Clear Sky Science · nl
Een geannoteerde dataset van Gram-kleuringen uit positieve bloedkweken
Waarom snelle infectie-antwoorden belangrijk zijn
Wanneer bacteriën of schimmels in de bloedbaan terechtkomen, kan elk uur zonder de juiste behandeling het verschil tussen leven en dood betekenen. Artsen vertrouwen op een snelle laboratoriumtest, de Gram-kleuring, om te zien welk type micro-organisme aanwezig is en welke vroege antibiotica geschikt zijn. Het lezen van deze gekleurde microscoopglaasjes is echter een vakmanschap, handmatig werk dat tijd kost en kan variëren tussen technici. Deze studie beschrijft een nieuwe, zorgvuldig geannoteerde beeldverzameling van echte ziekenhuisbloedkweekglaasjes, bedoeld om computers te helpen Gram-kleuringen automatisch te lezen en zo snellere, betrouwbaardere zorg te ondersteunen.
Van echte ziekenhuisglaasjes naar data
De onderzoekers verzamelden 57 verschillende soorten bacteriën en schimmels die waren gekweekt uit positieve bloedkweekflessen van patiënten als onderdeel van het dagelijkse ziekenhuiswerk. Van januari tot mei 2024, zodra een bloedkweek positief aangaf, bereidde het personeel Gram-gekleurde uitstrijken op objectglaasjes en bevestigde de exacte soort met een zeer nauwkeurige identificatiemethode, MALDI-TOF massaspectrometrie. Zonder de normale routines te veranderen of extra monsters te verzamelen, maakte het team vervolgens hoge-resolutie digitale beelden van typische velden onder een 100× olie-immersie-objectief, resulterend in 505 grote kleurenafbeeldingen die nabootsen wat technici in de praktijk zien.
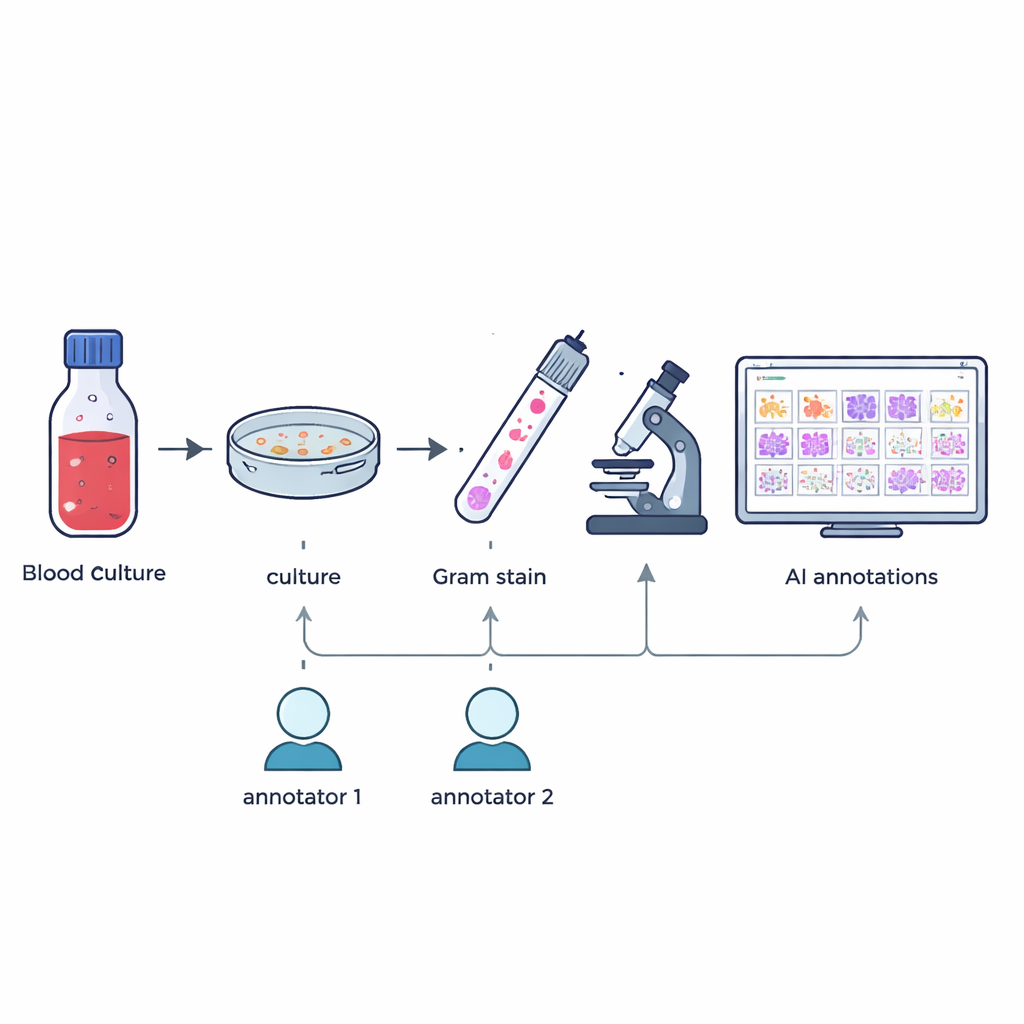
Zorgvuldige labeling van piepkleine vormen
Het bouwen van een bruikbare trainingsset voor kunstmatige intelligentie vereist precies weten waar elk micro-organisme in elke afbeelding staat. Twee ervaren microbiologie-technici tekenden onafhankelijk vakjes rond individuele microben of clusters in elke afbeelding, uitsluitend geleid door wat zij onder de microscoop zagen. Een maatwerksoftware vergeleek de twee sets