Clear Sky Science · nl
Relatie-extractie en conceptnormalisatie op basis van transformers met een geannoteerd corpus van klinische proeven
Artsen sneller helpen de juiste patiënten te vinden
Elke klinische proef is afhankelijk van het vinden van patiënten die voldoen aan een lange lijst van medische voorwaarden, behandelingen en tijdsvensters. Tegenwoordig moeten artsen vaak elektronische patiëntendossiers en proefbeschrijvingen handmatig doorlezen, wat traag en foutgevoelig is. Dit artikel presenteert een grote, zorgvuldig gecontroleerde verzameling Spaanse teksten van klinische proeven en laat zien hoe moderne kunstmatige intelligentie die ongestructureerde taal kan omzetten in georganiseerde data, waarmee de weg wordt vrijgemaakt voor snellere, eerlijkere en preciezere medisch onderzoek.
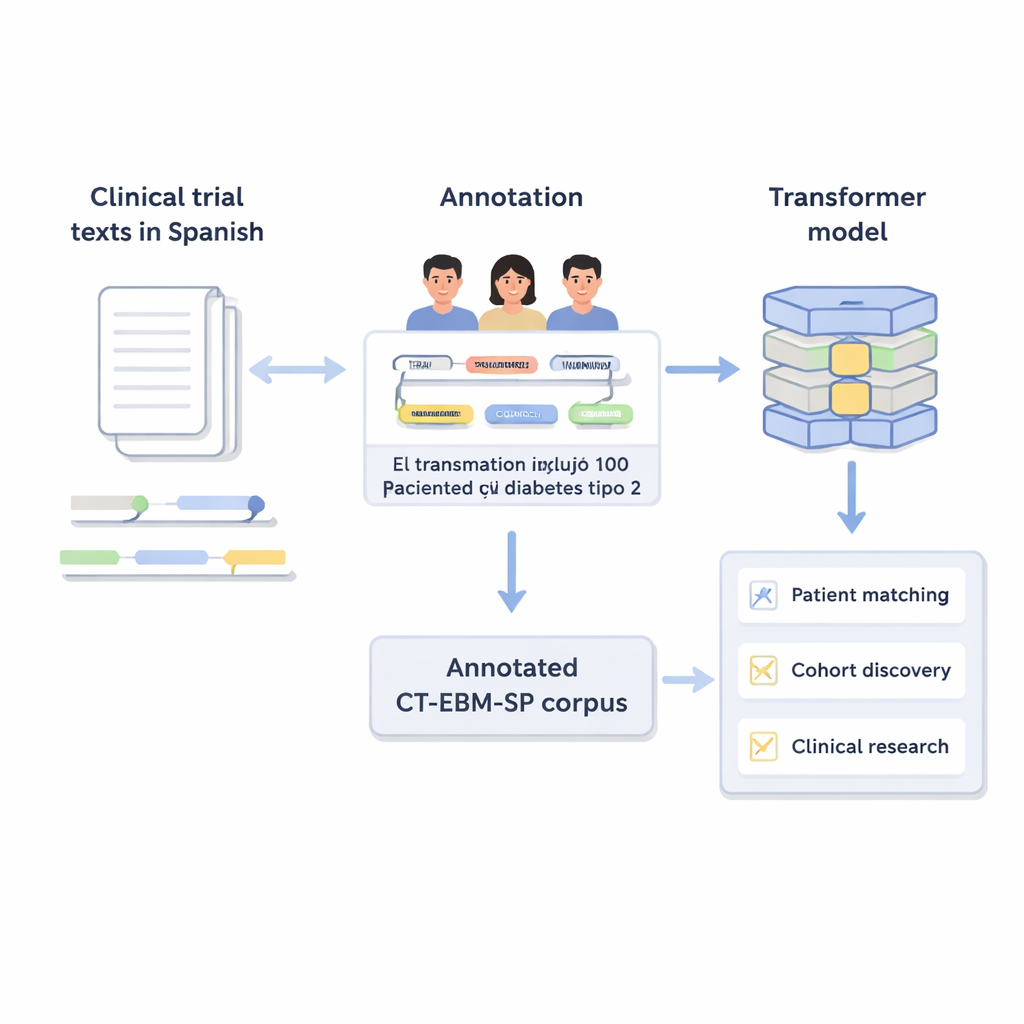
Vrije tekst omzetten in gestructureerde informatie
Klinische proeven beschrijven wie wel en niet kan deelnemen in alledaagse medische taal: leeftijdsgrenzen, eerder doorgemaakte ziekten, labuitslagen en eerder gebruikte behandelingen. Computers hebben moeite met dit soort vrije tekst. De auteurs creëerden versie 3 van het CT-EBM-SP-corpus, een dataset van 1.200 Spaanse teksten van klinische proeven met bijna 300.000 woorden. Menselijke experts doorliepen deze teksten en markeerden 23 typen medische entiteiten, zoals ziekten, geneesmiddelen, testresultaten en tijdsuitdrukkingen, evenals aanwijzingen voor ontkenning (bijvoorbeeld „geen voorgeschiedenis van”) en onzekerheid. Ze labelden ook 11 attributen die details vastleggen, zoals of een gebeurtenis zich in het verleden of de toekomst afspeelt en of het de patiënt zelf of een familielid betreft.
