Clear Sky Science · nl
Op weg naar geautomatiseerde verslaglegging: een bronchoscopy-rapportdataset ter verbetering van multimodale grote taalmodellen
Slimmere ondersteuning voor longartsen
Wanneer artsen met een kleine camera in de luchtwegen kijken, leren ze veel over iemands longen — maar het omzetten van wat ze zien in heldere, gedetailleerde rapporten kost tijd en ervaring. Deze studie introduceert een nieuwe, zorgvuldig samengestelde collectie echte bronchoscopiebeelden en -rapporten die bedoeld is om geavanceerde AI-systemen te leren hoe ze kunnen helpen bij dat schrijven. Voor patiënten kan dit uiteindelijk betekenen: snellere, meer consistente rapporten en minder kans dat belangrijke details over het hoofd worden gezien.
Waarom in de longen kijken belangrijk is
Een bronchoscopie is een ingreep waarbij een dun buisje met een camera in de luchtwegen wordt geleid om de luchtpijp en de vertakkende buizen van de longen te inspecteren. Het helpt artsen problemen op te sporen, zoals ontsteking, infectie, tumoren of bloedingen, en kan ook behandelingen begeleiden, bijvoorbeeld het verwijderen van vreemde voorwerpen of het plaatsen van kleine steuntjes om de luchtwegen open te houden. Achteraf moet de arts beschrijven wat er gezien is in een formeel rapport, dat deel uitmaakt van het medisch dossier en de behandelbeslissingen stuurt. Het schrijven van deze rapporten is nauwkeurig, repetitief werk dat sterk afhangt van de opleiding en het geheugen van de arts.
Waarom bestaande data niet volstond
De afgelopen jaren hebben krachtige AI-modellen die zowel beelden als tekst kunnen verwerken vooruitgang geboekt in het lezen van medische scans en het opstellen van rapporten. Voor bronchoscopie waren de beschikbare trainingsgegevens echter smal en onvolledig. Eerdere datasets besloegen vaak slechts enkele taken — zoals het opsporen van een tumor of het markeren van de positie van de camera — terwijl veel alledaagse bevindingen zoals slijm, milde bloedingen of zwelling, die artsen routinematig beschrijven, werden genegeerd. Sommige verzamelingen waren bovendien privé, klein of gericht op eenvoudige ja/nee-beslissingen, wat ze ongeschikt maakte als leermateriaal voor een AI die rijke, mensachtige beschrijvingen van wat de camera ziet moet produceren.
