Clear Sky Science · nl
Een fijnmazige fundusbeeldendataset voor beoordeling en diagnose van cataracternst
Waarom scherpere oogonderzoeken ertoe doen
Cataract is de belangrijkste oorzaak van blindheid wereldwijd, vooral bij oudere volwassenen. Toch ontdekken veel mensen pas dat ze een ernstig probleem hebben wanneer hun gezichtsvermogen al zo ver achteruit is gegaan dat het hun dagelijks leven verstoort. Dit artikel presenteert een nieuwe, zorgvuldig gelabelde verzameling oogfoto’s en een kunstmatige-intelligentie (AI)-raamwerk dat is ontworpen om de ernst van een cataract te beoordelen en die beoordeling in gewone taal toe te lichten. Door één enkel oogbeeld om te zetten in een gedetailleerd ‘rapport’ over lensvertroebeling en visuele kwaliteit, wil dit werk vroegtijdige en nauwkeurige cataractbeoordeling beschikbaar maken buiten gespecialiseerde oogklinieken.
Een nadere blik op de achterkant van het oog
In plaats van de troebele lens direct te fotograferen, richten de onderzoekers zich op fundusbeelden—kleurfoto’s van het netvlies, de lichtgevoelige laag aan de achterkant van het oog. Wanneer de lens troebel wordt, worden deze foto’s doffer en vager, vervagen bloedvaten en worden belangrijke gebieden moeilijker zichtbaar. Artsen gebruiken deze aanwijzingen al informeel, maar tot nu toe bestond er geen openbare dataset die subtiele veranderingen in deze beelden koppelt aan fijnmazige cataracternstscores en door experts geschreven verklaringen. De nieuwe Cataract Severity and Diagnostic Image dataset (CSDI) vult dit gat en geeft AI-modellen de rijke begeleiding die nodig is om het oordeel van experts na te bootsen.
Het opbouwen van een rijk geannoteerde verzameling oogbeelden
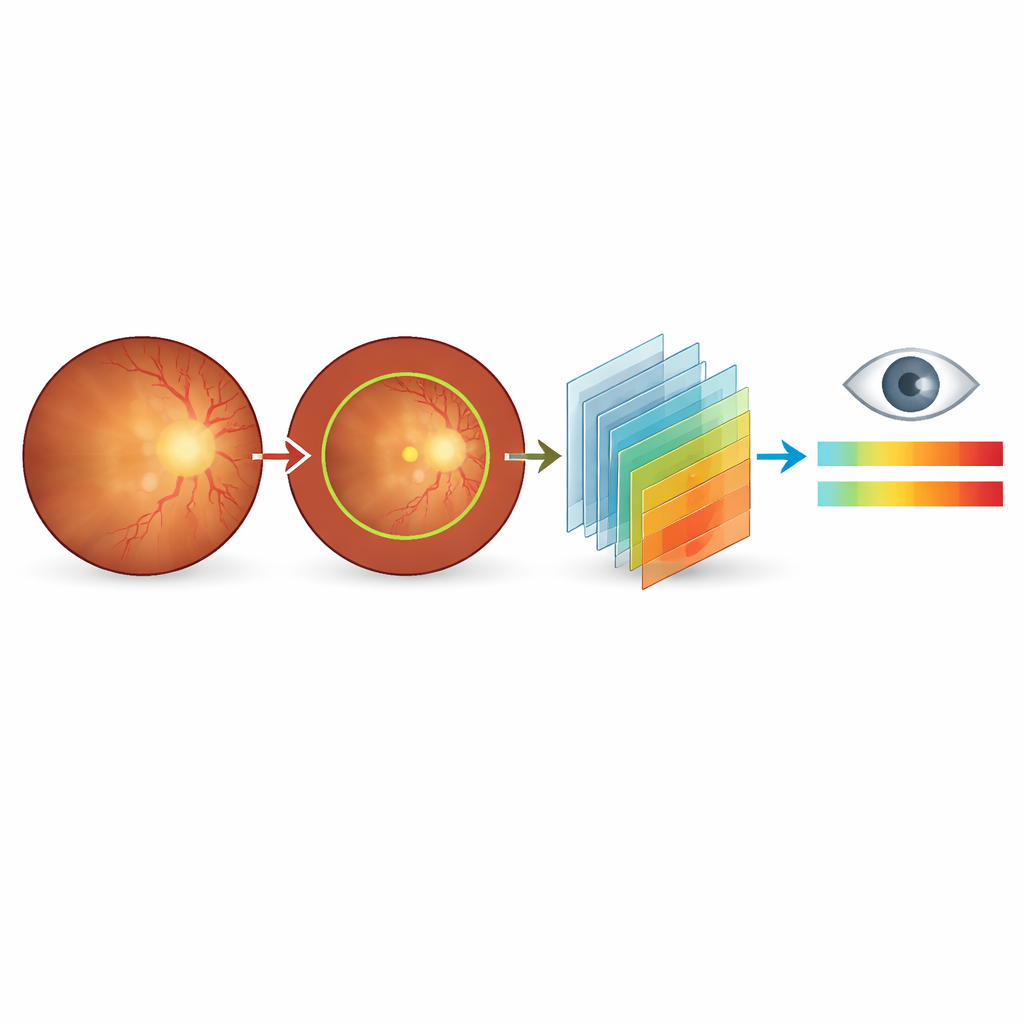
CSDI is gebaseerd op 187 fundusbeelden van patiënten die tussen 2023 en 2024 zijn gezien in een groot oogziekenhuis in Beijing. Alle beelden zijn gemaakt met dezelfde camera en instellingen om technische verschillen te minimaliseren. Twee ervaren oogartsen hebben de beelden eerst gescreend en afbeeldingen verwijderd die slecht belicht, deels geblokkeerd of aangetast waren door andere oogaandoeningen. Voor elk overgebleven beeld beoordeelden zij de algehele kleur en helderheid, hoe scherp de papil (optische schijf) en zijn oppervlakkige vaten verschenen, hoe makkelijk het was om de centrale macularegion te lokaliseren en hoeveel vertakkingen van de retinale bloedvaten nog zichtbaar waren. Deze observaties werden vervolgens gedistilleerd in zowel een numerieke score als een gestructureerde geschreven diagnose.
Van eenvoudige labels naar een gedetailleerd cataract ‘scorebord’
