Clear Sky Science · nl
Globale emissiefactorendataset voor Scope‑3‑toepassingen met machine learning
Waarom het volgen van verborgen koolstof ertoe doet
Het grootste deel van de klimaatimpact van moderne bedrijven komt niet van hun eigen schoorstenen, maar van lange, ingewikkelde toeleveringsketens—alles wat ze kopen, verkopen, verschepen en uitbesteden. Deze zogeheten “Scope 3”‑emissies zijn berucht moeilijk te volgen. De paper introduceert ExioML, een open mondiale dataset en toolkit die decennia aan complexe economische en milieugegevens omzet in data die klaar zijn voor machine learning. Dat maakt het veel eenvoudiger voor onderzoekers, beleidsmakers en bedrijven om in te schatten waar emissies werkelijk vandaan komen, methoden eerlijk te vergelijken en slimmere klimaatactie te ontwerpen.
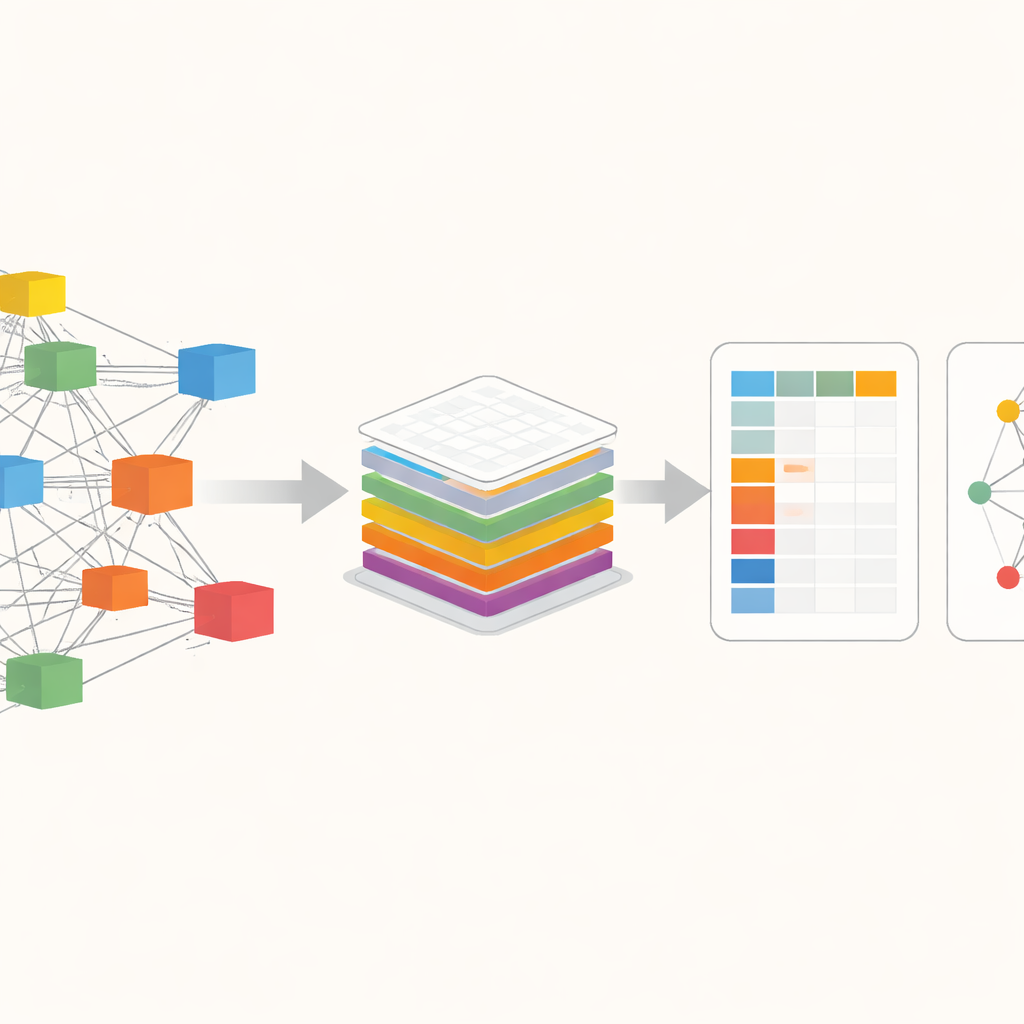
De wereldeconomie zien als een web
Centraal in ExioML staat een manier om de wereldeconomie te bekijken als een gigantisch web van industrieën die onderling over grenzen heen handelen. In plaats van alleen te tellen hoeveel CO2 binnen een land vrijkomt, volgt deze benadering de route van emissies langs toeleveringsketens: van grondstoffen, naar fabrieken, naar winkels en tenslotte naar consumenten. Bestaande databases die dit doen zijn krachtig maar vaak achter betaalmuren, lastig in gebruik of verouderd. De auteurs bouwen voort op een van de meest gedetailleerde open bronnen, EXIOBASE, en reorganiseren die zodat iedereen eenvoudig vragen kan stellen zoals: hoeveel broeikasgas is gekoppeld aan staalproductie in een bepaald land en jaar, of hoe emissies in één regio vervat zitten in producten die elders worden geconsumeerd.
