Clear Sky Science · nl
Semantische afstemming van het metadata-model van het German Human Genome-Phenome Archive in Europa’s genomica
Waarom het delen van genoomgegevens meer vereist dan alleen bestanden
De moderne geneeskunde is steeds meer afhankelijk van het uitlezen van ons DNA om ziekten te diagnosticeren en behandelingen te personaliseren. Maar de echte kracht van genomica ontstaat wanneer gegevens uit veel ziekenhuizen en landen gecombineerd kunnen worden. Dat werkt alleen als elke dataset op een heldere, compatibele manier wordt beschreven en als privacywetten zoals Europa’s AVG strikt worden nageleefd. Dit artikel legt uit hoe het German Human Genome-Phenome Archive (GHGA) een gedetailleerd "beschrijvingssysteem" voor genomische studies opbouwt, zodat waardevolle gegevens vindbaar, begrijpelijk en veilig deelbaar zijn in heel Europa.
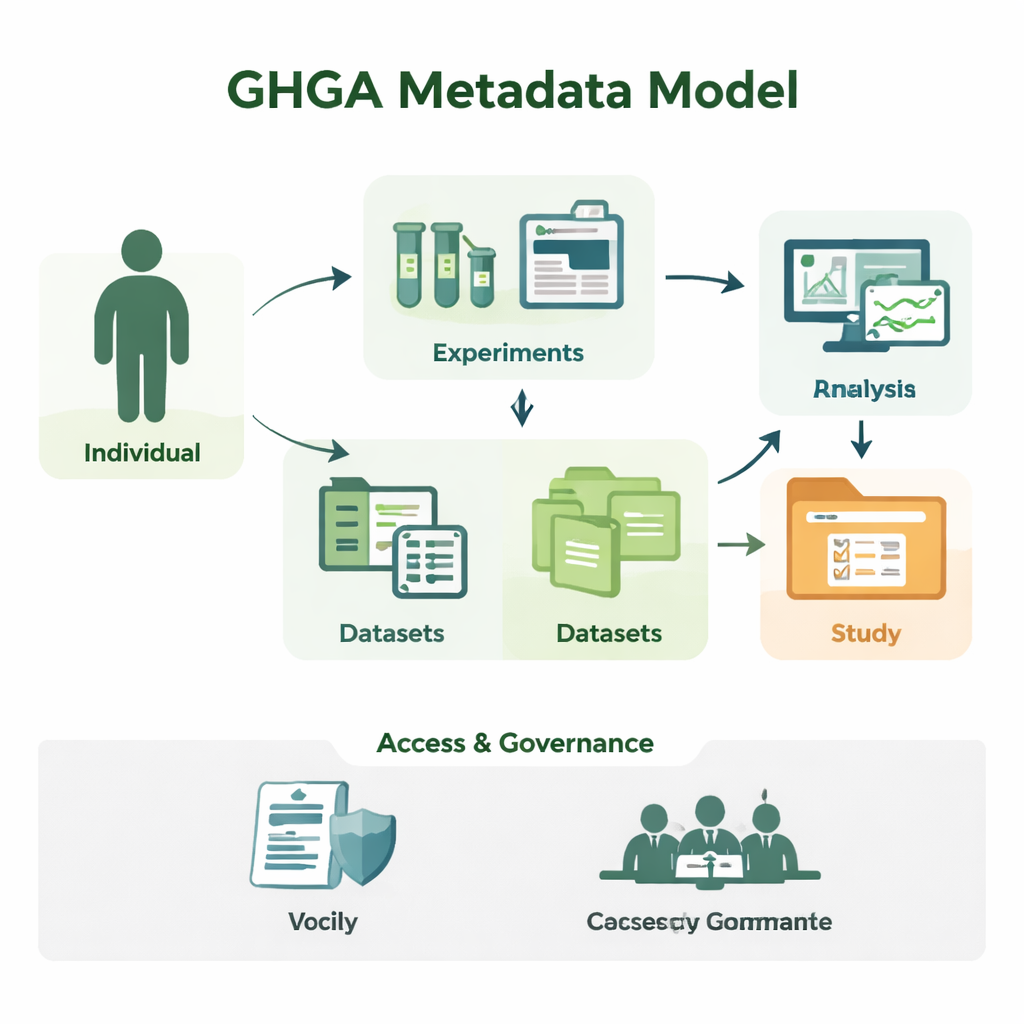
Van ruwe sequenties naar begrijpelijke studies
Genomisch onderzoek produceert enorme hoeveelheden sequentiegegevens, maar op zichzelf is een bestand met DNA-letters zinloos. Onderzoekers moeten weten van wie het monster afkomstig is, welk weefsel is gebruikt, hoe het experiment is uitgevoerd en onder welke voorwaarden de gegevens hergebruikt mogen worden. GHGA legt deze omgevingsinformatie vast als metadata. Het model organiseert metadata in 16 bouwstenen, zoals de deelnemende persoon (de "Individu"), het genomen monster, het uitgevoerde experiment en de analyse, de aangemaakte databestanden en de datasets en studies die deze bundelen. Door wetenschappelijke details te scheiden van administratieve zaken zoals toegangsvoorwaarden, weerspiegelt het model hoe een echt laboratorium en dataportaal werken, maar op een manier die computers betrouwbaar kunnen verwerken.
