Clear Sky Science · nl
Een Chinese dataset voor natuurkunde/vakonderwijs in het basisonderwijs voor het genereren van probleemoplossingsprocessen
Kinderen helpen wetenschap te leren met slimmer AI
Ouders en leerkrachten zien kunstmatige intelligentie steeds meer als een potentiële studiepartner, maar huidige chatbots geven vaak uitleg die ofwel te oppervlakkig is of veel te ingewikkeld voor kinderen. Dit artikel introduceert een nieuwe Chinese Elementary Science Question (CSQ) dataset die grote taalmodellen moet leren wetenschap uit te leggen zoals een goede basisschoolleraar dat zou doen: stap voor stap, op het juiste niveau en nauw aansluitend bij wat kinderen daadwerkelijk in de klas leren.
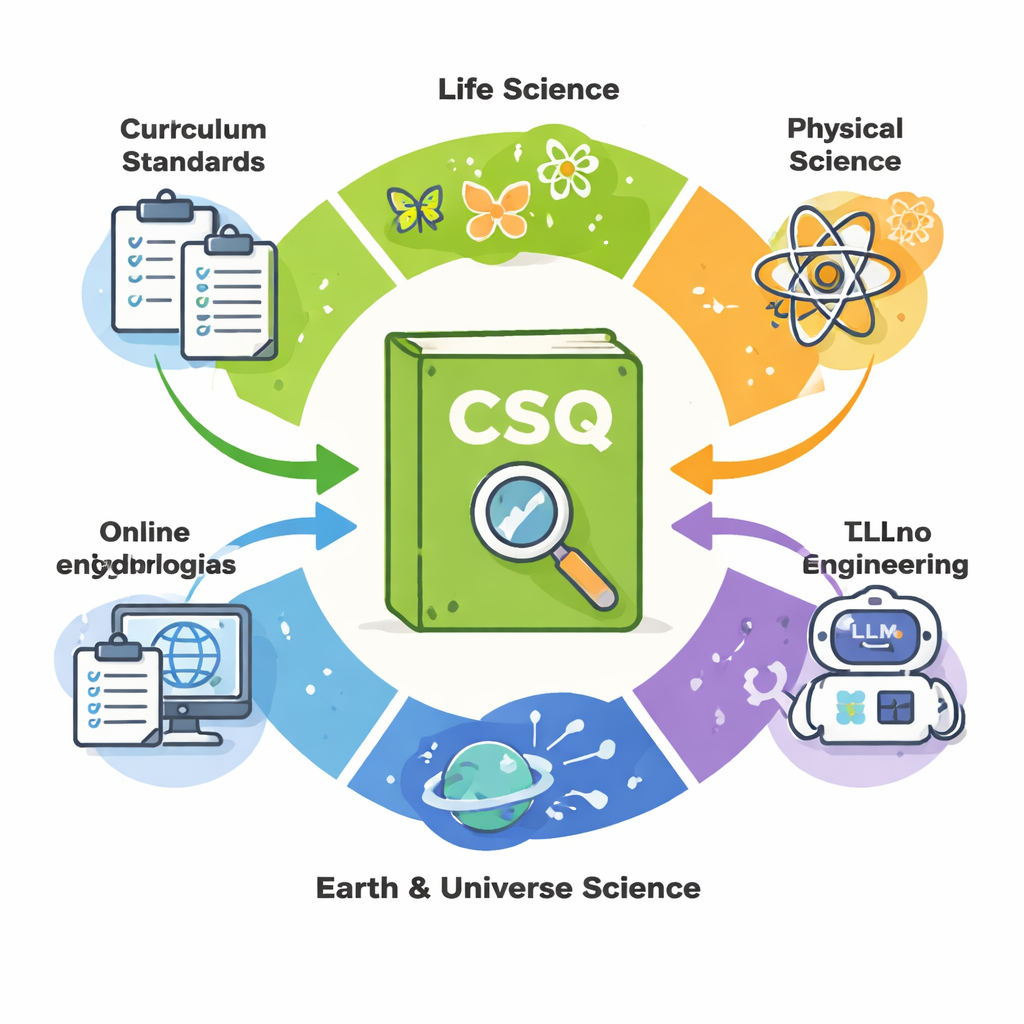
Een nieuwe vraagbank voor jonge wetenschapsleerlingen
De CSQ-dataset is een verzameling van 12.000 zorgvuldig samengestelde wetenschapsvragen, afkomstig uit het Chinese basiscurriculum, schoolexamens en betrouwbare onlinebronnen. De vragen bestrijken vier brede gebieden—biologie, natuurkunde, aarde en ruimte, en technologie en techniek—voor de groepen 1 tot en met 6. In tegenstelling tot veel bestaande vraagbanken die alleen een vraag en het correcte antwoord geven, bevat elk CSQ-item ook informatie over het schoolniveau, het onderwerp en welke wetenschappelijke vaardigheden worden getest, plus een volledige, leeftijdsadequate verklaring van de oplossing.
