Clear Sky Science · nl
Een multimodaal dataset van causale mechanismen in de literatuur over materiaalkunde
Waarom dit verder reikt dan het laboratorium
Het moderne leven hangt af van nieuwe materialen, van telefoonaccu’s tot medische implantaten. Toch is de kennis die wetenschappers vertelt welke bewerkingsstappen leiden tot welke structuren, eigenschappen en prestaties in de praktijk verspreid over miljoenen wetenschappelijke artikelen. Dit artikel beschrijft een grote, geordende "kaart" van die verborgen kennis, opgebouwd door kunstmatige intelligentie te combineren met menselijke expertise, zodat onderzoekers en toekomstige AI‑hulpmiddelen sneller betere materialen kunnen ontdekken.
Vier pijlers van materialen, één grote uitdaging
Materiaalkundigen denken vaak in termen van een "tetraëder" met vier hoeken: verwerking (hoe een materiaal wordt gemaakt of behandeld), structuur (hoe atomen en korrels zijn gerangschikt), eigenschappen (zoals sterkte of elektrische geleiding) en prestaties (hoe het zich in gebruik gedraagt). Onderzoekers willen niet alleen weten dat de ene hoek de andere beïnvloedt; ze willen de stapsgewijze mechanismen begrijpen die verklaren waarom een bepaalde warmtebehandeling een taaiere legering of een helderdere zonnecel oplevert. Die verklaringen liggen opgesloten in tekst, figuren en verwijzingen verspreid over decennia literatuur, wat ze moeilijk doorzoekbaar, vergelijkbaar of systematisch herbruikbaar maakt.
Versnipperde artikelen omzetten in gestructureerde kennis
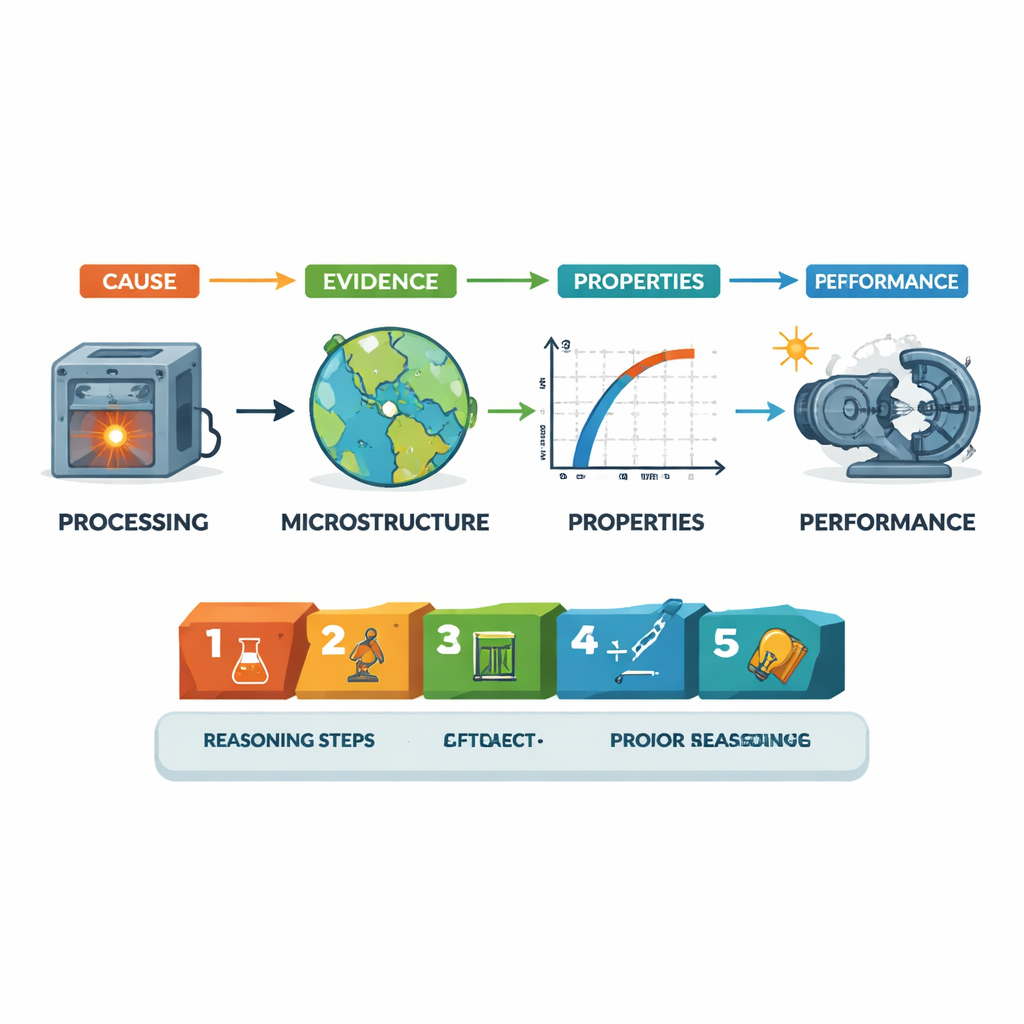
De auteurs stelden een corpus samen van meer dan 61.000 onderzoeksartikelen uit 15 belangrijke materiaaltijdschriften, met betrekking tot metalen, keramiek, polymeren, composieten, dunne films, nanomaterialen en biomaterialen. Met geavanceerde taalmodellen identificeerden ze het hoofdmateriaal in elk artikel en extraheerden ze de relevante bewerkingsstappen, structurele kenmerken, gemeten eigenschappen en prestatie-uitkomsten. Tegelijkertijd haalden ze de causale ketens eruit die deze elementen verbinden, zoals "verwerking → structuur → eigenschap", met focus op de kernwetenschappelijke beweringen van elke studie.