markeringen: vakjes die voldoende overlapten werden samengevoegd en eventuele mismatches of onenigheden werden gemarkeerd. Een senior expert met meer dan 20 jaar ervaring beoordeelde deze gevallen vervolgens handmatig. Dit stappenplan leverde 7.528 gecontroleerde annotaties op die kokken (ronde cellen), bacillen (staafvormige cellen) en schimmels markeren, terwijl gedeeltelijke of twijfelachtige objecten werden weggelaten.
Wat de dataset bevat
De voltooide bron combineert meerdere informatielagen. Alle 505 afbeeldingen worden geleverd als hoogwaardige JPEG-bestanden en de definitieve, expert-gecontroleerde vakjes zijn opgeslagen in het gangbare COCO JSON-formaat dat veel wordt gebruikt in computer vision-onderzoek. Extra bestanden koppelen elke afbeelding aan de microbe-soort, of deze Gram-positief of Gram-negatief is, de brede vormcategorie, het type bloedkweekfles waaruit het afkomstig is en hoe lang de kweek nodig had om positief te worden. Omdat elke afbeelding slechts één soort bevat, delen alle vakjes binnen een gegeven afbeelding dezelfde biologische kenmerken. Gebruikers kunnen kiezen tussen één groot annotatiebestand of afzonderlijke bestanden per afbeelding, en er is een eenvoudig Python-script bijgevoegd om elke afbeelding te visualiseren met de vakjes eroverheen.
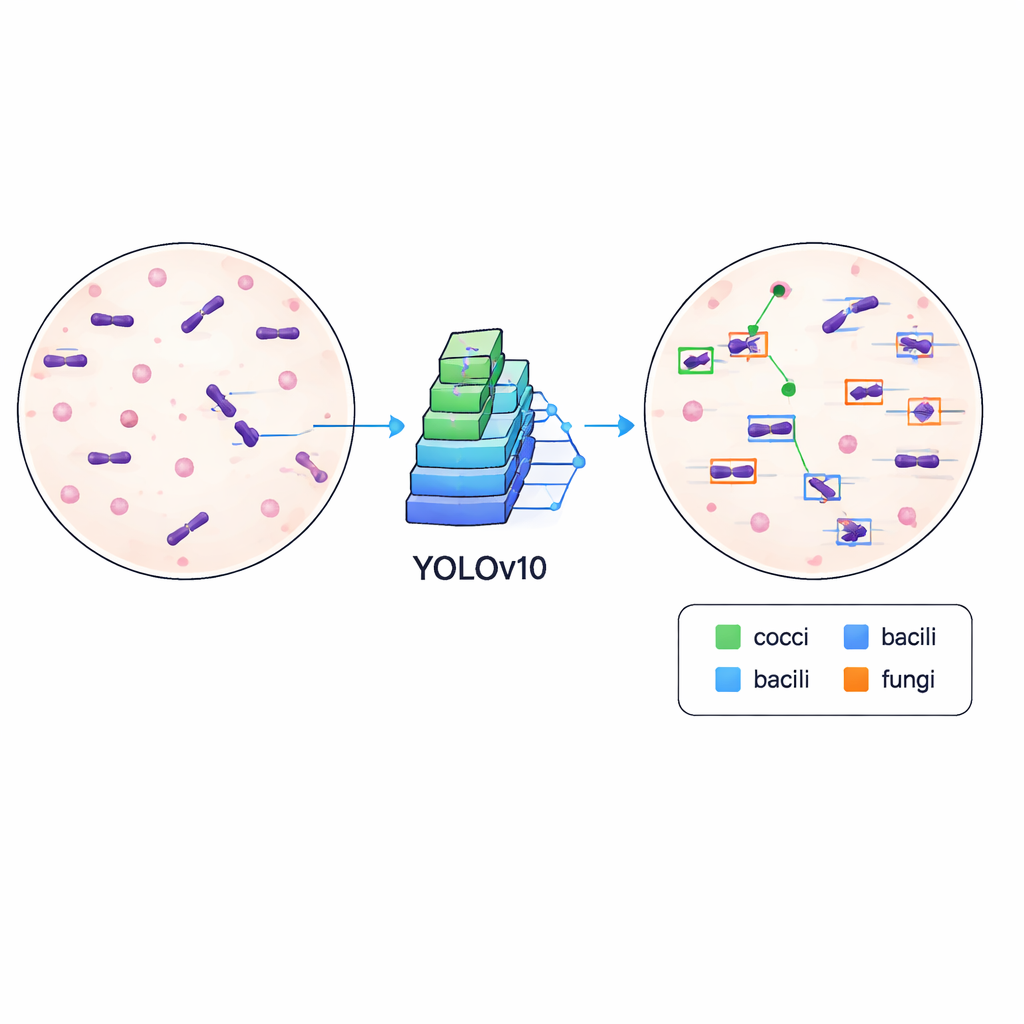
Computers trainen om microben te zien
Om te laten zien dat de dataset niet alleen netjes maar ook praktisch is, trainden de auteurs een moderne objectdetectie-algoritme, bekend als YOLOv10, om microben in de afbeeldingen te vinden en te classificeren. Ze splitsten de data in trainings- en validatiesets en lieten het model 500 trainingsronden draaien op een hoogwaardige grafische kaart, waarbij ze bijhielden hoe goed het leerde nauwkeurige vakjes te tekenen en verschillende celtypen te onderscheiden. Het getrainde systeem behaalde een mean average precision van ongeveer 84,6% bij een standaard matching-drempel, wat aangeeft dat het betrouwbaar microben kan lokaliseren en labelen over gevarieerde uitstrijkverschijningsvormen, inclusief verschillen in kleurintensiteit, achtergronddeeltjes en scherpstelling.
