Clear Sky Science · nl
SEA CDM: Study-Experiment-Assay Common Data Model en databases voor domeinoverschrijdende data-integratie en analyse
Waarom het organiseren van laboratoriumgegevens ons allemaal aangaat
De moderne geneeskunde wordt aangedreven door bergen experimentele gegevens — van vaccinproeven en infectiestudies tot kanker-genoomanalyse. Deze gegevens zitten echter vaak vast in onverenigbare formaten, waardoor het moeilijk is voor wetenschappers om resultaten te combineren en belangrijke patronen te ontdekken, zoals wie het beste op een vaccin reageert of waarom sommige mensen meer bijwerkingen hebben. Dit artikel beschrijft een nieuwe manier om diverse biomedische experimenten te ordenen en met elkaar te verbinden, zodat onderzoekers rijkere vragen kunnen stellen en sneller, betrouwbaarder antwoorden krijgen die uiteindelijk invloed hebben op hoe we ziekten voorkomen en behandelen.
Een gemeenschappelijke taal voor experimenten
Verschillende onderzoeksgroepen en databases beschrijven hun studies vaak op hun eigen manier, zelfs wanneer ze zeer vergelijkbaar werk doen. De ene database richt zich misschien op vaccinproeven, een andere op genactiviteit in individuele cellen, en een derde op klinische uitkomsten, elk met verschillende labels en structuren. Het Study–Experiment–Assay Common Data Model, of SEA CDM, biedt een eenvoudige gedeelde “grammatica” voor al deze inspanningen. Het splitst elk biomedisch project in drie verbonden stappen: de algemene studie die een vraag stelt, de experimenten die op mensen of dieren worden uitgevoerd, en de assays — zoals bloedtests of metingen van genexpressie — die resultaten opleveren. Rond deze stappen standaardiseert het model ook sleutel-elementen zoals wie of wat bestudeerd werd, welke monsters zijn genomen, welke behandelingen zijn toegepast en welke analyses zijn uitgevoerd. 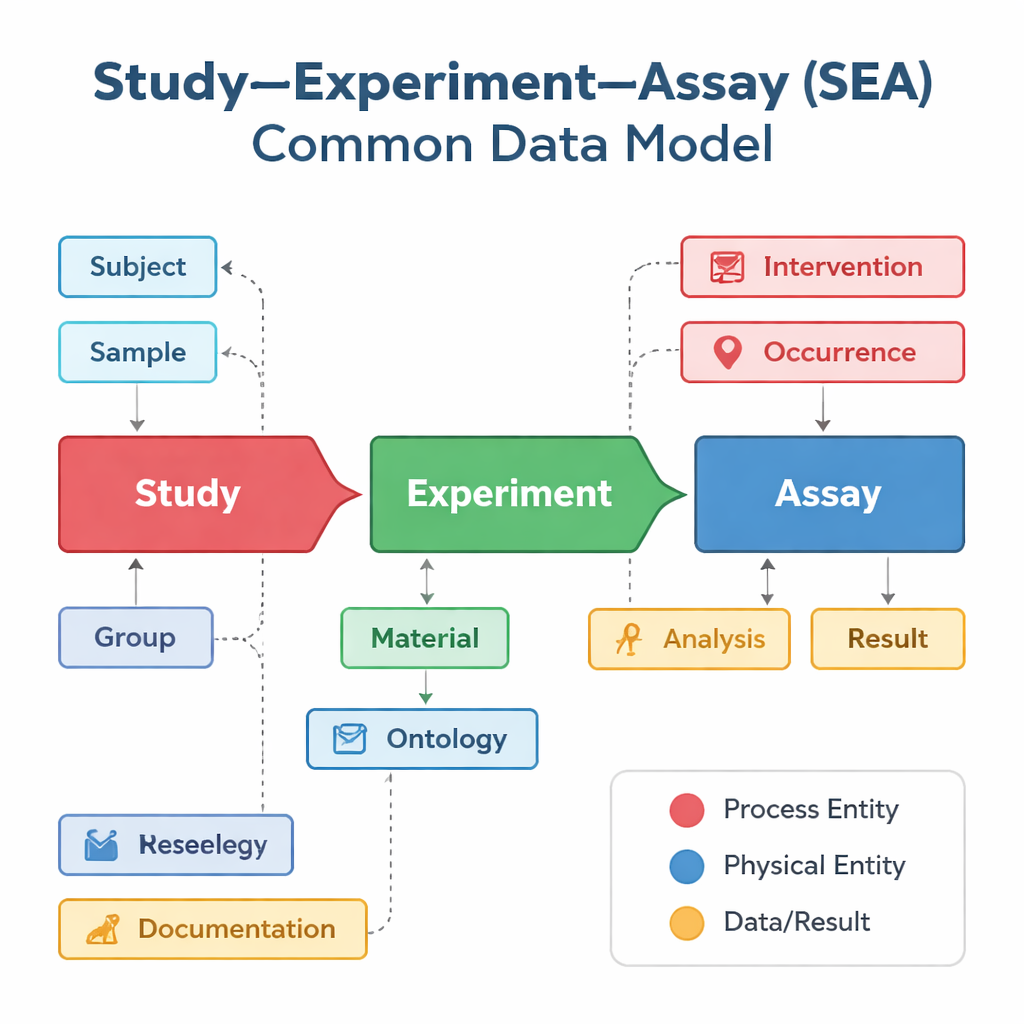
Ontologieën: labels omzetten in kennis
