Clear Sky Science · nl
Schattingsmethode voor onderwijspercentiel op buurtniveau in China met multisource big data en machine learning
Waarom het onderwijsniveau in uw buurt ertoe doet
Waar we wonen bepaalt welke scholen onze kinderen volgen, hoe veilig onze straten zijn en zelfs de waarde van onze huizen. In China was basisinformatie over hoe geschoold verschillende buurten zijn echter lange tijd moeilijk te verkrijgen. Deze studie verandert dat door gebruik te maken van satellietbeelden, straatfoto’s en geavanceerde computeralgoritmen om het relatieve opleidingsniveau van meer dan 120.000 gemeenschappen in het hele land te schatten, en biedt daarmee een nieuw perspectief op sociale ongelijkheid en het stedelijk leven.
Voorbij het tellen van schooljaren
De meeste statistieken vergelijken onderwijs door te kijken naar het aantal jaren dat mensen op school hebben doorgebracht. Dat kan misleidend zijn over generaties heen. Een middelbare schooldiploma placht iemand hoog in zijn of haar leeftijdsgroep te plaatsen; tegenwoordig hebben veel van hun kinderen een universitaire graad. De auteurs gebruiken in plaats daarvan een “education percentile rank”, die aangeeft waar iemand staat binnen zijn of haar eigen geboortecohort, van 0 (minst geschoold) tot 100 (meest geschoold). Op die manier kan een oudere persoon met alleen middelbare school en een jongere met een bachelordiploma als vergelijkbaar in sociale positie worden herkend als ze bijvoorbeeld allebei rond het 70e percentiel van hun generatie zitten.
De stedelijke omgeving lezen als sociale aanwijzing
Om onderwijspercentielrangen op buurtniveau in kaart te brengen, putte het team uit zes golven van een grote nationale enquête plus een breed scala aan “big data” die de gebouwde omgeving beschrijven. Ze keken naar welke soorten voorzieningen elke buurt omringen—winkels, scholen, ziekenhuizen, parken