Clear Sky Science · nl
CNeuroMod-THINGS, een dicht bemonsterde fMRI-dataset voor visuele neurowetenschap
Waarom naar plaatjes kijken kan onthullen hoe onze geest werkt
Elke dag verwerken onze ogen duizenden beelden — van koffiekopjes en smartphones tot honden, bomen en drukke straten. Achter de schermen herkent ons brein razendsnel wat we zien en slaat het die informatie vaak later op. Het CNeuroMod-THINGS-project wilde deze verborgen activiteit in uitzonderlijk detail vastleggen en creëerde daarmee een van de meest diepgaand gemeten hersendatasets ooit verzameld terwijl mensen naar foto's uit de echte wereld kijken. Deze bron is bedoeld om de volgende generatie onderzoek naar het brein en artificiële intelligentie aan te jagen.
Een rijke bibliotheek van hersenreacties opbouwen
In plaats van honderden proefpersonen één of twee keer te scannen, scanden de onderzoekers herhaaldelijk slechts vier uitzonderlijk toegewijde deelnemers. Elke persoon kwam 33 tot 36 keer terug, wat in het bredere CNeuroMod-project neerkwam op ongeveer 200 uur aan brain‑imaging en tientallen uren uitsluitend gewijd aan plaatjes. Tijdens deze sessies zagen de vrijwilligers tot 4.320 verschillende foto’s uit de THINGS‑beeldcollectie, die 720 alledaagse objectcategorieën omvat zoals gereedschap, dieren, voertuigen en meubels. Deze zorgvuldige keuze van afbeeldingen zorgt ervoor dat veel hoeken van onze visuele wereld worden vertegenwoordigd, niet slechts een paar populaire objecten.

Een geheugenspel in de MRI-scanner
Om de deelnemers betrokken te houden en het geheugen te bevragen, maakten de onderzoekers van het bekijken van plaatjes een continu herkenningsspel. Bij elke proef verscheen één afbeelding in het midden van het scherm terwijl de persoon in een MRI-scanner lag. Met een op maat gemaakte, videogame‑achtige controller gaven deelnemers aan of ze dachten dat de afbeelding nieuw was of al eerder was gezien, en hoe zeker ze waren van die inschatting. De meeste afbeeldingen werden drie keer getoond: eenmaal bij de eerste ontmoeting, nogmaals enkele minuten later tijdens dezelfde sessie, en een derde keer in een latere sessie, vaak ongeveer een week later. Dit ontwerp stelde het team in staat om kortetermijn‑ en langduriger geheugen voor precies dezelfde plaatjes te vergelijken en tegelijkertijd de corresponderende veranderingen in hersenactiviteit te volgen.
Gedetailleerde signalen van visie en geheugen vastleggen
De dataset gaat veel verder dan simpele "aan/uit"-maatstaven van hersenactiviteit. De auteurs gebruikten geavanceerde analysemethoden om voor elke afzonderlijke proef en voor elke afbeelding een aparte respons te schatten in elk klein driedimensionaal pixelletje (voxel) van de hersenscan. Ze volgden ook waar mensen naar keken met oogvolgcamera’s, registreerden ademhaling en hartslag, en maten hoofdbeweging. Kwaliteitscontroles tonen aan dat de signalen opmerkelijk stabiel zijn: deelnemers reageerden op bijna elke proef, hielden hun blik dicht bij het midden van het scherm en bewogen zeer weinig. In belangrijke visuele gebieden — regio’s die bekend staan om sterke reacties op gezichten, lichamen of scènes — produceerde dezelfde afbeelding telkens zeer consistente activiteitspatronen. Deze patronen waren zo sterk dat, wanneer de responsen werden uitgezet in een vereenvoudigde tweedimensionale kaart, afbeeldingen met vergelijkbare betekenis (bijvoorbeeld dieren of voertuigen) geneigd waren bij elkaar te clusteren.
