Clear Sky Science · nl
Biomedical Data Manifest: Een lichtgewicht documentatiemap voor gegevens om de transparantie van AI/ML te vergroten
Waarom slimere gegevensnotities ertoe doen voor uw gezondheid
Naarmate ziekenhuizen en onderzoekers zich haasten om kunstmatige intelligentie te gebruiken voor het voorspellen van ziekte en het sturen van behandeling, bepaalt de kwaliteit van de gegevens die deze hulpmiddelen voeden stilletjes wie profiteert — en wie mogelijk buiten de boot valt. Dit artikel introduceert een praktische manier om een soort “etiket op de doos” te plaatsen voor biomedische datasets, zodat iedereen die AI-systemen bouwt snel kan zien waar de gegevens vandaan komen, wie ze vertegenwoordigen en hoe ze wel — en niet — gebruikt mogen worden. Door dit soort documentatie te stroomlijnen, streven de auteurs ernaar medische AI eerlijker, veiliger en betrouwbaarder te maken.
De verborgen verhalen in medische gegevens
De meeste grote biomedische datasets — verzamelingen van labuitslagen, scans of behandeluitkomsten — zijn nooit met AI in gedachten gemaakt. Ze missen vaak duidelijke vermeldingen van hoe de gegevens zijn verzameld, welke patiënten zijn opgenomen of wat er in de loop van de tijd veranderd is. Deze ontbrekende details kunnen vooringenomenheden verbergen, zoals het ondervertegenwoordigd zijn van bepaalde groepen of het inconsistent registreren van belangrijke informatie. Wanneer dergelijke gegevens worden gebruikt om machine learning-systemen te trainen, kunnen de resulterende hulpmiddelen voor sommige patiënten goed werken maar voor anderen slecht, waardoor bestaande ongelijkheden in de zorg worden versterkt. De auteurs betogen dat betere, gestandaardiseerde documentatie essentieel is om deze risico's te ontdekken en te beheersen voordat algoritmen in gebruik worden genomen.
De beste ideeën combineren in één eenvoudige gids
Er bestaan al verschillende data-"fact sheet"-benaderingen in de AI-gemeenschap, zoals Datasheets for Datasets, Data Cards en HealthSheets. Elk biedt gestructureerde vragen over het doel van een dataset, de inhoud, de verzamelmethoden en de beperkingen. Ze zijn echter meestal ontworpen door computerwetenschappers voor AI-specifieke datasets en kunnen lang en lastig zijn voor drukbezette biomedische onderzoekers om in te vullen. Om het wiel niet opnieuw uit te vinden, bracht het team eerst velden uit vier veel geciteerde sjablonen in kaart en harmoniseerde deze, en bouwde zo een geconsolideerde lijst van 136 vragen die de belangrijkste concepten vastlegde terwijl overlap werd verwijderd. Vervolgens verfijnden ze deze lijst tot 100 velden, gegroepeerd in zeven intuïtieve categorieën, variërend van basisinformatie en hoe de gegevens worden gebruikt tot kwesties als ethiek, juridische beperkingen en hoe labels zijn gemaakt.
Luisteren naar de mensen die de gegevens gebruiken en creëren
Vervolgens vroegen de onderzoekers echte biomedische belanghebbenden — waaronder clinici, laboratoriumwetenschappers, gegevensbeheerders en computationele experts — om aan te geven hoe essentieel elk documentatieveld voor hun werk was. Drieëntwintig deelnemers uit een multicenter kankeronderzoeksnetwerk voltooiden de enquête. Het team groepeerde de respondenten in twee brede "persona's": degenen die dichter bij het verzamelen van gegevens aan de bench of bed stonden, en degenen die voornamelijk gegevens beheren, cureren of analyseren. Dit liet duidelijke verschillen in prioriteiten zien. Beide groepen hechtten bijvoorbeeld veel waarde aan het weten wanneer een dataset voor het laatst was bijgewerkt en wanneer deze mogelijk weer verandert. Maar alleen de gegevensbeheerders en computationele experts gaven sterk de voorkeur aan details over hoe labels waren toegewezen of hoe toekomstige updates eruit zouden zien, terwijl clinici en benchwetenschappers meer nadruk legden op de beoogde en ongeschikte gebruiksmogelijkheden van de gegevens.
