Clear Sky Science · nl
Reconstructie van extreme zeeniveaus langs de Chinese kust met meerdere deep learning-modellen
Waarom kustwaterstanden van belang zijn voor het dagelijks leven
China’s lange kustlijn is de thuis van honderden miljoenen mensen, grote havens en snelgroeiende steden. Wanneer krachtige stormen de zee het land in duwen, kunnen de daardoor ontstane hoge waterstanden wijken onder water zetten, infrastructuur beschadigen en drinkwater met zout vervuilen. Gedetailleerde gegevens over zulke extreme kustwaterstanden zijn echter verrassend schaars en gefragmenteerd. Deze studie vult die leemte door vijftig jaar aan dagelijkse hoge waterstanden langs grote delen van China’s kust te reconstrueren, waarbij moderne kunstmatige-intelligentietools worden gebruikt om onsamenhangende waarnemingen en weerreanalysegegevens om te zetten in een consistent, openbaar beschikbaar dataset.
Het op- en neergaan van de zee volgen
Kustwaterstanden worden bepaald door twee hoofdcomponenten: de regelmatige aantrekking van maan en zon die getijden veroorzaakt, en stormvloed, tijdelijke waterophopingen die door lage luchtdruk en sterke winden tijdens cyclonen en andere weersystemen naar de kust worden geduwd. In China vallen tropische cyclonen en andere stormen vaak samen met al hoge getijden, wat vooral gevaarlijke omstandigheden geeft. Veel getijdemetingen bij peilstations zijn echter kort of onderbroken, en sommige zijn niet publiek toegankelijk. Daardoor is het voor wetenschappers en planners moeilijk te begrijpen hoe extreme zeeniveaus van plaats tot plaats en van decennium tot decennium variëren langs deze sterk blootgestelde kustlijn.
Slimme modellen gebruiken om de ontbrekende gegevens in te vullen
De auteurs benaderden dit probleem door moderne deep learning-technieken te combineren met traditionele getijdeanalyse. Ze concentreerden zich op 23 peilstations verspreid langs China’s kust en verzamelden gedetailleerde weerinformatie uit de ERA5 wereldreanalyse, waaronder luchtdruk en winden nabij het oppervlak over een vak van 10 bij 10 graden rond elk station. Deze weerspatronen werden gebruikt om verschillende soorten neurale netwerken te leren hoe de dagelijkse maximale stormvloed samenhangt met de omliggende atmosfeer. Tegelijk gebruikte het team een tool genaamd UTide om de voorspelbare getijdesignalen uit de historische zeeniveaurecords te halen, zodat ze de regelmatige op- en neergang van het getij konden scheiden van het meer onregelmatige vloedcomponent.
Verschillende varianten van deep learning testen
In plaats van op één algoritme te vertrouwen, vergeleek de studie systematisch vier deep learning-modellen: een Long Short-Term Memory (LSTM)-netwerk, een hybride CNN-LSTM die eerst ruimtelijke patronen leest, een ConvLSTM die ruimte en tijd samen afhandelt, en een Informer-model gebaseerd op de Transformer-architectuur die bekend is uit taalverwerking. Om de modellen efficiënt te houden comprimeerden de onderzoekers de grote weervelden met hoofdcomponentenanalyse voordat ze gingen trainen. Ze voedden elk model ook met een 24-uursgeschiedenis van atmosferische condities en gebruikten attention-mechanismen zodat het netwerk zich op de belangrijkste momenten kon concentreren. Voor elk station reserveerden ze ongeveer 20% van de reeks als een onafhankelijke testperiode en selecteerden ze het model dat daar het beste presteerde voor de uiteindelijke reconstructie.