In kaart brengen waar verschillende hersengebieden om geven
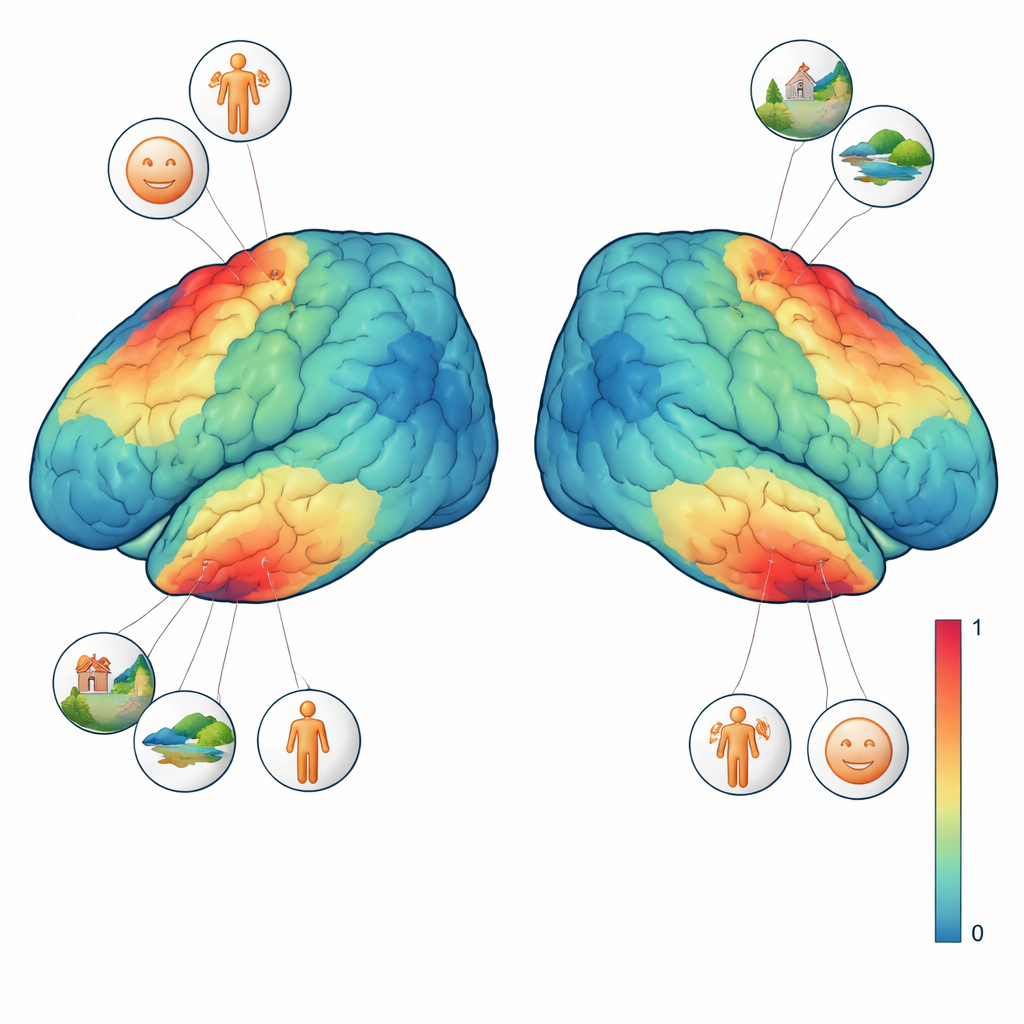
Om deze signalen beter te interpreteren, voltooiden drie van de vier deelnemers aanvullende visietests. In een test bewogen brede vormen over een getextureerde achtergrond om te onthullen welk deel van het gezichtsveld elk hersengebied "ziet". In een andere test werden korte blokken met gezichten, plaatsen, lichaamsdelen, personages en generieke objecten getoond om regio’s te bepalen die de voorkeur geven aan één type beeld boven anderen. Door deze localizer‑taken te combineren met het hoofdexperiment kon het team precieze vragen stellen zoals: reageert een enkele voxel sterker wanneer er een gezicht aanwezig is, of wanneer de hele scène zichtbaar is? Ze vonden dat gezicht‑selectieve regio’s het sterkst reageerden telkens wanneer eender welk soort gezicht verscheen, terwijl een scène‑selectieve regio de voorkeur gaf aan beelden met rijke achtergronden zoals kamers, straten of landschappen, zelfs wanneer er geen mensen zichtbaar waren. Deze fijnmazige voorkeuren deden zich voor op het niveau van individuele afbeeldingen en zelfs enkele voxels.
Een fundament voor slimere modellen van visie
In wezen is CNeuroMod-THINGS een zorgvuldig samengestelde publieke bron in plaats van een eenmalig resultaat. Alle hersengegevens, oogvolginformatie, gedragsreacties, afbeeldingsannotaties en analysecode worden vrij gedeeld onder een open licentie. Omdat dezelfde vier personen in veel andere taken zijn gescand — films kijken, videogames spelen, naar verhalen luisteren — kunnen onderzoekers nu gedetailleerde, persoonspecifieke modellen bouwen die gecontroleerde experimenten koppelen aan meer natuurlijke ervaringen. Voor niet‑specialisten is de kernboodschap dat we nu een hoge‑resolutie "naslagtabel" hebben die laat zien hoe een echt menselijk brein reageert op duizenden alledaagse plaatjes. Dit zal wetenschappers helpen ideeën over visuele waarneming en geheugen te toetsen en het ontwerp van kunstmatige visiesystemen sturen die de wereld iets meer zien zoals wij dat doen.
Bronvermelding: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
Trefwoorden: fMRI, visuele waarneming, objectherkenning, hersengegevens, geheugen