Medische termen op één lijn brengen
Een grote uitdaging in de geneeskunde is dat hetzelfde concept op veel verschillende manieren kan worden geschreven. Om dit op te lossen koppelde het team de meeste gemarkeerde entiteiten aan gestandaardiseerde codes uit het Unified Medical Language System (UMLS), een omvangrijk meertalig medisch woordenboek. Deze stap, conceptnormalisatie genoemd, zorgt ervoor dat verschillende spellingsvarianten of uitdrukkingen naar dezelfde unieke identifier verwijzen. Bijvoorbeeld: meerdere varianten van „25-hydroxyvitamine D” worden allemaal aan één UMLS-concept gekoppeld. In totaal bevat het corpus meer dan 87.000 entiteiten en meer dan 68.000 relaties, en ongeveer 82% van de entiteiten werd succesvol genormaliseerd. Twee experts controleerden deze koppelingen onafhankelijk van elkaar en bereikten een zeer hoge overeenstemming, wat aangeeft dat de annotaties betrouwbaar zijn.
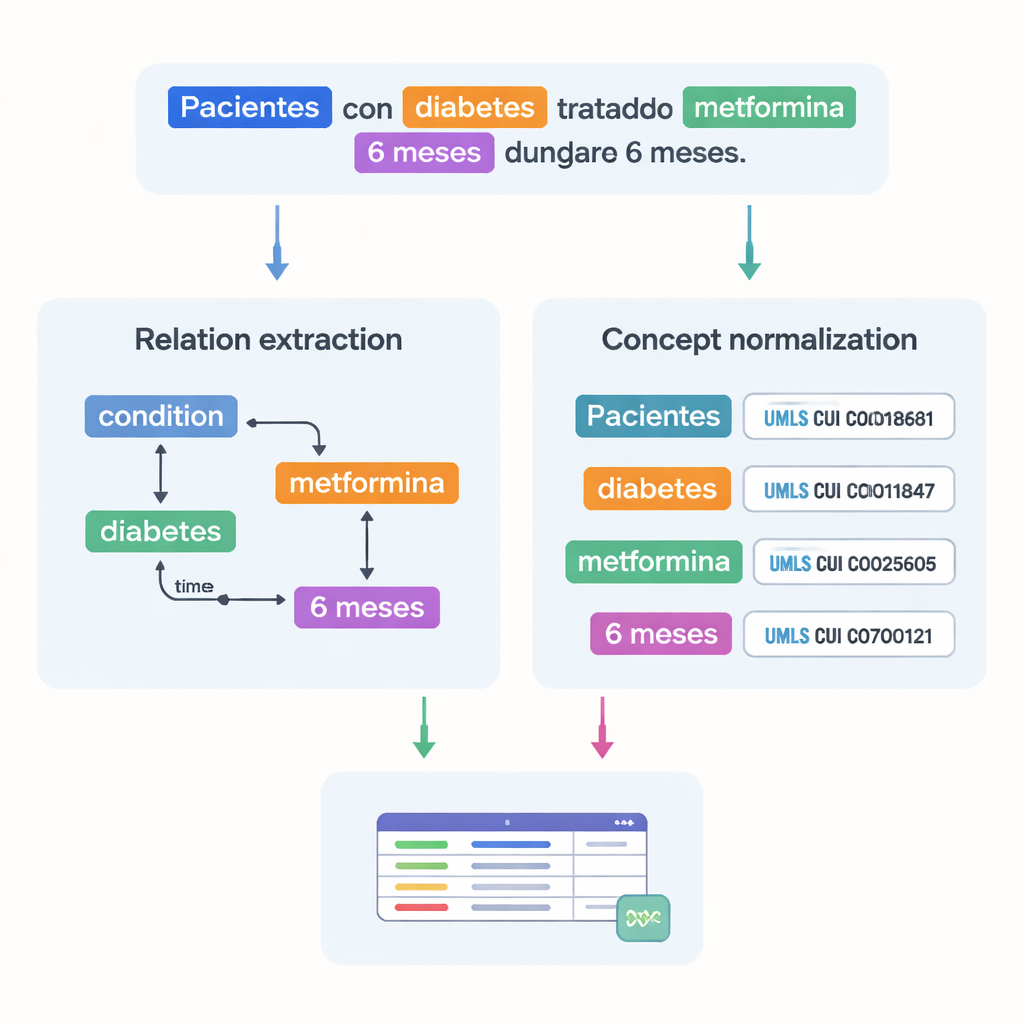
Hoe medische feiten zich tot elkaar verhouden vastleggen
Buiten het opsommen van medische termen registreert de dataset ook hoe ze met elkaar verbonden zijn. De auteurs ontwierpen 18 typen relaties om patronen vast te leggen die belangrijk zijn in proeven, zoals welke dosis bij welk middel hoort, hoe lang een behandeling duurt, of welke aandoening een patiënt ervaart. Temporale relaties tonen of de ene gebeurtenis vóór of ná een andere plaatsvindt, en andere koppelingen geven aan waar een ziekte zich in het lichaam voordoet of of een zin ontkenning of speculatie uitdrukt. Gezamenlijk maken deze relaties het mogelijk voor computers om grafen van de situatie van een patiënt te bouwen — wie de patiënt is, welke aandoening hij of zij heeft, welke behandeling wordt gegeven en met welke timing — in plaats van alleen geïsoleerde woorden te herkennen.
