Clear Sky Science · nl
Een dataset van elektronische product-koolstofvoetafdrukken voor vraag-antwoordsystemen
Waarom de koolstofkost van je apparaten ertoe doet
Elke laptop, tablet of desktopcomputer die je gebruikt draagt een verborgen klimaatprijs. Lang voordat je de aan/uit-knop indrukt, zijn er al energie en materialen verbruikt voor het delven van metalen, het produceren van chips en het assembleren van apparaten. Bedrijven publiceren tegenwoordig rapporten waarin deze “belichaamde” CO2‑emissies worden geschat, maar die zijn verspreid over duizenden moeilijk leesbare PDF‑bestanden. Dit artikel introduceert een nieuwe dataset die die rommelige rapporten omzet in doorzoekbare, vergelijkbare informatie, waardoor het voor onderzoekers, beleidsmakers en uiteindelijk consumenten makkelijker wordt om de klimaatimpact van alledaagse elektronica te begrijpen en te verminderen.
Verspreide rapporten omzetten in bruikbare data
Grote computerfabrikanten zoals HP, Dell, Lenovo en Acer publiceren product‑koolstofvoetafdrukhapporten waarin wordt beschreven hoeveel broeikasgassen gedurende de levensduur van een apparaat vrijkomen, en hoeveel daarvan afkomstig is van verschillende onderdelen zoals het scherm, de batterij of printplaten. Helaas formatteert elk bedrijf deze documenten anders: cijfers kunnen in lopende tekst, tabellen of grafieken voorkomen, en belangrijke getallen staan vaak verspreid over meerdere pagina’s. De auteurs verzamelen 1.735 van dergelijke rapporten voor een breed scala aan producten en zetten de PDF’s om naar ruwe tekst. Met aangepaste code en patroonherkenningsregels halen ze centrale feiten naar boven, zoals de totale koolstofvoetafdruk, het aandeel dat aan productie is toe te schrijven en het procentuele aandeel van elk groot onderdeel.
Computers leren carbon-vragen te beantwoorden
Het simpelweg opsommen van cijfers is niet genoeg; het doel is dat computerprogramma’s praktische vragen over emissies kunnen beantwoorden. Daartoe bouwen de onderzoekers een vraag‑antwoorddataset genaamd PCF‑QA. Voor elk product maken ze natuurlijke taalvragen zoals “Welk onderdeel heeft de grootste productieken-footprint?” of “Wat is de koolstofvoetafdruk van het beeldscherm in deze laptop?” en koppelen die aan correcte antwoorden die uit de opgeschoonde gegevens zijn afgeleid. De vragen vallen in vier categorieën: woord‑match (een getal direct uit de tekst halen), max/min (de grootste of kleinste bijdrager vinden), top‑k (de top drie of vijf onderdelen opsommen) en berekening (bijvoorbeeld de voetafdruk van een onderdeel berekenen aan de hand van percentages en totalen). Deze structuur laat moderne taalmodellen zowel leesbegrip als basisnumeriek redeneren oefenen.
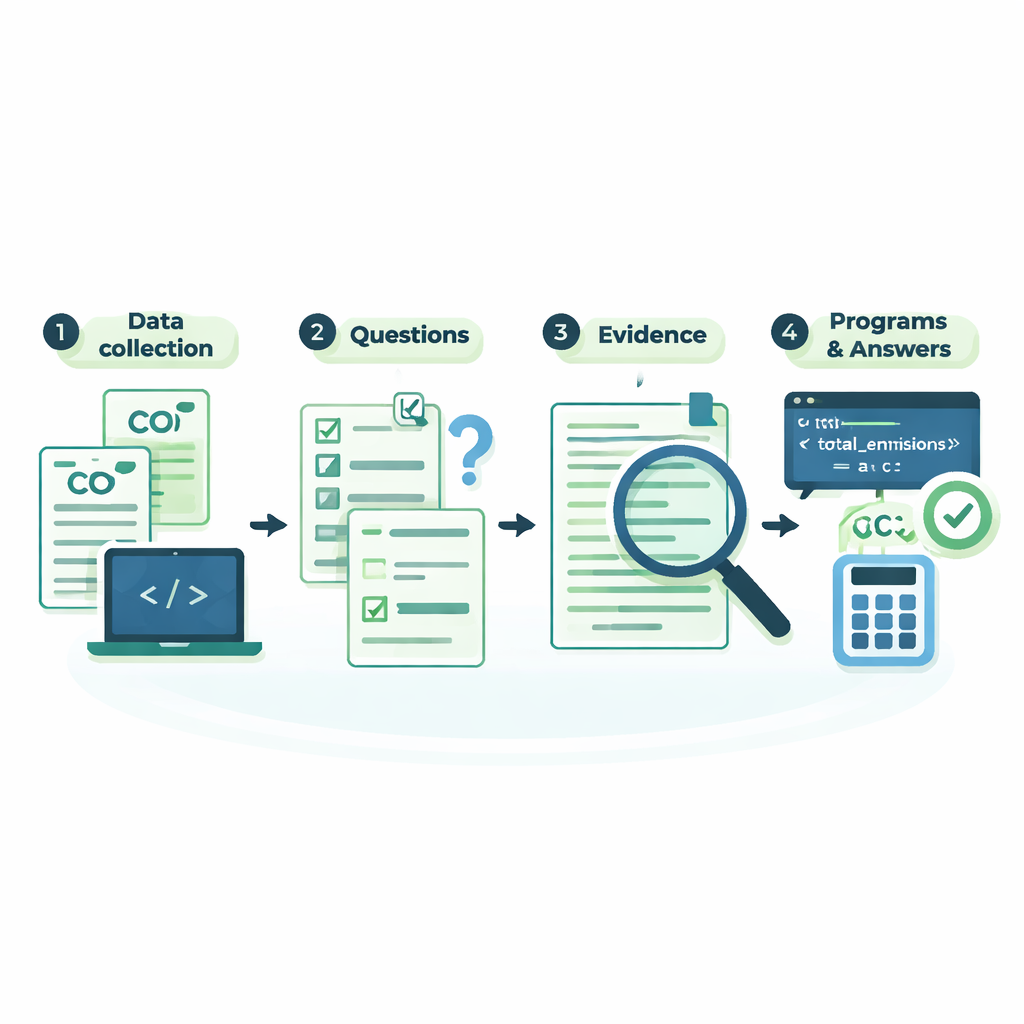
Hoe de nieuwe dataset is opgebouwd en gecontroleerd