Vastleggen hoe kinderen daadwerkelijk denken
Een belangrijke vernieuwing van CSQ is de focus op het ‘probleemoplossende denkproces’ achter elk antwoord. Voor elke vraag leggen experts het redeneerverloop uit in taal en detail die passen bij het beoogde leerjaar. Voor jongere kinderen blijven de uitleg concreet en observerend—for example door te beschrijven wat gezien of gevoeld kan worden. Voor oudere leerlingen worden geleidelijk meer abstracte ideeën geïntroduceerd, zoals systemen, oorzaak en gevolg of eenvoudige modellen. Elk item tagt ook de kernvaardigheden die aan bod komen, zoals het waarnemen van een verschijnsel, het vergelijken van twee objecten of het identificeren van de functie van een hulpmiddel. Deze structuur stelt AI-modellen in staat niet alleen het juiste antwoord te geven, maar ook te oefenen met het soort denken dat leerlingen geacht worden te leren.
De dataset bouwen met klaslokaalrealiteit in gedachten
Het creëren van CSQ vereiste een gestructureerd, mensgericht proces. Een team van 19 onderzoekers met ervaring in natuurwetenschappelijk onderwijs en AI verdeelde het werk in fasen. Senioren in het team verzamelden vragen uit officiële curriculumstandaarden, examenvragen en encyclopedieën, waarbij ze controleerden dat deze juridisch herbruikbaar waren. Promovendi pasten daarna de vragen aan en annoteerden ze zodat ze in meerkeuze- of waar/niet-waar-formaten pasten en overeenkwamen met de officiële Science Curriculum Standards for Compulsory Education (2022). Hun training benadrukte het hanteren van woordenschat en cognitieve diepgang die bij het leerjaar past. Elk data-item—vraag, vakkeneigenschappen en oplossing—werd door een andere annotator gecontroleerd, en meningsverschillen over de juiste vaardigheden of uitlegdiepte werden opgelost met behulp van de nationale standaarden als richtlijn.
AI leren zijn werk te laten zien
Om de waarde van CSQ te testen, finetuneden de onderzoekers verschillende open-source taalmodellen en evalueerden zij ook een vooraanstaand commercieel model op deze dataset. Ze maten niet alleen of modellen het juiste meerkeuzeantwoord kozen. Ze beoordeelden ook de kwaliteit van het gegenereerde redeneren met zowel automatische tekstanalysemethoden als deskundige menselijke beoordelingen. Na training op CSQ toonden open-source modellen duidelijke verbeteringen in nauwkeurigheid en in de helderheid en volledigheid van hun verklaringen. Bijvoorbeeld, een model dat eerder een basisschoolvraag over geluid beantwoordde met geavanceerde golfentheorie schakelde na finetuning over naar een eenvoudigere, meer leeftijdsadequate beschrijving. Menselijke beoordelaars vonden dat de gefinetunede modellen veel beter binnen het schoolniveau van het kind bleven en ‘kennisoverschrijding’ vermeden waarbij te technische ideeën verwarring zaaien in plaats van helpen.
