Clear Sky Science · nl
Een Chinese Named Entity Recognition-dataset voor immaterieel cultureel erfgoed
Waarom het beschermen van levende tradities slimme lezing vereist
Over de hele wereld lopen levende tradities zoals volksmuziek, ambachtelijke technieken en lokale festivals het risico uit het dagelijks leven te verdwijnen. In China bestaan al enorme hoeveelheden tekst die deze praktijken beschrijven, maar het merendeel staat op lange webpagina’s die voor mensen — of computers — moeilijk te doorzoeken en te analyseren zijn. Deze studie introduceert een zorgvuldig opgebouwde Chinese dataset en een geavanceerd kunstmatig‑intelligentiemodel dat automatisch belangrijke informatie in die teksten kan herkennen, zoals namen van ambachten, meester‑ambachtslieden, materialen en plaatsen. Samen bieden ze nieuwe hulpmiddelen om immaterieel cultureel erfgoed op digitale schaal te behouden en te bestuderen.
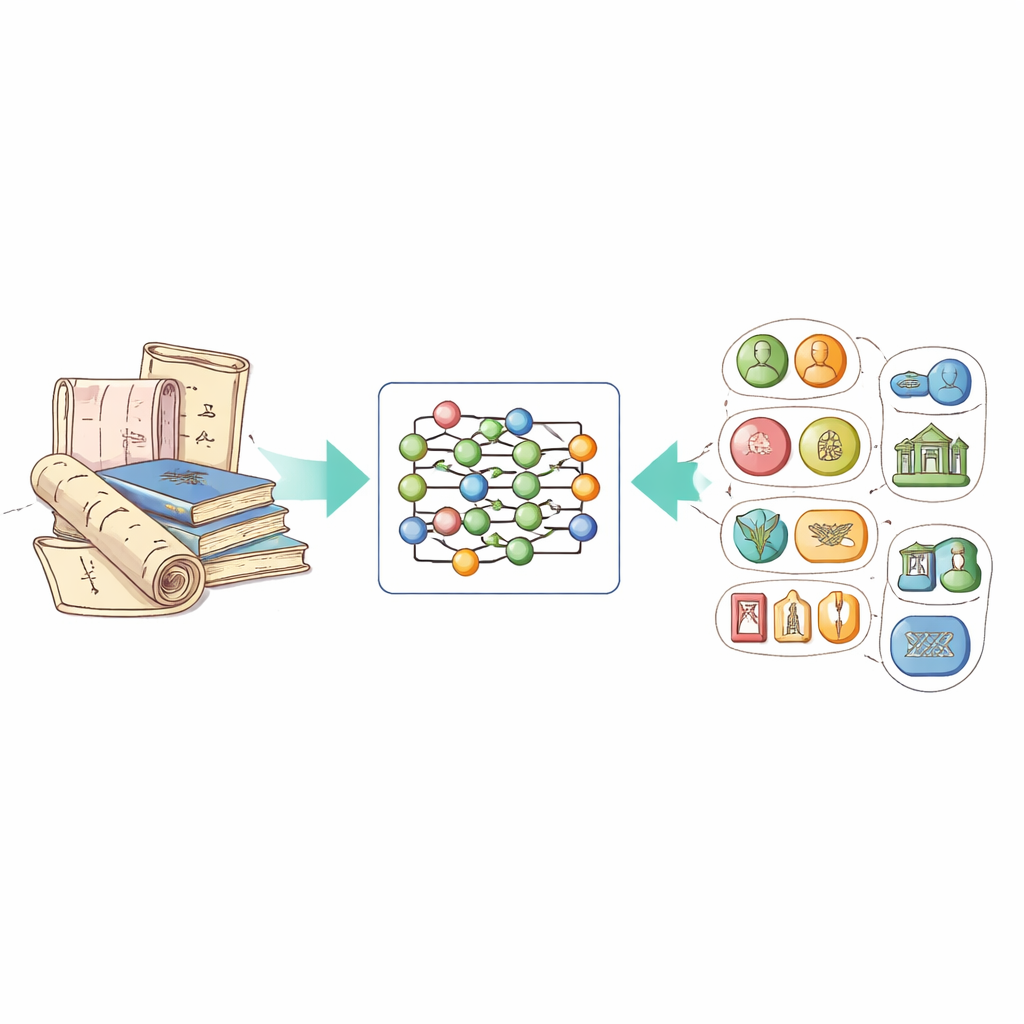
Rommelige tekst aan gestructureerde kennis koppelen
De kern van het werk is een techniek genaamd named entity recognition, waarmee computers worden geleerd om belangrijke elementen in tekst aan te duiden: personen, locaties, tijden, organisaties, enzovoort. Voor immaterieel cultureel erfgoed betekent dit ook het herkennen van specifieke entiteitstypen zoals de namen van erfgoedprojecten, bepaalde ambachtstechnieken en de materialen die worden gebruikt. Het probleem was dat er tot nu toe geen publieke dataset in het Chinees bestond die op dit domein was toegesneden, en dat algemene systemen moeite hadden met levendige beschrijvingen, poëtische bewoordingen en regionale uitdrukkingen die in erfgoedteksten voorkomen.