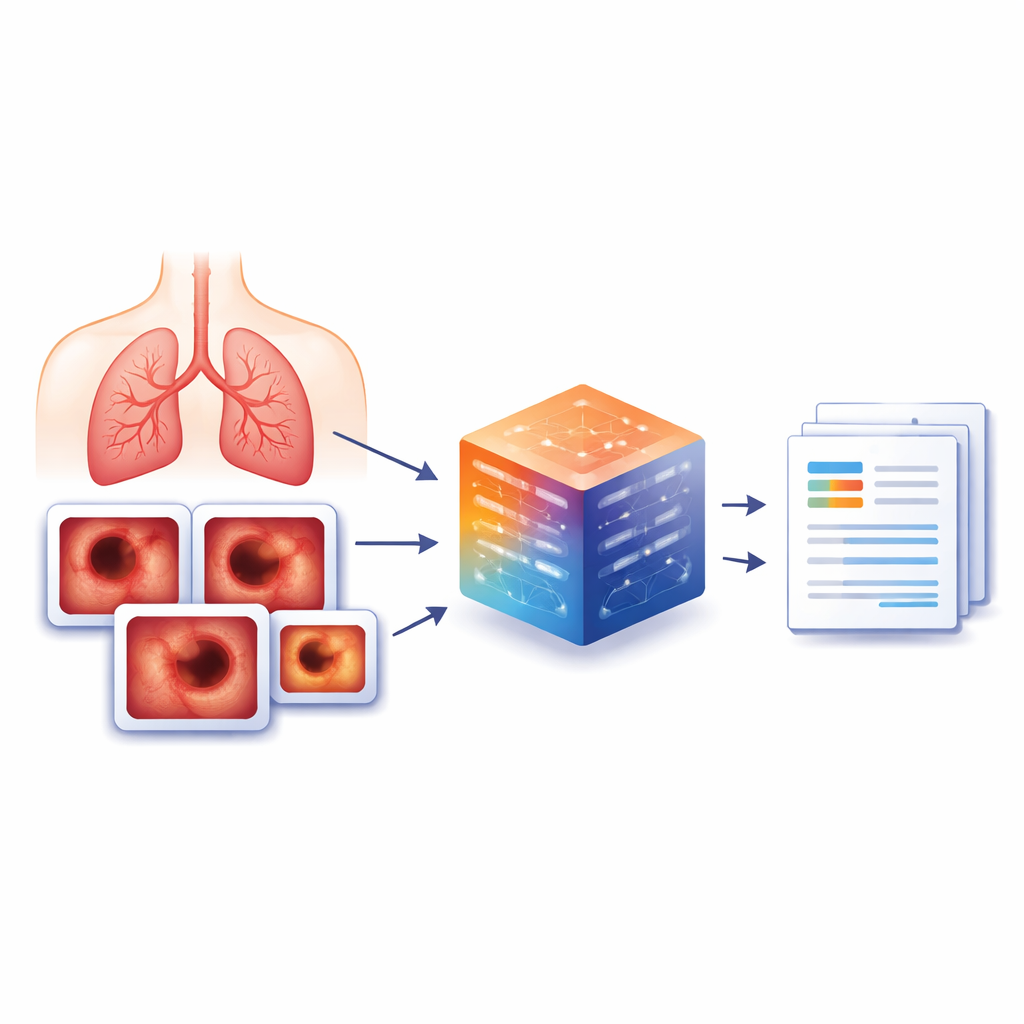
Een rijkere beeldbibliotheek opbouwen
Om deze kloof te dichten, maakten de auteurs BERD, een nieuwe bronchoscopie-onderzoeksrapportdataset opgebouwd uit echte procedures van een groot ziekenhuis in China. Van 8.477 bronchoscopieën uitgevoerd tussen 2022 en 2023 selecteerden zij 3.692 representatieve patiëntcases en 6.330 sleutelbeelden die artsen als bijzonder informatief hadden gemarkeerd. Voor elk beeld koppelden getrainde clinici een nauwkeurige schriftelijke beschrijving van wat zichtbaar was, zoals tumoren, zwelling, afzettingen of normaal weefsel. Wanneer een beeld geen probleem toonde, gebruikten zij een eenvoudige standaardzin zoals “Het is normaal” om de data consistent te houden. Persoonlijke gegevens werden verwijderd en de oorspronkelijke Chinese rapporten werden met een lokaal draaiend taalmodel naar het Engels vertaald om de privacy te beschermen.
Hoe experts en AI samenwerkten
Naast plain-tekstbeschrijvingen wilde het team dat elk beeld met een of meer medische categorieën werd getagd — bijvoorbeeld “tumor”, “congestie” of “oedeem” — zodat AI-modellen zowel kunnen leren labelen als beschrijven. Om dit efficiënt te doen, stelden ervaren bronchoscopie-specialisten eerst een gedetailleerde lijst met categorieën samen op basis van medische richtlijnen. Een lokaal ingezet taalmodel scande vervolgens de tekstbijschriften om suggesties te doen welke categorieën van toepassing waren op elk beeld. Menselijke experts controleerden en corrigeerden deze suggesties nauwgezet en behielden de uiteindelijke controle over de medische kwaliteit. Het resultaat is een fijngeannoteerde bron waarbij elk beeld gekoppeld is aan een duidelijke beschrijving, anatomische locatie en door experts bevestigde labels, allemaal georganiseerd in eenvoudige bestanden die onderzoekers direct kunnen gebruiken.