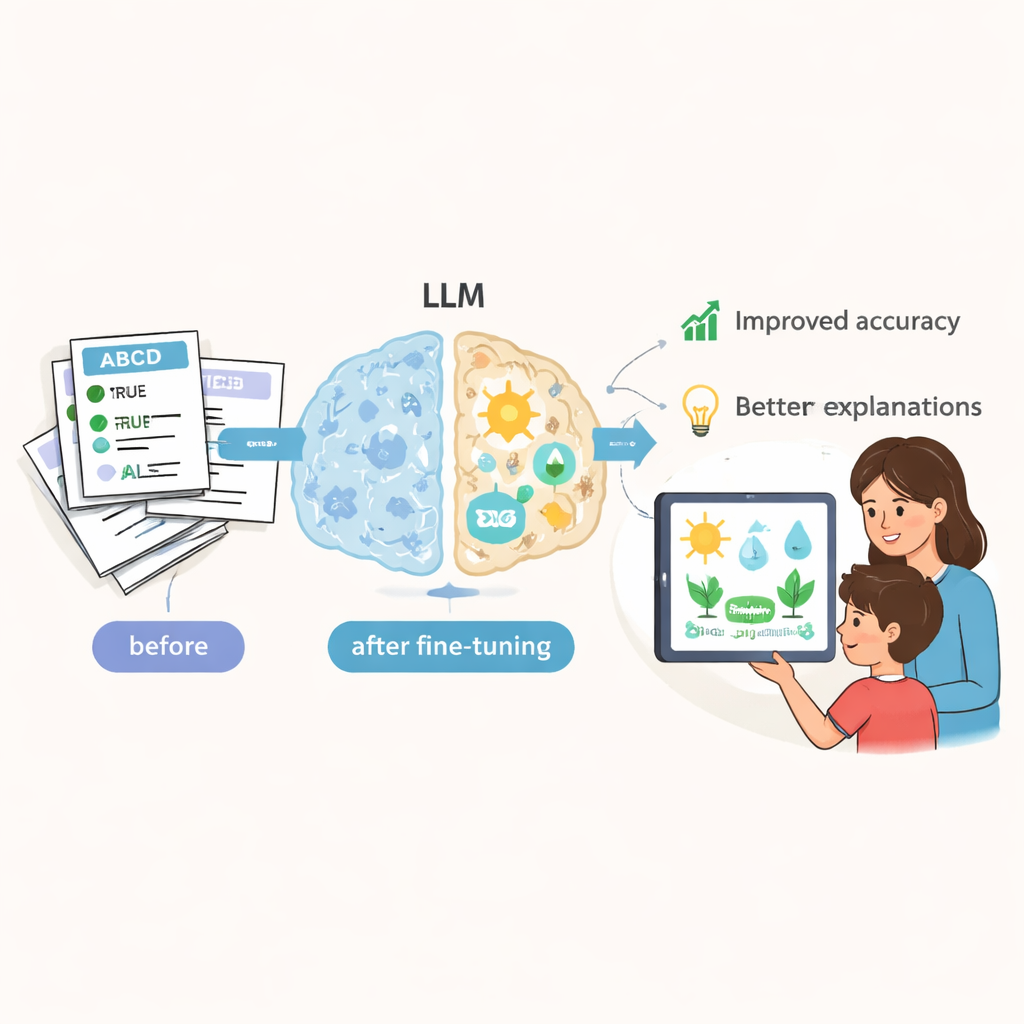
Beperkingen vandaag, een sjabloon voor morgen
De auteurs geven toe dat CSQ de structuur van het Chinese natuurkundecurriculum weerspiegelt en zich alleen richt op vraagformaten zoals meerkeuze en waar/niet-waar, niet op praktische experimenten of open opdrachten. De verklaringen zijn geschreven door getrainde promovendi, niet door klasleraren of de kinderen zelf, dus er is nog werk te doen om volledig aan te sluiten bij de taal van echte klaslokalen. Desondanks is het raamwerk achter CSQ—het koppelen van elke vraag aan vak, onderwerp, leerjaar, specifieke vaardigheden en stapsgewijze redenering—algemeen genoeg om soortgelijke bronnen voor andere talen en schoolsystemen te inspireren. In eenvoudige bewoordingen laat dit werk zien hoe zorgvuldig ontworpen vraagsets AI kunnen helpen een betrouwbaardere, leeftijdsgevoelige wetenschapstutor voor jonge leerlingen te worden.
Bronvermelding: Li, D., Liu, Z., Wen, C. et al. A Chinese Elementary Science Question Dataset in Problem-Solving Process Generation. Sci Data 13, 291 (2026). https://doi.org/10.1038/s41597-026-06618-4
Trefwoorden: natuurkundig basisonderwijs, grote taalmodellen, dataset voor vraagbeantwoording, gepersonaliseerde bijles, Chinees curriculum