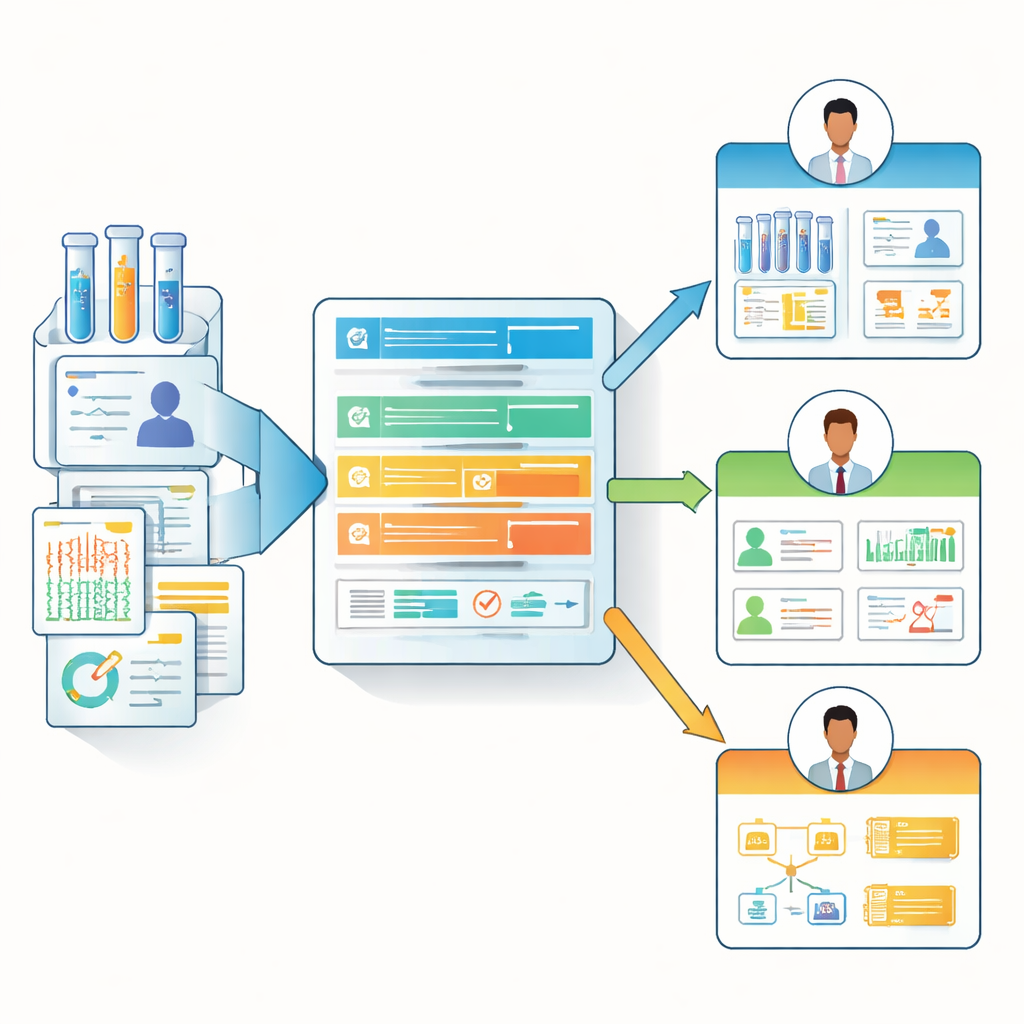
Van one-size-fits-all naar rolbewuste gegevensnotities
Op basis van deze enquête-inzichten ontwierpen de auteurs het "Biomedical Data Manifest", een lichtgewicht, webgebaseerde documentatiesjabloon die zich aanpast aan verschillende rollen. In plaats van elke bijdrager te dwingen een enorme checklist in te vullen, gebruikt het manifest een hiërarchie van kernvragen en optionele, meer gedetailleerde vragen. Het kan de meest relevante velden voor elke persona benadrukken — bijvoorbeeld het naar voren halen van gegevensherkomst en update-details voor analisten, terwijl het klinische context en beperkingen benadrukt voor onderzoekers en clinici aan de frontlinie. Het team biedt een kant-en-klaar formulier (bijvoorbeeld in Microsoft Forms), een HTML-weergavesjabloon en een open-source R-pakket genaamd BioDataManifest. Deze software kan enquête-antwoorden automatisch omzetten in duidelijke manifestpagina's en zelfs informatie ophalen uit grote openbare repositories zoals de Genomic Data Commons en dbGaP om gedeeltelijke manifests voor bestaande datasets te maken.
Wat dit betekent voor de toekomstige medische AI
Uiteindelijk is het Biomedical Data Manifest een praktisch hulpmiddel om de "kleine lettertjes" van biomedische datasets gemakkelijker te maken om te creëren, delen en begrijpen. Door documentatie over gegevens te scheiden van documentatie over specifieke AI-modellen, en door te bepalen wat aan verschillende gebruikersrollen wordt getoond, verlaagt het raamwerk de last voor onderzoekers terwijl het afnemende gebruikers de context geeft die ze nodig hebben om te beoordelen of een dataset geschikt is voor een bepaald doel. In dagelijkse bewoordingen verandert het ondoorzichtige medische datasets in duidelijk gelabelde pakketten, waardoor AI-ontwikkelaars beperkingen en potentiële vooroordelen kunnen herkennen voordat ze patiënten beïnvloeden. Als dit breed wordt aangenomen, kan dit soort rolbewuste, herbruikbare documentatie biomedische AI transparanter, reproduceerbaarder en rechtvaardiger maken.
Bronvermelding: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Trefwoorden: biomedische gegevensdocumentatie, verantwoorde AI in de geneeskunde, dataset-transparantie, vooringenomenheid in machine learning, gegevensbeheer