Clear Sky Science · nl
Filmniveaugegevens van Amazon X-Ray op de Amerikaanse markt gecombineerd met IMDb
Waarom filmscènes belangrijk zijn om cultuur te begrijpen
Films vormen onze kijk op de wereld, maar het merendeel van het onderzoek naar film richtte zich tot nu toe op kaartverkoop, basale genres of sterrencarrière, en niet op wat er daadwerkelijk in elke scène op het scherm gebeurt. Dit artikel introduceert een nieuwe dataset waarmee onderzoekers kunnen inzoomen op individuele scènes, personages en dialogen voor meer dan drieduizend films die in de VS op Amazon Prime Video werden gestreamd. Door Amazons X-Ray-functie te combineren met de Internet Movie Database (IMDb) bieden de auteurs een gedetailleerde, gestandaardiseerde kaart van wie waar en wanneer in elke film verschijnt, wat de deur opent naar rijkere studies van representatie, vertelkunst en zelfs AI-systemen die van video leren.
Van ruwe scripts naar voltooide scènes
Tot nu toe vertrouwden de meeste grootschalige filmonderzoeken op scripts of ondertitelingsbestanden. Deze bronnen zijn nuttig maar onvolmaakt. Scenario’s zijn vaak vroege versies die verschillen van de definitieve montage en kunnen kleine personages of late bewerkingswijzigingen weglaten. Ondertitels leggen gesproken regels vast, maar missen zwijgende personages, figuranten op de achtergrond en puur visueel vertellen—zoals de camera die blijft hangen op iemands gezicht. Vanwege deze lacunes moesten eerdere pogingen om te achterhalen wie met wie omgaat op het scherm of hoe verschillende groepen worden weergegeven, vaak raden op basis van tekst alleen, wat kan leiden tot fouten bij het identificeren van personages en hun relaties.
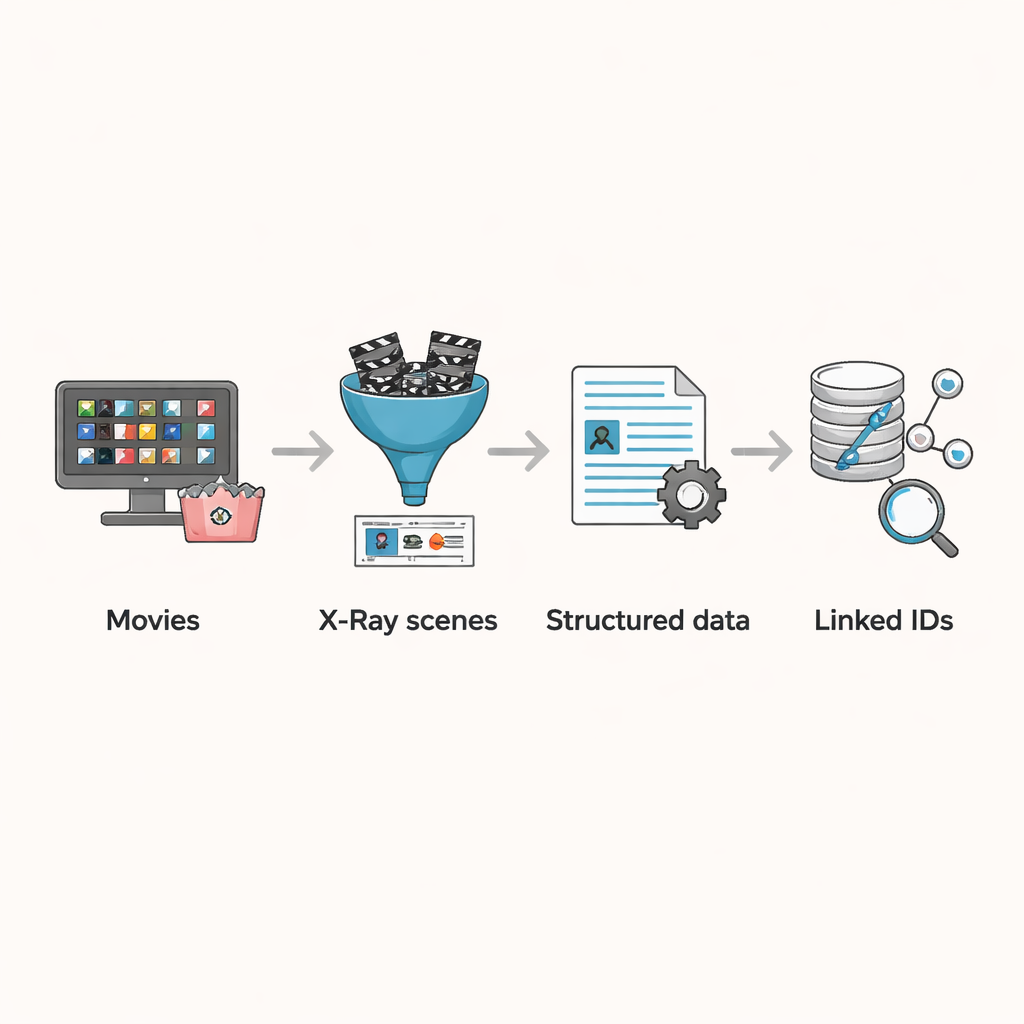
X-Ray omzetten naar onderzoeksklare data