Alleen kolomkoppen op één lijn zetten is niet genoeg; hetzelfde concept kan op verschillende plaatsen anders worden genoemd. SEA CDM leunt op gecureerde vocabularia, bekend als ontologieën, om ervoor te zorgen dat “griepprik”, “trivalente geïnactiveerde influenzavaccin” en een merknaam zoals “Fluzone” als verwante begrippen worden herkend. Deze ontologieën zijn gestructureerd als stambomen van medische en biologische termen. Omdat SEA CDM elk variabele koppelt aan een officiële identifier uit een ontologie — zoals een ziekte, celtype of vaccin — kunnen computers automatisch deze bomen volgen, alle relevante records vinden en zelfs relaties afleiden. Bijvoorbeeld: een korte zoekopdracht kan elke studie ophalen die een trivalent influenzavaccin gebruikte uit honderden benoemde producten, wat krachtige, semantische zoekopdrachten mogelijk maakt die veel verder gaan dan eenvoudige trefwoordmatching. 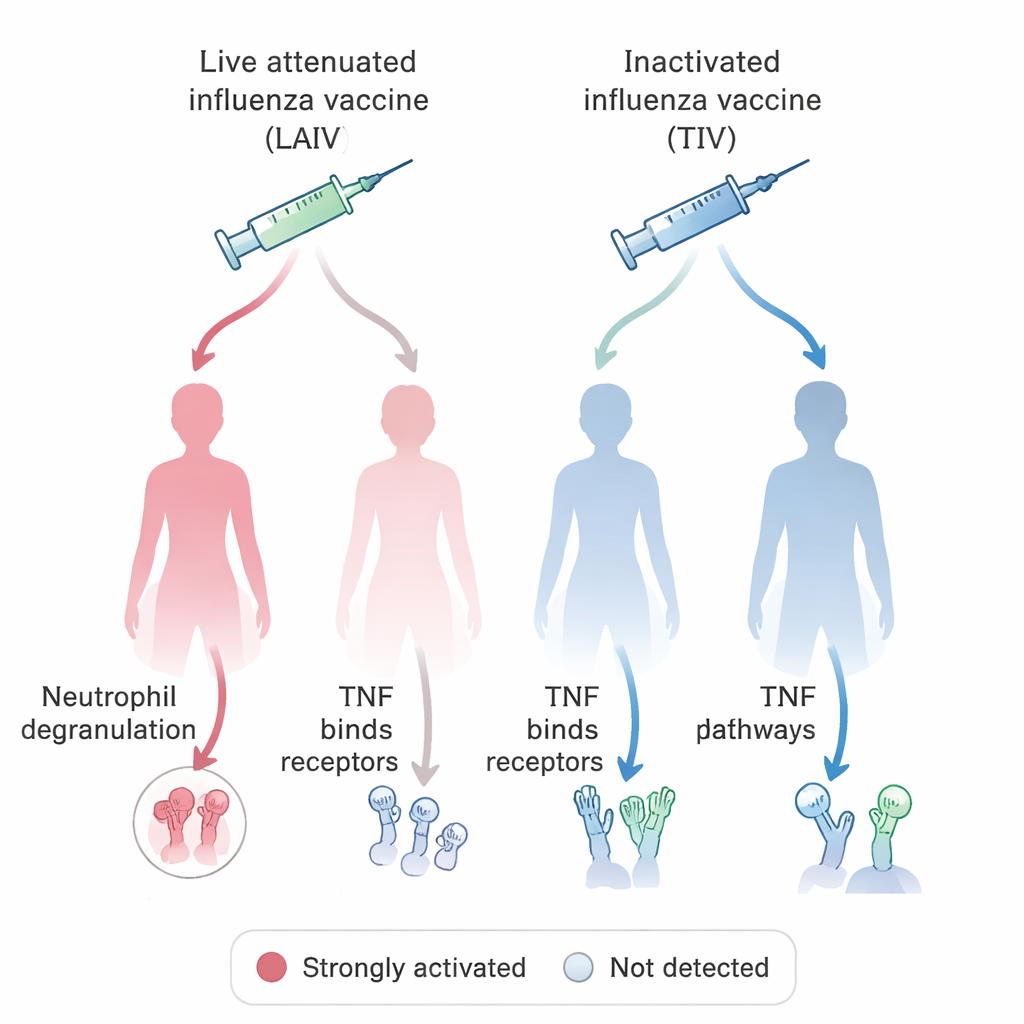
Van verspreide bestanden naar verbonden databases
Om hun model in de praktijk te testen, bouwden de auteurs een familie van databases en hulpmiddelen onder de koepelnaam OSEAN. Ze zetten drie grote openbare bronnen om naar de SEA CDM-structuur: ImmPort, dat metadata van immuunresponsstudies herbergt; VIGET, dat vaccinstudies koppelt aan genactiviteitsgegevens; en CELLxGENE, dat zich richt op single-cell-metingen. Met behulp van aangepaste pijplijnen vertaalden ze tientallen oorspronkelijke tabellen en bestandsformaten naar een consistente set van SEA CDM-tabellen of graafknopen. Dit stelde hen in staat meer dan duizend immuun-gerelateerde studies, meer dan twee miljoen monsters en talrijke beschrijvingen van vaccins, ziekten en labmethoden op te slaan in één coherent raamwerk dat met dezelfde software doorzocht kan worden.
Wat verenigde data kan onthullen over vaccins en sekseverschillen
Met dit geharmoniseerde systeem vroeg het team een biologisch vraagstuk van directe medische relevantie: hoe stimuleren verschillende influenza-vaccins het immuunsysteem bij vrouwen en mannen? Door de VIGET-gebaseerde OSEAN-database te bevragen en eenvoudige regels toe te passen voor wat telt als een “gestimuleerd” gen, identificeerden ze honderden genen waarvan de activiteit toenam na vaccinatie met ofwel levend verzwakte griepvaccins (met verzwakt virus) of geïnactiveerde, “gedode” vaccins. Vervolgens