Zien wat beelden en experimenten werkelijk aantonen
Veel van het bewijs voor deze causale ketens komt uit afbeeldingen en experimenten. Het team trainde een beeldclassifier om microscopische opnamen te herkennen—zoals elektronenmicroscoopbeelden van korrelgrenzen—die rechtstreeks de innerlijke structuur van een materiaal tonen. Ze schreven ook routines om experimentele procedures en resultaten te vinden en samen te vatten, en om nieuwe bevindingen te scheiden van achtergrondkennis die uit eerder werk wordt geciteerd. Al deze informatie wordt opgeslagen in een uniform JSON‑formaat: elke causale link wordt ondersteund door specifieke experimenten, afbeeldingen en externe kennis, samen met een stapsgewijze redeneerketen die uiteenzet hoe de auteurs van oorzaak naar gevolg redeneren.
Controleren op fouten en meningsverschillen
Aangezien AI wetenschappelijke tekst kan verkeerd lezen of overinterpreteren, bouwden de auteurs waarborgen in hun verwerkingsketen. Ze gebruikten een speciaal model om mogelijke "hallucinaties" aan te wijzen—uitspraken die niet duidelijk door het originele artikel worden ondersteund—en om een betrouwbaarheidscore toe te kennen aan elk geëxtraheerd bewijsstuk. Ze zochten ook naar tegenstrijdigheden door soortgelijke zinnen in verschillende artikelen te vergelijken en te vragen of twee papers conflicterende beweringen rapporteren over hetzelfde type mechanisme. Menselijke experts in materiaalkunde valideerden vervolgens een zorgvuldig gekozen steekproef. Over het geheel genomen bereikte het systeem nauwkeurigheden rond of boven 95% voor het identificeren van materialen, afbeeldingen en mechanismen, en bleek dat expliciete tegenstrijdigheden en hallucinaties in de uiteindelijke dataset relatief zeldzaam blijven.
Wat de dataset over materiaalkunde onthult
Met honderdduizenden mechanismen en meer dan een miljoen stukken ondersteunend bewijs biedt de dataset een panoramisch beeld van hoe moderne materiaalkunde wordt beoefend. Hij laat bijvoorbeeld zien dat studies meestal het klassieke pad volgen van verwerking naar structuur, vervolgens naar eigenschappen en prestaties, en dat verklaringen typisch compacte redeneerketens van ongeveer vijf stappen gebruiken. De verzameling beslaat diverse materiaalt types en chemische elementen, met bijzonder veel aandacht voor nanomaterialen en coatings, en volgt hoe interesses zich over decennia hebben verplaatst—van puur mechanische sterkte in metalen naar elektrische en optische eigenschappen in nanomaterialen en composieten.
Hoe dit toekomstige ontdekkingen helpt
Voor niet‑specialisten is het belangrijkste resultaat een doorzoekbare, gestructureerde kaart van hoe wetenschappers oorzakelijk verband denken over en verantwoorden in materialen. In plaats van honderden artikelen te lezen, kan een onderzoeker—of een AI‑assistent—de dataset raadplegen om alle verwerkingsroutes te vinden die rapporteren dat ze bijvoorbeeld de taaiheid van een titaniumlegering verbeteren, samen met de afbeeldingen en experimenten die die beweringen ondersteunen. Door kennis op mechanisme‑niveau over veel studies te organiseren, legt dit werk een basis voor meer transparante, uitlegbare AI‑hulpmiddelen die niet alleen veelbelovende nieuwe materialen kunnen voorspellen, maar ook duidelijk kunnen verklaren waarom ze zouden werken.
Bronvermelding: Liu, Y., Wang, C., Liu, J. et al. A multimodal dataset of causal mechanisms in materials science literature. Sci Data 13, 269 (2026). https://doi.org/10.1038/s41597-026-06598-5
Trefwoorden: materiaalkunde, causale mechanismen, multimodaal dataset, grote taalmodellen, structuur–eigenschapsrelaties