Amazons X-Ray-functie biedt een manier om deze problemen te omzeilen. Wanneer kijkers een film pauzeren, toont X-Ray welke acteurs en personages op dat moment in beeld zijn—informatie die gecureerd is en direct gekoppeld aan de definitieve bewerkte film. De auteurs bouwden een pijplijn om deze scèneniveaugegevens te oogsten voor 3.265 films die in augustus 2023 in de Amerikaanse Prime Video-catalogus beschikbaar waren. Ze verzamelden eerst alle in Prime opgenomen filmentries, filterden degenen zonder X-Ray-informatie eruit en verwijderden duplicaten veroorzaakt door herhaalde titels of alternatieve versies. Voor elke overgebleven film onderschepten ze de datastromen die de speler gebruikt om X-Ray- en ondertitelinformatie te laden, waarbij ze de resultaten opsloegen in gestructureerde bestanden die scènelimieten, de personages in elke scène en, voor de meeste titels, de precieze timing van elk ondertitelsegment vermelden.
Scènes koppelen aan de bredere filmwereld
De echte kracht van de dataset komt voort uit het koppelen van deze scène-onderscheidingen aan externe informatie. Hoewel X-Ray elk personage al koppelt aan een IMDb-profiel, bevat het geen IMDb-ID voor de film zelf. De auteurs ontwierpen een matchingsalgoritme dat begint bij de filmtitel, meerdere kandidaat-overeenkomsten van IMDb ophaalt en vervolgens de top-gecrediteerde cast van IMDb vergelijkt met de in X-Ray vermelde acteurs. Als ten minste één hoofdacteur overeenkomt, wordt de film als match beschouwd. Dit geautomatiseerde proces koppelde het overgrote deel van de films correct, en het team controleerde daarna handmatig de resterende paar honderd randgevallen, herstelde foutclassificaties en verwijderde vermeldingen die geen verhalende films waren, zoals stand-up specials. Het eindresultaat is een zorgvuldig opgeschoonde set films waarin elke scène, elk personage en elke ondertitel gekoppeld kan worden aan rijke metadata zoals jaar, land en demografie van de cast.