Ruwe cijfers omzetten in gebruiksklare data
De ruwe EXIOBASE‑bestanden zijn enorm—meer dan 40 gigabyte aan tabellen die transacties tussen honderden sectoren in tientallen regio’s beschrijven, plus parallelle registers van emissies, hulpbronnen en energiegebruik. De auteurs ontwerpen ExioML om deze complexiteit te destilleren tot twee hoofdcomponenten. De eerste is een “factor accounting”‑tabel: een keurig gestructureerd spreadsheet waarin elke rij een specifieke sector in een specifieke regio en jaar is, met kolommen voor toegevoegde waarde, banen, energiegebruik en broeikasgasuitstoot. De tweede is een “footprint‑netwerk”: een gestroomlijnde kaart van de sterkste handelsverbindingen tussen sectoren, die laat zien hoe geld, energie en emissies door de wereldeconomie stromen. Voor de productie hiervan vertrouwen ze op krachtige graphics‑processing units (GPU’s) om de veeleisende matrixberekeningen uit te voeren die emissies langs toeleveringsketens traceren, en ze standaardiseren eenheden, sectorcodes en naamgeving zodat alle 49 regio’s en 28 jaren direct te vergelijken zijn.
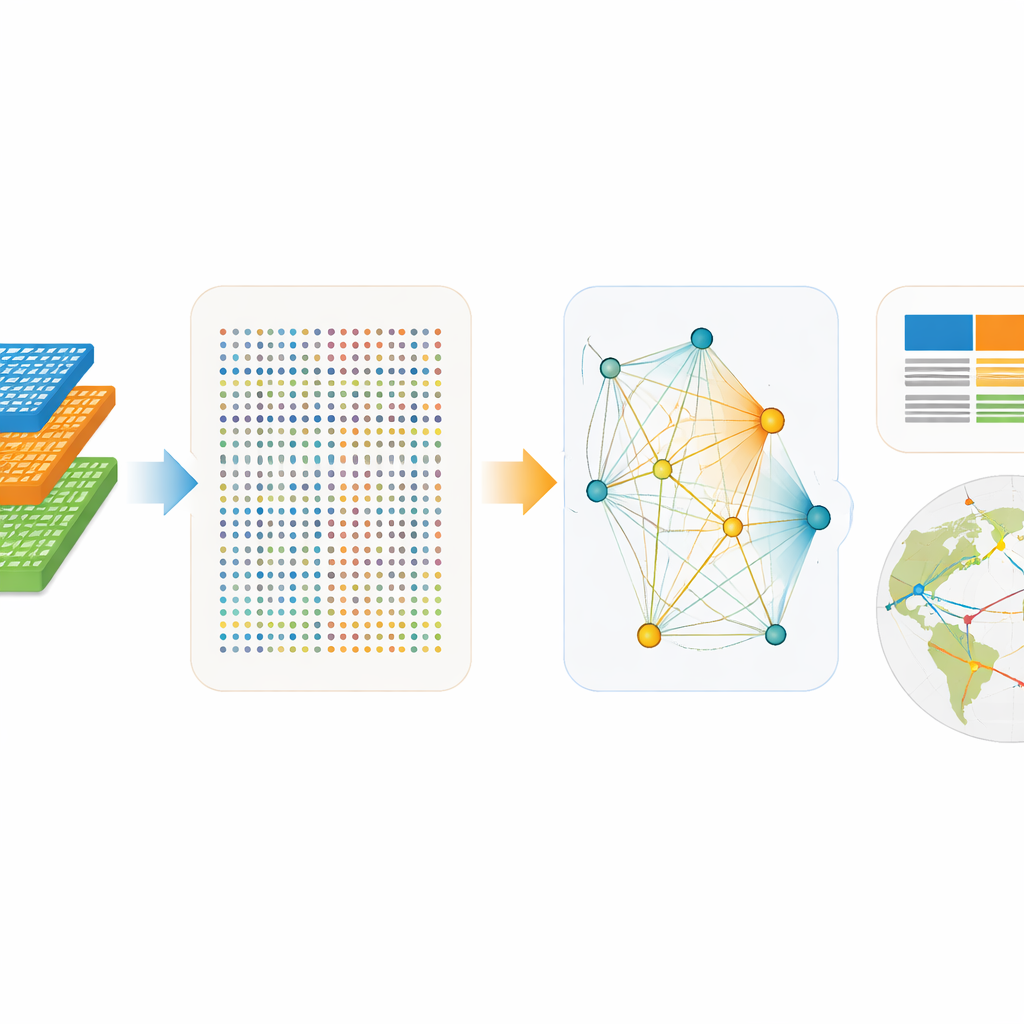
Ontworpen voor moderne machine learning
ExioML is vanaf de basis ontworpen met machine learning in gedachten. De dataset bestrijkt 49 regio’s van 1995 tot 2022 en biedt twee compatibele weergaven: één uitgesplitst in 200 producttypen en een andere in 163 industrieën. Deze structuur laat onderzoekers elk sector–regio–jaar als een datapunt behandelen, waarbij eenvoudige numerieke kenmerken—zoals bevolking, inkomen per persoon, energie per outputeenheid of emissies per eenheid energie—kunnen worden gecombineerd met categorische informatie over waar en wat de sector is. De auteurs publiceren ook een open‑source softwarepakket dat de data kan laden, netwerksamenvattingen kan genereren en zelfs kant‑en‑klare trainings-, validatie‑ en testverdelingen kan leveren. Dit verlaagt de drempel voor zowel klimaatexperts als dataspecialisten die modellen willen bouwen zonder eerst expert te worden in gespecialiseerde economische verantwoording.
Testen hoe goed modellen emissies kunnen voorspellen