Een gerichte verzameling erfgoedteksten opbouwen
Om dit tekort op te vullen, stelden de auteurs een nieuwe dataset samen, ICH‑NER genaamd, gebaseerd op China’s officiële Intangible Cultural Heritage Network. Zij concentreerden zich op ambachtsgerelateerde inzendingen — zoals traditionele textiel, keramiek, metaalbewerking en houtsnijwerk — omdat deze beschrijvingen rijk zijn aan details over processen en materialen. Na het verwijderen van mededelingen en duplicaten ontwierpen ze acht hoofd categorieën entiteiten: erfgoedobjectnamen, locaties, personen, organisaties, tijdsperioden, etnische groepen, materialen en ambachtstechnieken. Elk Chinees karakter in de teksten werd gelabeld met een eenvoudige code die aangeeft of het deel uitmaakt van een entiteit en, zo ja, van welk type. In totaal bevat de dataset 7.779 voorbeelden en meer dan 21.000 gelabelde entiteiten, wat het tot een solide benchmark voor toekomstig onderzoek maakt.
Zorgvuldige richtlijnen voor consistente labelings
Aangezien er geen standaard classificatiesysteem bestond voor dit soort erfgoedteksten, hebben de onderzoekers eerst gedetailleerde richtlijnen opgesteld op basis van nationale erfgoedlijsten en officiële beschrijvingen. Ze voerden een pilotfase uit om lastige gevallen af te handelen, zoals plaatsen die ook deel uitmaken van projectnamen of geneste zinsdelen waarin de ene entiteit in de andere zit. Een enkele getrainde annotator labelde vervolgens de gehele dataset met open‑source software en bekeek eerder werk herhaaldelijk opnieuw om inconsistenties te corrigeren. De uiteindelijke data zijn gesplitst in trainings‑ en ontwikkelsets, waarbij erop gelet is dat elk entiteitstype in vergelijkbare verhoudingen voorkomt en dat beide delen een goede mix van regionale termen en schrijfstijlen bevatten.
Een AI‑model ontworpen voor erfgoedtaal
Naast de dataset stelt de studie een gespecialiseerd herkenningsmodel voor dat meerdere moderne AI‑componenten stapelt. Eerst zet een krachtig taalencoder (RoBERTa) de Chinese karakters om in contextbewuste numerieke representaties die weerspiegelen hoe woorden in de omringende tekst worden gebruikt. Vervolgens leert een Kolmogorov–Arnold Network‑module subtiele, niet‑lineaire patronen — bijvoorbeeld hoe bepaalde materialen vaak samen voorkomen met specifieke technieken of regio’s. Een multi‑head attention‑laag onderzoekt daarna relaties door de hele zin vanuit meerdere invalshoeken, en tenslotte kiest een decoderlaag de meest waarschijnlijke reeks entiteitstags. Deze architectuur is ontworpen om lange, complexe zinnen met metaforen en gelaagde culturele referenties aan te kunnen.