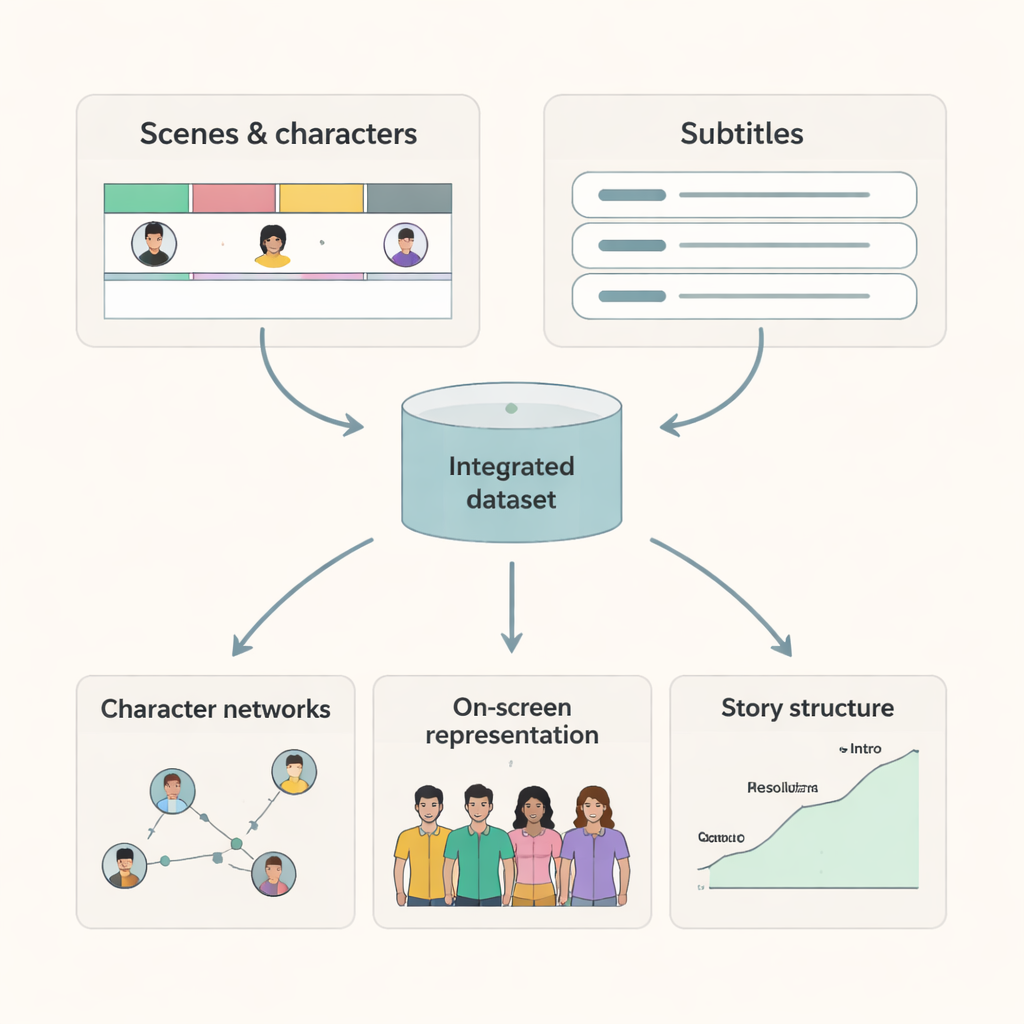
Wat onderzoekers met deze films kunnen doen
Omdat elke scène duidelijke begin- en eindtijden en een lijst met aanwezigen heeft, kunnen onderzoekers nu nauwkeurige kaarten van personage-interacties en schermtijd opbouwen. Ondertitels die op scènes zijn uitgelijnd maken het mogelijk om te bestuderen hoe taal verschilt tussen personages en contexten, of hoe bepaalde thema’s zich via dialogen ontvouwen. Door deze dataset te combineren met aanvullende informatie van IMDb en andere bronnen, kunnen wetenschappers vragen onderzoeken zoals: hoe is de genderbalans op het scherm in de loop van de decennia veranderd? Krijgen personages uit verschillende achtergronden gelijke narratieve aandacht? Hoe verschillen interactiepatronen tussen genres of landen? De dataset biedt ook een hoogwaardige benchmark voor AI-modellen die videoinhoud proberen te begrijpen, omdat het grondwaarheden levert over wie zichtbaar is en wanneer.
Een nieuwe lens op alledaagse films
Concreet maakt dit werk van duizenden films een doorzoekbare, scène-voor-scène catalogus van wie verschijnt, wie spreekt en hoe verhalen zijn opgebouwd. Hoewel de collectie beperkt is tot titels die beschikbaar zijn op de Amerikaanse Prime Video en afhankelijk is van Amazons interne X-Ray-processen, bestrijkt ze nog steeds films uit vele decennia en genres, niet alleen beroemde prijswinnaars. Die breedte stelt onderzoekers in staat alledaagse films te bestuderen, niet alleen de klassiekers die in herinnering blijven. Naarmate de dataset wordt bijgewerkt en uitgebreid, belooft hij ons begrip van hoe films de maatschappij weerspiegelen te verdiepen—en zowel sociale wetenschappers als technologen een getrouwer beeld te geven van wat er daadwerkelijk op het scherm gebeurt.
Bronvermelding: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Trefwoorden: filmdatabestanden, analyse op scèneniveau, Amazon X-Ray, IMDb-metadata, weergave op het scherm