en kantoren—hoe dicht gebouwen en wegen liggen, hoe helder het gebied ’s nachts vanaf satellieten lijkt, en hoeveel mensen er doorgaans aanwezig zijn. Uit miljoenen streetview-foto’s gebruikten ze computervisie om groenvoorzieningen, trottoirs, verkeer, tekenen van verloedering zoals zwerfvuil of graffiti, en zelfs hoe welvarend of veilig een straat voor menselijke waarnemers lijkt, te meten. Ze hielden ook rekening met terrein, zoals hoogte en helling, omdat steile of afgelegen gebieden vaak achterblijven in ontwikkeling. 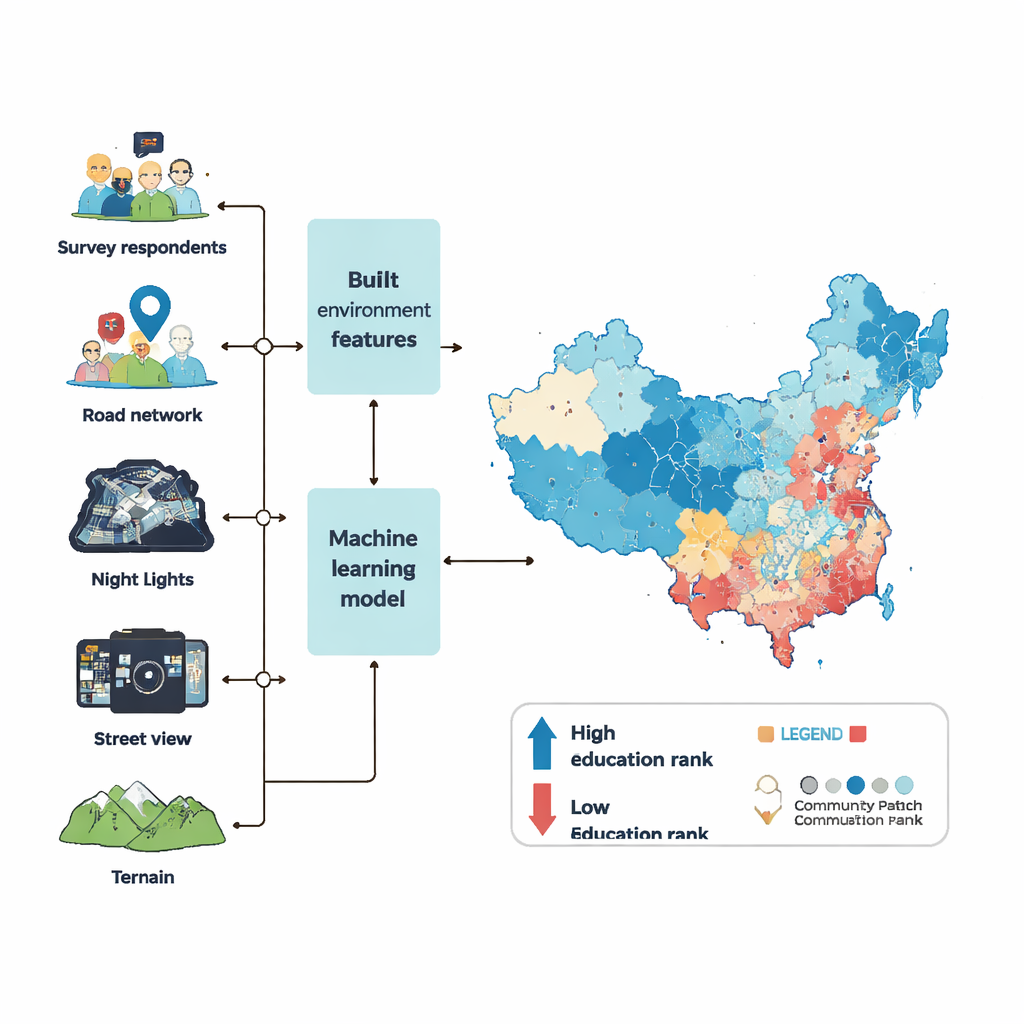
Machines leren de stad te lezen
Met deze ingrediënten trainden de onderzoekers een krachtig machine-learningmodel (XGBoost genoemd) om de relatie te leren tussen de fysieke kenmerken van een gemeenschap en de gemiddelde education percentile rank van haar bewoners. Ze vulden eerst hiaten in de omgevingsgegevens in met een zorgvuldige statistische imputeringsprocedure, zodat ontbrekende waarden de resultaten niet zouden vertekenen. Vervolgens stelden ze de interne instellingen van het model af via honderden optimalisatieruns en beoordeelden de prestaties op basis van hoe goed het model educatierangen kon voorspellen voor enquêtegemeenschappen die het nog niet had gezien. Het uiteindelijke model kon meer dan 90 procent van de verschillen tussen gemeenschappen in de testgegevens verklaren, met slechts kleine fouten—sterkere prestaties dan vergelijkbare pogingen in andere landen.
Wat de nieuwe nationale kaart onthult
Met het getrainde model voorspelden de auteurs gemiddelde education percentile ranks voor 122.126 gemeenschappen in het Chinese vasteland in 2020, wat het grootste deel van het stedelijke gebied en ongeveer 85 procent van de bevolking beslaat. Stadscentra blijken over het algemeen het meest geschoold, gevolgd door secundaire knooppunten en vervolgens afgelegen buitenwijken, hoewel