Moderne AI-modellen trainen en testen
Om aan te tonen dat het corpus praktisch nuttig is, verfijnden de auteurs meerdere transformer-gebaseerde AI-modellen, waaronder meertalige versies van BERT en RoBERTa. Ze trainden deze modellen op twee taken: relatie-extractie, die leert de koppelingen tussen entiteiten te herstellen, en medische conceptnormalisatie, die tekst naar UMLS-codes mappt. Bij relatie-extractie behaalde het beste model een F1-score dicht bij 0,88, wat betekent dat het de meeste relaties correct identificeerde met relatief weinig fouten. Voor conceptnormalisatie raadde een meertalig model genaamd SapBERT, zonder extra training, bijna 90% van de tijd het juiste concept als eerste gok. Deze resultaten laten zien dat goed geannoteerde, middelgrote datasets nauwkeurige, efficiënte modellen kunnen aandrijven, zelfs zonder enorme algemene taalmodellen.
Waarom deze bron belangrijk is voor toekomstige zorg
Het CT-EBM-SP-corpus en de bijbehorende modellen vormen een basis voor tools die Spaanse teksten van klinische proeven automatisch kunnen ontleden, ze kunnen matchen met patiëntgegevens en cohortidentificatie in ziekenhuizen kunnen ondersteunen. Omdat de data zijn afgestemd op internationale medische standaarden en zorgvuldig door experts zijn gecontroleerd, kunnen ze ook helpen bij het ontwikkelen van vergelijkbare bronnen voor andere talen met minder digitale hulpmiddelen. In alledaagse termen draait dit werk om het gemakkelijker en veiliger maken dat de juiste patiënten de juiste proeven aangeboden krijgen, waardoor medische ontdekkingen versnellen terwijl de werklast voor zorgprofessionals vermindert.
Bronvermelding: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Trefwoorden: klinische proeven, medische tekstmining, Spaanse gezondheidszorg, transformermodels, evidence-based medicine