Hoe deze bron gebruikt kan worden
Aangezien de data gangbare formaten volgen, kunnen ze worden aangesloten op veel bestaande computer vision-pijplijnen. Onderzoekers kunnen eerst een systeem trainen om echte microben van vuil en resten te onderscheiden, waarmee laboratoria kunnen helpen valse-positieve kweeksignalen te filteren. Ze kunnen ook microben groeperen in brede vormcategorieën, passend bij wat clinici nodig hebben voor een vroege, zogenoemde "Tier 1"-rapportage die de eerste antibioticakeuze stuurt. Een ambitieuzer doel is het onderscheiden van individuele soorten aan de hand van subtiele visuele signalen. De auteurs wijzen op beperkingen: sommige cellen zijn gegroepeerd, sommige glazjes stammen van slechts één bron per soort en de scherpte kan variëren—net als in het echte leven. Toch is elk opgenomen vakje zorgvuldig gecontroleerd, waardoor de dataset een betrouwbare startpunt is.
Wat dit betekent voor patiënten
Eenvoudig gezegd verandert dit werk routinematige bloedkweekglaasjes in een gedeeld oefenterrein voor slimme software. Door zowel de afbeeldingen als de deskundige markeringen openbaar beschikbaar te maken, verlaagt de studie de drempel voor teams wereldwijd om AI-tools te bouwen en te testen die Gram-kleuringen snel en consistent kunnen lezen. Hoewel zulke systemen menselijke microbiologen niet zullen vervangen, kunnen ze helpen gevaarlijke infecties sneller te signaleren, interpretatiefouten te verminderen en een beter gebruik van antibiotica te ondersteunen. Voor patiënten kan dat betekenen dat ze sneller en preciezer worden behandeld wanneer het het meest nodig is.
Bronvermelding: Yi, Q., Gou, X., Zhu, R. et al. An annotated dataset of Gram stains from positive blood cultures. Sci Data 13, 294 (2026). https://doi.org/10.1038/s41597-026-06651-3
Trefwoorden: bloedbaaninfecties, Gram-kleuring, medisch afbeeldingsdataset, kunstmatige intelligentie, microbiologische diagnostiek