Om te laten zien hoe ExioML gebruikt kan worden, stellen de auteurs een benchmarktaak op: het voorspellen van de broeikasgasuitstoot van een sector op basis van een kleine set economische en energie‑gerelateerde indicatoren. Ze vergelijken klassieke machine‑learningmodellen, zoals k‑nearest neighbors en boomgebaseerde ensembles, met moderne deep‑learningbenaderingen die automatisch kenmerkcombinaties kunnen leren. Na zorgvuldig opschonen, schalen en splitsen van de data concluderen ze dat eenvoudige lineaire modellen moeite hebben, wat bevestigt dat de relatie tussen productie, banen, energiegebruik en emissies sterk niet‑lineair is. Boomgebaseerde methoden en neurale netwerken presteren beide goed, waarbij een gated neurale model de beste nauwkeurigheid behaalt. De verbetering ten opzichte van goed-afgestelde gradient‑boosted trees is echter bescheiden, terwijl de deep‑modellen veel langer hoeven te trainen en lastiger zijn af te stemmen.
Wat dit betekent voor klimaat- en datawerk
Voor niet‑specialisten is de kernboodschap dat ExioML een ondoorzichtige kluwen van mondiale economische en milieugegevens transformeert tot een gedeelde, open basis waarop iedereen kan voortbouwen. Bedrijven die de klimaatimpact van hun aankopen willen begrijpen, onderzoekers die algoritmen ontwerpen om emissie‑hotspots te vinden, en analisten die onderzoeken hoe beleid of technologische veranderingen toekomstige emissies kunnen verschuiven, kunnen allemaal werken vanaf dezelfde transparante bron. De studie toont aan dat met de juiste structuur zelfs relatief eenvoudige machine‑learningtools veel van het verborgen patroon in emissies over sectoren en regio’s kunnen vangen. Door openheid, technische degelijkheid en praktische software te combineren, helpt ExioML koolstofboekhouding te verschuiven van een lappendeken van private schattingen naar een meer reproduceerbare, datagedreven wetenschap.
Bronvermelding: Guo, Y., Guan, C. & Ma, J. Global emission factor dataset for Scope 3 machine learning applications. Sci Data 13, 348 (2026). https://doi.org/10.1038/s41597-026-06699-1
Trefwoorden: Scope 3‑emissies, koolstofboekhouding, input–outputanalyse, machine learning, emissies in de toeleveringsketen