elke metropool zijn eigen patroon heeft. Het historische kerngebied van Peking herbergt bijvoorbeeld niet de allerhoogste rangen, terwijl de hoogopgeleide zones van Shenzhen verspreid liggen over meerdere centra. Om de betrouwbaarheid te controleren vergeleek het team hun schattingen met officiële censusgegevens en waar beschikbaar met propriëtaire locatiegebaseerde serviceregistraties. Op prefectuur- en districtsniveau laten gebieden met hogere voorspelde percentielrangen ook meer schooljaren zien in de census. Op buurtniveau in Peking en Guangzhou komt hun kaart goed overeen met zowel bedrijfs- als censusreferenties. 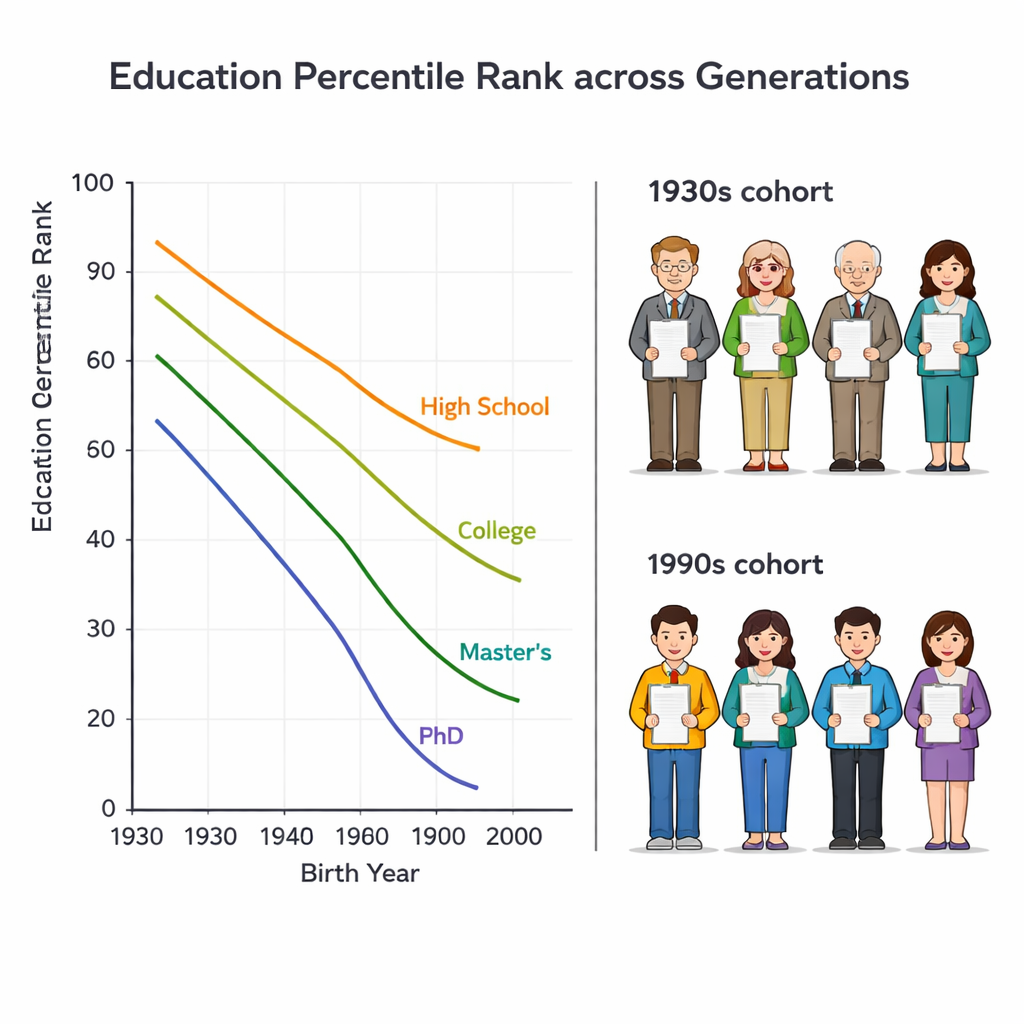
Waarom dit van belang is voor het dagelijks leven
Voor beleidsmakers, planners en onderzoekers biedt deze nieuwe open dataset een gedetailleerd, actueel beeld van onderwijsvoordeel en -achterstand in Chinese steden. Het kan worden gebruikt om te bestuderen waar middenklasse-enclaves ontstaan, hoe ver gentrificatie is gevorderd, of welke districten betere scholen, sociale diensten of openbaar vervoer nodig hebben. Voor leken is de kernboodschap eenvoudig: door de straten, verlichting en gebouwen van een buurt te “lezen”, kunnen moderne datatools de sociale positie van haar bewoners met verrassende nauwkeurigheid benaderen. Dit werk vervangt traditionele volkstellingen niet, maar het levert een snelle, goedkope manier om de gaten tussen die volkstellingen op te vullen en beter te begrijpen hoe de plaatsen die we bouwen onze sociale verschillen weerspiegelen en bestendigen.
Bronvermelding: Zhang, Y., Pan, Z., You, Y. et al. Community-level education percentile rank estimation in China using multi-source big data and machine learning. Sci Data 13, 304 (2026). https://doi.org/10.1038/s41597-026-06664-y
Trefwoorden: ongelijkheid in onderwijs, stedelijk China, big data, machine learning, wijken