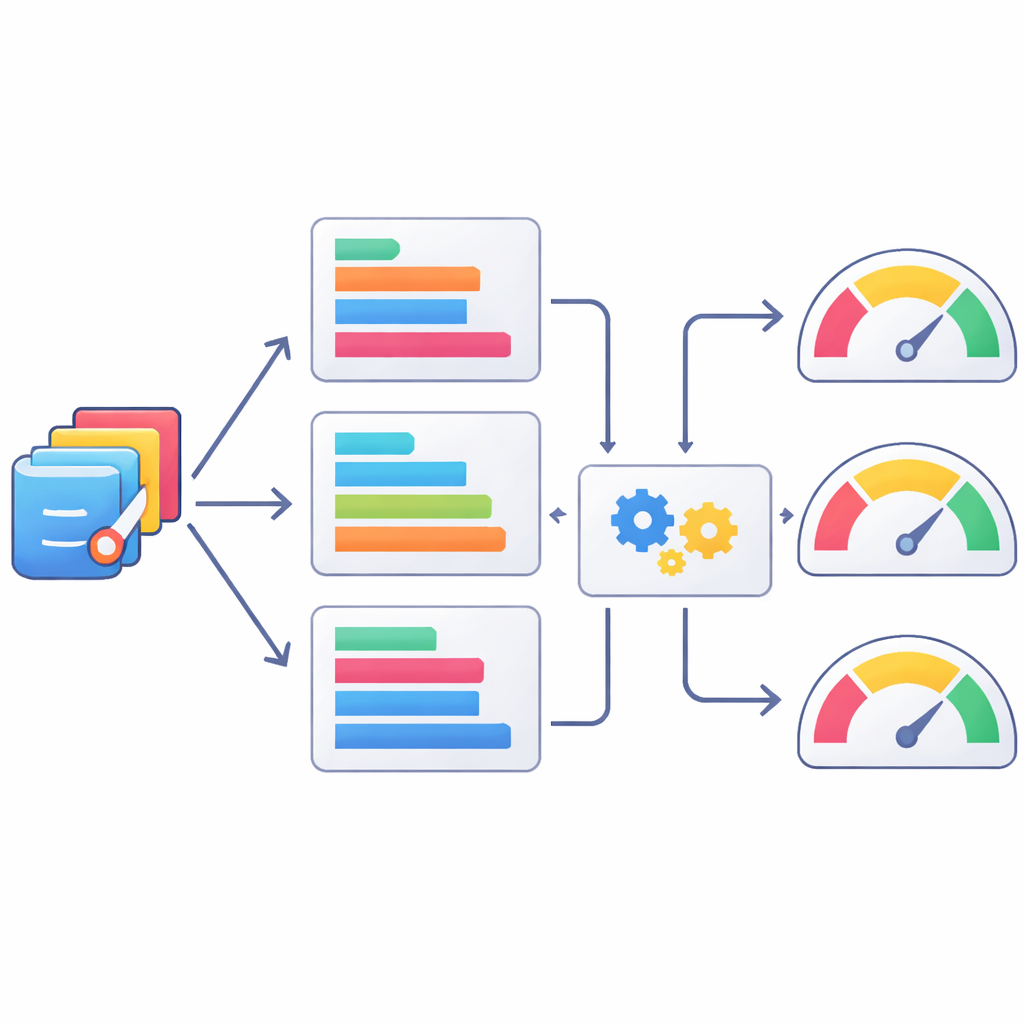
Machines leren code te beoordelen zoals mensen dat doen
Aangezien menselijke beoordeling traag en duur is, onderzochten de auteurs ook hoe goed automatische, op tekst gebaseerde metriek als ruwe beoordelaars van statistische codekwaliteit kunnen fungeren. Ze vergeleken AI‑gegenereerde SAS‑programma’s met de door mensen geverifieerde versies met behulp van een reeks bekende natural language processing‑scores en controleerden vervolgens hoe deze scores zich verhouden tot de menselijke beoordelingen. Sommige metrieken, zoals varianten van de ROUGE‑score die overlap in korte tokenreeksen volgen, correleerden beter met menselijke oordelen dan andere, maar allemaal lieten ze slechts een matige overeenstemming zien. Het team ging een stap verder en trainde machine‑learningmodellen om menselijke scores te voorspellen uit combinaties van deze metrieken. Methoden zoals XGBoost verbeterden de aansluiting bij menselijke beoordelingen, maar bleven ver verwijderd van het perfect vastleggen van expertsch oordeel, wat benadrukt dat automatische scores hooguit gedeeltelijke proxies zijn.
Bouwen aan toekomstige door AI aangedreven statistische hulpmiddelen
Naast benchmarking laten de auteurs zien hoe StatLLM nieuwe hulpmiddelen en onderzoekslijnen kan ondersteunen. Omdat elke taak in algemene termen is beschreven, kunnen dezelfde problemen worden gebruikt om codegeneratie in andere talen te testen, zoals R of Python, of zelfs om code uit meerdere talen te combineren. Het artikel belicht ensemble‑benaderingen die verschillende door AI gegenereerde oplossingen kunnen mixen voor grotere betrouwbaarheid, en demonstreert een prototype van een R Shiny‑app waarin gebruikers een dataset en taakbeschrijving uploaden en een AI‑systeem automatisch R‑code genereert en uitvoert. StatLLM biedt ook een platform om next‑generation statistische software te ontwerpen en te testen die natuurlijke taalinstructies begrijpt en aan duidelijke, meetbare standaarden wordt gehouden.
Wat dit betekent voor het gebruik van AI in dataanalyse
Voor niet‑specialisten is de belangrijkste conclusie dat AI al korte stukjes statistische code kan schrijven—maar betrouwbaarheid is verre van gegarandeerd, vooral bij taken die verder gaan dan eenvoudige voorbeelden. StatLLM biedt een transparante, herbruikbare manier om te zien hoe goed verschillende modellen presteren, om automatische controles op hun werk te verbeteren en om veiligere, robuustere data‑analysetools te ontwerpen. Naarmate nieuwere taalmodellen verschijnen, kunnen ze in deze levende benchmark worden ingeplugd, waardoor het veld eerlijk blijft over wat AI wel en nog niet kan in serieuze statistische werkzaamheden.
Bronvermelding: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Trefwoorden: grote taalmodellen, statistische analyse, code-evaluatie, benchmark-dataset, SAS-programmering