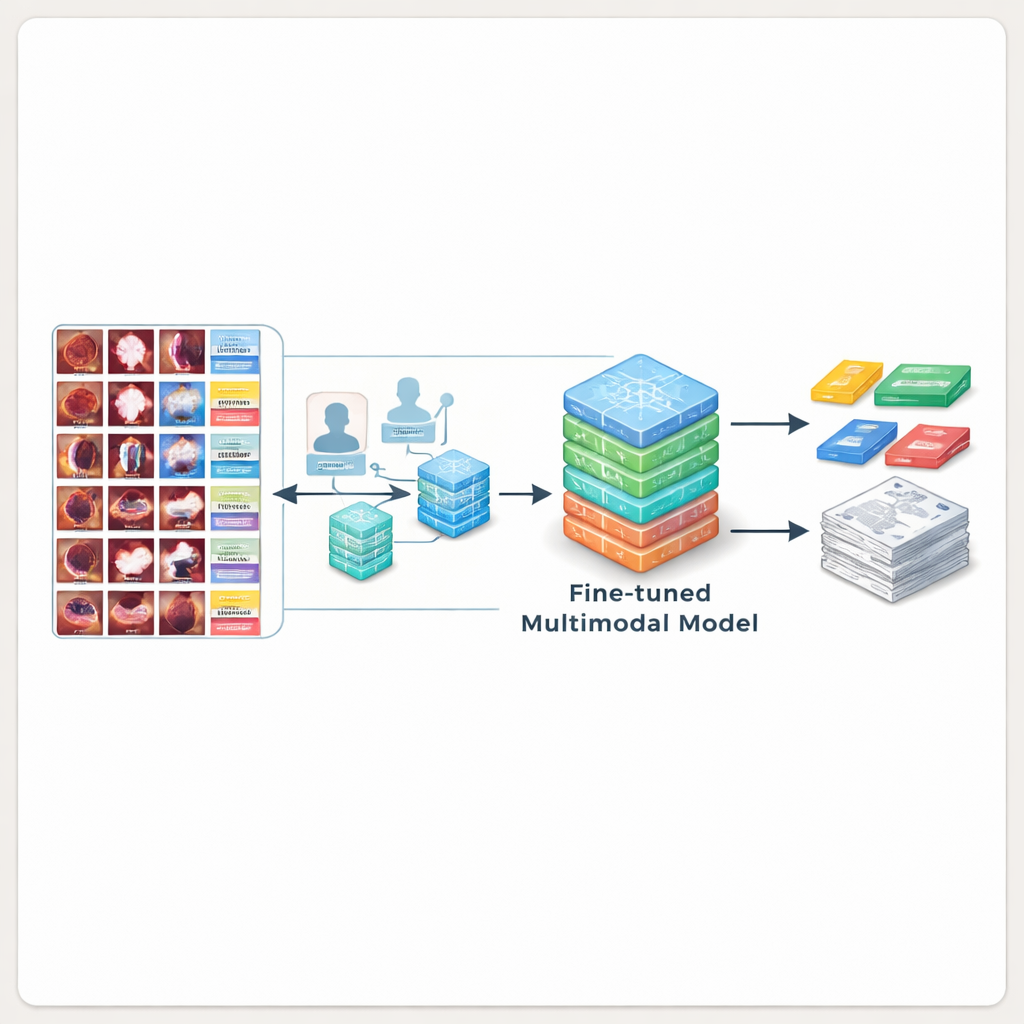
AI leren betere rapporten te schrijven
Om aan te tonen dat BERD echt nuttig is, gebruikten de onderzoekers de dataset om verschillende toonaangevende multimodale AI-modellen te trainen. Eerst testten ze algemene en medische AI-systemen die nog nooit bronchoscopiebeelden hadden gezien. Deze modellen begrepen vaak verkeerd wat ze zagen, misten tumoren of verzonnen details, en scoorden slecht vergeleken met door experts geschreven tekst. Het team fine-tunede vervolgens open-source modellen op de BERD-beelden en bijschriften. Na deze extra training produceerde het beste model beschrijvingen die veel beter overeenkwamen met de bewoording van experts en in meer dan 80% van de gevallen door clinici als acceptabel werden beoordeeld — wat betekent dat de door AI gegenereerde tekst vaak met minimale bewerking rechtstreeks in een echt rapport kon worden opgenomen.
Wat dit betekent voor toekomstige zorg
Kort gezegd levert dit werk de ontbrekende “trainingsbibliotheek” die AI-systemen nodig hebben om betrouwbare assistenten voor bronchoscopierapportage te worden. Hoewel de data uit één ziekenhuis komen en sommige numerieke details bewust zijn weggelaten om misleiding van de modellen te voorkomen, is de dataset openbaar, goed gedocumenteerd en groot genoeg om een nieuwe standaard voor dit vakgebied te zetten. Naarmate onderzoekers voortbouwen op BERD, kunnen patiënten uiteindelijk profiteren van snellere, meer uniforme bronchoscopierapporten, waardoor artsen meer tijd overhouden voor besluitvorming en behandeling in plaats van administratief werk.
Bronvermelding: Luo, X., Huang, X., Liang, X. et al. Towards Automated Reporting: A Bronchoscopy Report Dataset for Enhancing Multimodality Large Language Models. Sci Data 13, 339 (2026). https://doi.org/10.1038/s41597-026-06692-8
Trefwoorden: bronchoscopie, medische beeldvorming, klinische rapporten, multimodale AI, medische datasets