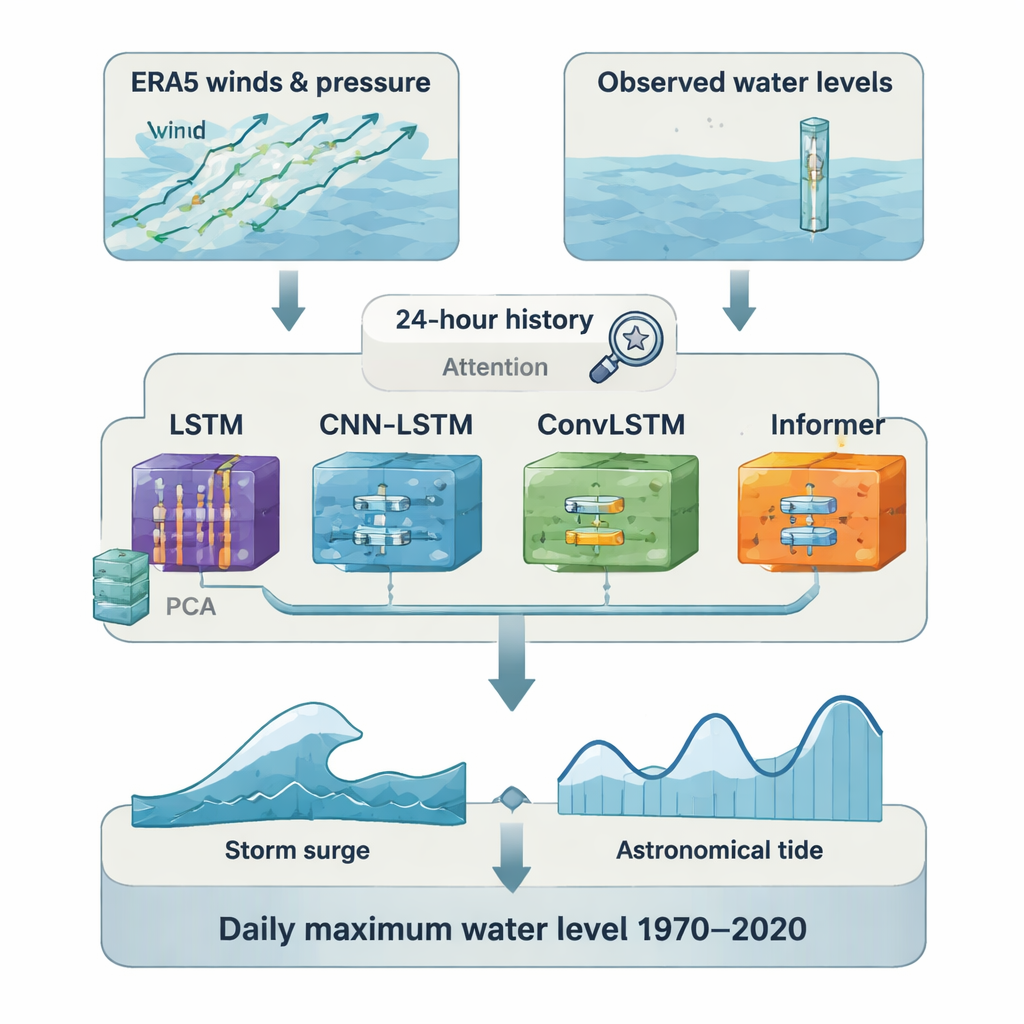
Vijftig jaar hoge waterstanden herbouwen
Eenmaal getraind werd het best presterende model per locatie gebruikt om de dagelijkse maximale stormvloed te reconstrueren voor de gehele periode 1970–2020. Deze schattingen van de vloed werden vervolgens opgeteld bij de respectieve astronomische getijden uit UTide om dagelijkse maximale totale waterstanden te produceren. Omdat de hoogste getijde en de hoogste vloed op een gegeven dag meestal op licht verschillende tijden voorkomen, vormt deze eenvoudige optelling een bovengrens van wat zich werkelijk voordeed; tests met uurlijkse data suggereren dat deze overschatting gemiddeld ongeveer 15 centimeter bedraagt, of ruwweg 15%. Zelfs met deze conservatieve bias komen de gereconstrueerde reeksen goed overeen met waargenomen gegevens waar die bestaan: gemiddeld is de correlatie tussen gereconstrueerde en waargenomen dagelijkse maxima ongeveer 0,9, en liggen de fouten in de orde van enkele tientallen centimeters, ook voor zeer hoge waterstanden boven het 95e percentiel.
Wat dit betekent voor kusten en gemeenschappen
Voor wetenschappers, ingenieurs en kustplanners biedt de nieuwe dataset een gedetailleerd, consistent beeld van hoe extreme zeeniveaus zich langs China’s kust hebben gedragen in de afgelopen halve eeuw. Het presteert beter dan meerdere veelgebruikte globale producten, vooral tijdens tyfoons en andere extreme situaties, en wordt geleverd met volledige metadata, code en prestatiedata zodat anderen het kunnen hergebruiken en kritisch kunnen beoordelen. Voor het brede publiek betekent dit dat beoordelingen van overstromingsrisico’s, zeewalontwerp, evacuatieplanning en langetermijnaanpassing nu kunnen leunen op veel rijkere informatie dan voorheen beschikbaar was. In eenvoudige bewoordingen: door computers te leren decennia van stormgestuurde hoge getijden “af te spelen”, biedt de studie een sterkere wetenschappelijke basis om kustgemeenschappen te beschermen tegen de gevaren van vandaag en zich voor te bereiden op de stijgende zeespiegel van morgen.
Bronvermelding: Fang, J., Huang, J., Bian, W. et al. Reconstruction of Extreme Sea Levels in coastal China using Multiple Deep Learning models. Sci Data 13, 268 (2026). https://doi.org/10.1038/s41597-026-06593-w
Trefwoorden: stormvloed, extreem zeeniveau, kustoverstroming, deep learning, kustlijn van China