Achter de schermen ontwerpen de auteurs een zorgvuldige workflow zodat de geëxtraheerde informatie betrouwbaar is. Na het downloaden van de PDF’s en het parseren naar tekst gebruiken ze reguliere expressies—precieze zoekpatronen—om componentnamen, percentages en totale voetafdrukken te lokaliseren, zelfs wanneer die verborgen zitten in grafieken. Verdachte gegevens, zoals producten waarvan de getallen niet optellen of sterk afwijken van het normale bereik voor een bedrijf, worden gemarkeerd en handmatig gecontroleerd tegen de originele bestanden. Voor elke vraag registreert de dataset tevens de exacte tekenposities van de ondersteunende tekst in het rapport, samen met een kort computerprogramma dat het antwoord stap voor stap herberekent. Het uitvoeren van deze kleine programma’s en het vergelijken van hun uitvoer met de opgeslagen antwoorden levert een extra validatielaag op.
Wat de cijfers over apparaten onthullen
Aangezien de dataset veel verschillende merken en producttypen volgt, biedt hij een eerste breed beeld van hoe de koolstofkost van elektronica is verdeeld. Zwaardere machines zoals workstations, desktops en servers hebben over het algemeen veel hogere voetafdrukken dan tablets, die kleiner zijn en minder onderdelen bevatten. Binnen een enkel apparaat domineren sommige componenten consequent: beeldschermen, hoofdprintplaten en voedingen zijn meestal verantwoordelijk voor de grootste delen van de productie-emissies, terwijl verpakking en batterijen relatief weinig bijdragen. De dataset vermeldt ook welke methode voor koolstofboekhouding elk bedrijf gebruikt, en benadrukt dat de meeste producten vertrouwen op één, deels ondoorzichtig model waarvan de aannames verouderd kunnen zijn—een belangrijke kanttekening bij het vergelijken van cijfers tussen merken.
Wat dit betekent voor toekomstig klimaatslimme technologie
Voor niet‑experts is de belangrijkste boodschap dat de klimaatimpact van elektronica nu op een meer systematische manier bestudeerd kan worden. Door ongestructureerde koolstofrapporten om te zetten in een gestandaardiseerde vraag‑antwoordbron, legt dit werk de basis voor tools die automatisch producten kunnen vergelijken, de vervuilendste onderdelen kunnen aanwijzen en “wat‑als”-scenario’s voor groenere ontwerpen kunnen verkennen. Naarmate fabrikanten hun rapportage uitbreiden naar andere milieuschade, zouden vergelijkbare methoden de samenleving kunnen helpen om concreet te zien hoe ontwerpkeuzes voor onze telefoons en computers zich vertalen naar druk op de planeet—en waar de grootste verbeterkansen liggen.
Bronvermelding: Zhao, K., Koyatan Chathoth, A., Balaji, B. et al. An electronic product carbon footprint dataset for question answering. Sci Data 13, 228 (2026). https://doi.org/10.1038/s41597-026-06544-5
Trefwoorden: koolstofvoetafdruk, elektronica, duurzaamheidsgegevens, levenscyclusanalyse, vraag-antwoord