In plaats van te stoppen bij een ja-of-nee-antwoord over cataract, ontwikkelde het team een ernstschaal van 0–10 met één decimaal. Scores dicht bij nul duiden op geen cataracteffect op het fundusbeeld; scores in het middensegment komen overeen met lichte tot matige vervaging die nader onderzoek kan vereisen; en hoge scores wijzen op ernstige beeldachteruitgang die consistent is met significante visusproblemen en waarschijnlijk chirurgie vereist. Om consistente AI-training te ondersteunen, leverden de onderzoekers ook automatische omtrekken van het hoofd-fundusgebied en handmatige omtrekken en zichtbaarheidsvlaggen voor de papil. Elk beeld gaat vergezeld van bijpassende Engelse en Chinese diagnostische zinnen die kleurverschuivingen, vervaging en verloren details in een vaste volgorde beschrijven, zodat modellen een sjabloon krijgen voor hoe experts redeneren over wat ze zien.
Een visie-en-taal-AI leren handelen als een oogarts
Bovenop deze dataset testten de auteurs een nieuw diagnostisch raamwerk gebaseerd op multimodale grote taalmodellen—systemen die zowel naar beelden als tekst kijken. Deze modellen ontvangen een fundusfoto en een korte instructie om “op te treden als een oogarts” en reageren vervolgens met een ernstbeoordeling en een verhalende uitleg. Het team evalueerde zowel commerciële als open-source modellen op twee taken: het indelen van elk geval in één van vijf ernstgroepen (van normaal tot ernstig) en het genereren van een diagnostische beschrijving die overeenkomt met de woordkeuze van experts. Daarna finetuneden zij meerdere open-source modellen met efficiënte technieken zodat ze binnen ziekenhuissystemen konden draaien, waarbij patiëntgegevens ter plaatse bleven terwijl ze toch de prestaties van grotere commerciële systemen bereikten of zelfs overtroffen.
Wat dit betekent voor patiënten en artsen
De kernboodschap voor gewone lezers is dat één enkele oogfoto nu kan worden omgezet in een genuanceerd beeld van de impact van een cataract, en niet alleen in een grove ‘je hebt het wel of niet’. De CSDI-dataset, vrij beschikbaar samen met code, maakt het mogelijk voor onderzoekers en clinici wereldwijd om AI-systemen te bouwen en te vergelijken die dezelfde taal spreken als oogspecialisten. Op de lange termijn kunnen dergelijke hulpmiddelen ondersteuning bieden bij screening op afstand in gemeenschappen met weinig oogartsen, meningsverschillen tussen clinici verminderen en patiënten helpen begrijpen waarom wel of geen operatie wordt aanbevolen—en zo helderder inzicht bieden in een aandoening waarvan het kenmerk ironisch genoeg het verlies van helderheid is.
Bronvermelding: Xie, Z., Ao, M., Tang, H. et al. A fine-grained fundus image dataset for cataract severity assessment and diagnosis. Sci Data 13, 418 (2026). https://doi.org/10.1038/s41597-026-06684-8
Trefwoorden: cataract, fundusbeeldvorming, medische AI, visie-taalmodellen, oogheelkundig dataset