Gegevens bruikbaar houden maar personen onidentificeerbaar
Aangezien GHGA gevoelige menselijke gezondheidsgegevens beheert, moest het team het model zo ontwerpen dat het wetenschappelijk rijk is zonder het gemakkelijk te maken een persoon achter de gegevens te identificeren. Europese AVG-regels stellen dat informatie die redelijkerwijs aan een individu kan worden gekoppeld als persoonsgegevens geldt, ook als namen zijn verwijderd. Het artikel beschrijft een zorgvuldige privacyanalyse die aantoonde hoe het combineren van details zoals leeftijd, postcode en zeldzame diagnoses identiteiten kan blootleggen. Als reactie daarop vermijdt het publieke portaal van GHGA fijnmazige locatiedata, worden leeftijden gegroepeerd in brede banden in plaats van exacte jaren, en worden gedetailleerde diagnosecodes samengevoegd tot grovere categorieën. Op deze manier kunnen onderzoekers nog steeds inschatten of een dataset relevant is voor hun werk, terwijl de inspanning om een persoon te identificeren onrealistisch wordt.
Controle op compatibiliteit met Europa’s genomica-ecosysteem
Om echt nuttig te zijn, moet GHGA’s metadata passen binnen een breder Europees netwerk van genomische archieven en hulpmiddelen. De auteurs vergeleken hun model daarom, item voor item, met vier andere veelgebruikte kaders: twee versies van het European Genome-phenome Archive (EGA), de ISA-tab-standaard en het FAIR Genomes-model uit de Nederlandse gezondheidszorg. Ze voerden een gedetailleerde "crosswalk" uit die voor elk GHGA-veld vroeg of er een equivalent bestond in de andere modellen en andersom. Ze vonden dat de meeste van GHGA’s sleutelattributen duidelijke tegenhangers hebben elders, vooral voor het beschrijven van studies, monsters, experimenten, analyses en bestandsformaten. Dit betekent dat GHGA-datasets begrepen en geïntegreerd kunnen worden naast data die in andere Europese systemen zijn opgeslagen.
Gedeelde basis — en wat nog ontbreekt
Uit deze vergelijking haalde het team 25 "consensus"-metadatavelden die in ten minste drie van de vijf modellen voorkomen. Deze dekken essentiële zaken zoals het geslacht en de gezondheidstoestand van deelnemers, het gebruikte weefsel, het type sequencing en instrument, de analysemethode, bestandsformaten en basisbeschrijvingen van studies en contactgegevens. Deze gedeelde velden stemmen overeen met bestaande minimale rapportagerichtlijnen en kunnen dienen als een kern-checklist voor iedereen die nieuwe genomische dataportalen ontwerpt. Tegelijkertijd onthulde de analyse informatie die sommige modellen vastleggen maar die GHGA momenteel weglaat of alleen in flexibele, vrije-tekstvorm accepteert, zoals exacte datums van bemonstering en sequencing, uitgesloten diagnoses en gedetailleerde contactnamen. Veel van deze weglatingen zijn bewuste afwegingen ten gunste van privacy en anonimiteit.
Wat dit betekent voor toekomstig gezondheidsonderzoek
Samenvattend laat de studie zien dat GHGA’s metadata-model gedetailleerd, flexibel en nauw afgestemd is op internationale praktijk, terwijl het binnen strikte Europese privacyregels blijft. Het dekt al alle velden die andere archieven als verplicht zien en kan worden uitgebreid naar nieuwe technologieën zoals single-cell en spatial omics. Door een heldere manier te bieden om te beschrijven wie en wat een genomische studie omvat, hoe de gegevens zijn geproduceerd en onder welke voorwaarden ze hergebruikt kunnen worden, helpt GHGA geïsoleerde datasilo’s om te zetten in een verbonden onderzoeksbron. Voor patiënten vergroot dit de kans dat hun, eenmaal gedoneerde, gegevens veilig kunnen bijdragen aan ontdekkingen en betere behandelingen over grenzen heen, voor jaren vooruit.
Bronvermelding: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Trefwoorden: delen van genomische gegevens, metadata-standaarden, privacy en AVG, GHGA, gepersonaliseerde geneeskunde