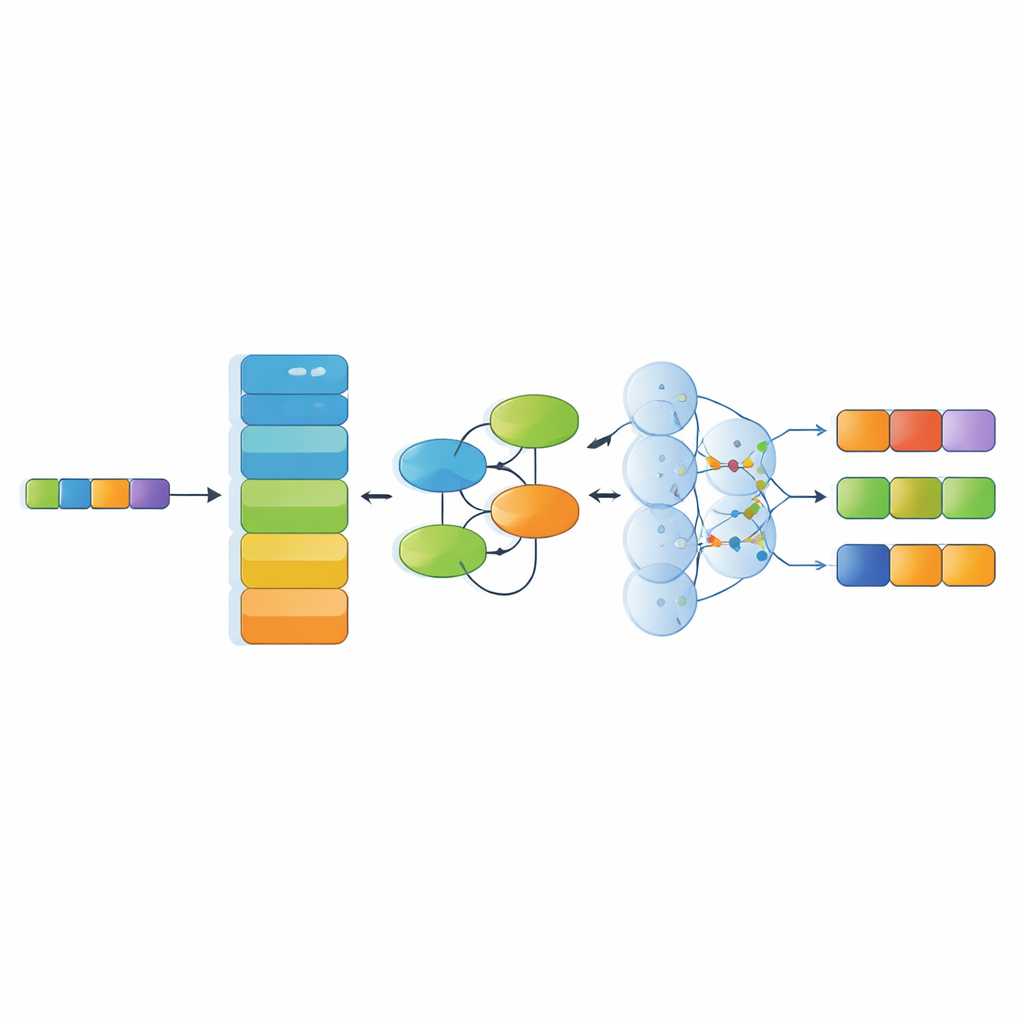
Hoe goed het systeem erfegdtekst begrijpt
De auteurs vergeleken hun model met verschillende sterke basismodellen die vaak in taalonderzoek worden gebruikt, waaronder systemen gebaseerd op recurrente netwerken, roosterstructuren voor Chinese tekst en een recente methode die entiteiten als segmenten behandelt die stap voor stap worden verfijnd. Op de ICH‑NER‑dataset presteerden methoden die moderne pretrained taalmodellen gebruiken duidelijk beter dan oudere benaderingen. Hun gecombineerde RoBERTa–KAN–attention–decoder‑systeem behaalde de beste algehele balans tussen precisie en recall, vooral voor uitdagende categorieën zoals materialen, organisaties en ambachtstechnieken, waar de data relatief schaars zijn en beschrijvingen vaak ingewikkeld of dubbelzinnig zijn.
Wat dit betekent voor levende cultuur in het digitale tijdperk
In praktische termen maken de nieuwe dataset en het model het eenvoudiger voor computers om wie, wat, waar en wanneer te extraheren uit rijke beschrijvingen van traditionele ambachten. Deze gestructureerde informatie kan worden ingezet in kennengraphs, interactieve kaarten of zoekhulpmiddelen die onderzoekers, conservatoren en het brede publiek helpen te onderzoeken hoe technieken zich verspreiden, hoe bepaalde families of regio’s een ambacht vormgeven en hoe praktijken zich in de loop van de tijd ontwikkelen. Hoewel het werk technisch van aard is, is de impact menselijk: het biedt een manier om verspreide, tekstgebonden beschrijvingen van levende tradities om te zetten in georganiseerde kennis die beter kan bijdragen aan het behoud en begrip van immaterieel cultureel erfgoed.
Bronvermelding: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Trefwoorden: immaterieel cultureel erfgoed, named entity recognition, Chinese taalverwerking, culturele datasets, digitale conservering