vergeleken ze de paden waarin deze genen deelnemen, en scheidden de gegevens op sekse. Een opvallend patroon betrof neutrofielen, een type witte bloedcel dat microben aanvalt door toxische korrels vrij te geven, en signalering via TNF, een belangrijke ontstekingsmolecuul. In de meeste groepen was influenzavaccinatie gekoppeld aan aanwijzingen voor neutrofieldegranulatie, maar dit signatuur ontbrak bij vrouwen die het levend verzwakte vaccin kregen. Daarentegen was TNF-gerelateerde signalering juist opvallend aanwezig bij deze vrouwen, maar niet in de overeenkomstige mannengroepen. Deze bevindingen sluiten aan bij dierstudies die suggereren dat neutrofielgedrag en vaccinresponsen systematisch kunnen verschillen tussen mannen en vrouwen.
Het opbouwen van een ecosysteem voor toekomstige ontdekkingen
De auteurs betogen dat de echte kracht van SEA CDM ligt in het FAIRer maken van biomedische data — vindbaar, toegankelijk, interoperabel en herbruikbaar. Door experimenten een gedeelde structuur te geven en elk belangrijk label te verankeren aan een goed gedefinieerde ontologieterm, maakt hun systeem het veel gemakkelijker om data uit verschillende bronnen te combineren, te traceren hoe monsters werden behandeld en analyses te reproduceren. De casestudy rond influenza toont dat zelfs relatief simpele zoekopdrachten, uitgevoerd over een geharmoniseerde database, subtiele, sekse-specifieke patronen in vaccinrespons kunnen blootleggen die invloed kunnen hebben op dosering of vaccinkeuze. Naarmate meer bronnen dit gemeenschappelijke model en de bijbehorende hulpmiddelen adopteren, zullen onderzoekers beter in staat zijn om aanwijzingen te verbinden over ziekten, technologieën en populaties heen, en gefragmenteerde datasets om te zetten in een echt geïntegreerd biodata-ecosysteem.
Bronvermelding: Huffman, A., Yeh, FY., Hur, J. et al. SEA CDM: Study-Experiment-Assay Common Data Model and Databases for Cross-Domain Data Integration and Analysis. Sci Data 13, 238 (2026). https://doi.org/10.1038/s41597-026-06558-z
Trefwoorden: data-integratie, biomedische ontologie, vaccinrespons, sekseverschillen, kennisgraaf