Hoe de hersenen verborgen regels vinden in een rumoerige wereld
Dagelijks herkennen we moeiteloos patronen: een rood licht betekent stoppen, een drukke straat betekent langzamer rijden, een bepaalde houding betekent dat een huisdier op het punt staat te springen. Achter deze vaardigheden staat het vermogen van de hersenen om verborgen, of "latente", structuren in de wereld te ontdekken en ze in uiteenlopende taken opnieuw te gebruiken. Dit artikel stelt een schijnbaar eenvoudige vraag: wat maakt het ene patroon van populatiehersenactiviteit beter dan het andere om veel verwante taken snel en nauwkeurig op te lossen?
De verborgen knoppen achter neuronale codes Figuur 1.
De auteurs bestuderen hersenactiviteit op populatieniveau en beschouwen het vuren van veel neuronen als punten in een hoge-dimensionale ruimte. Ze concentreren zich op taken die een onderliggende set latente variabelen delen — bijvoorbeeld de vorm, grootte en positie van een object, of de locatie en snelheid van een dier. Een downstream-neuron of -circuit leest deze patronen uit met een eenvoudige lineaire regel, vergelijkbaar met het tekenen van een vlak door de wolk van punten om "categorie A" van "categorie B" te scheiden. In plaats van elke neuron in detail te simuleren, leiden de auteurs een analytische formule af die voorspelt hoe goed zo’n uitleesmechanisme zal generaliseren naar nieuwe voorbeelden, gegeven de geometrie van de neuronale activiteit. Opmerkelijk genoeg blijkt de prestatie bepaald te worden door slechts vier statistieken die vastleggen hoe sterk neuronen de latente variabelen weerspiegelen, hoe duidelijk verschillende variabelen gescheiden zijn, hoe ruis is georganiseerd en hoeveel effectieve dimensies de activiteit inneemt.
Vier eenvoudige ingrediënten van goede generalisatie
Het eerste ingrediënt is de algemene correlatie tussen individuele neuronen en de latente variabelen: wanneer kleine veranderingen in de verborgen variabelen duidelijke verschuivingen in neurale responsen veroorzaken, hebben downstream-uitlezers meer signaal om mee te werken. Het tweede en derde ingrediënt beschrijven "factorisatie": idealiter worden verschillende latente variabelen langs onafhankelijke richtingen gecodeerd, en drijft willekeurige ruis in richtingen die orthogonaal zijn aan deze signaalassen. Dit maakt het gemakkelijker voor een enkele lineaire grens om over veel taken te transfereren die allemaal afhangen van dezelfde verborgen structuur. Het vierde ingrediënt is effectieve dimensionaliteit, die vastlegt hoeveel richtingen in de activiteitsruimte de populatie daadwerkelijk gebruikt. Hogere dimensionaliteit heeft de neiging ruis over meer richtingen te verdunnen, wat de betrouwbaarheid verbetert, maar dit moet worden afgewogen tegen hoe duidelijk het signaal uitgelijnd is met gedragsrelevante variabelen.
De theorie testen in kunstmatige en biologische hersenen Figuur 2.
Om hun theorie te toetsen passen de auteurs die eerst toe op kunstmatige neurale netwerken. In meerlagige perceptrons getraind op veel verwante classificatieproblemen, en in een diep netwerk getraind om muis-lichaamsdelen in video’s te volgen, meten ze de vier geometrische grootheden op elke laag. De voorspelde fouten sluiten nauw aan bij de feitelijke prestaties van eenvoudige uitlezers die op die interne representaties zijn getraind. Daarna wenden ze zich tot echte hersengegevens. Opnames uit visuele gebieden van makaken laten zien dat, naarmate signalen van de ogen naar hogere visuele cortex bewegen, de geometrie zich ontwikkelt op een manier die de generalisatiefout vermindert: correlaties met latente variabelen nemen toe, storende variabiliteit wordt weggevoerd van signaalrichtingen en bepaalde vormen van dimensionaliteit worden herschikt. Bij ratten die een ruimtelijke alterneringstaak leren verbeteren zowel gedrag als uitleesprestaties over dagen training, terwijl de geometrie van hippocampale en prefrontale activiteit op systematische wijze verandert die de voorspellingen van de theorie weerspiegelen.
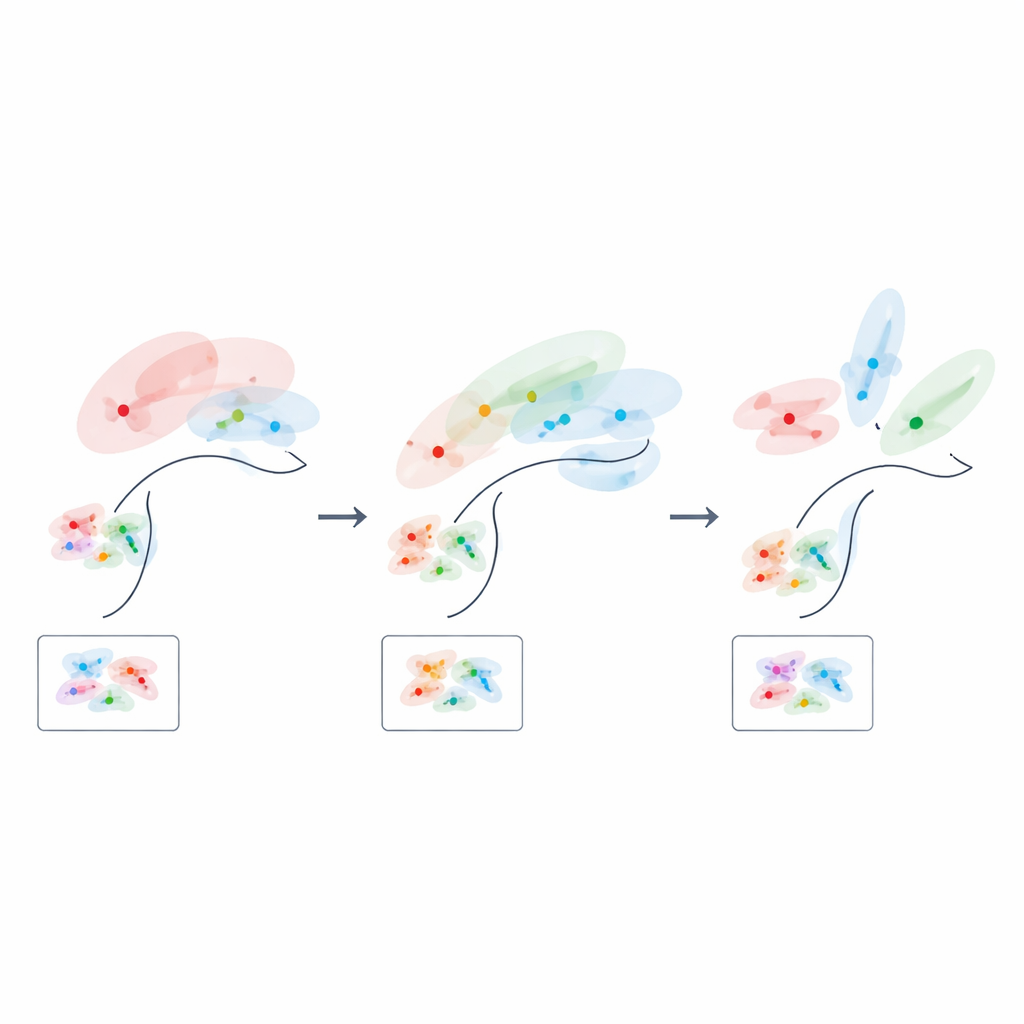
Hoe leren de neuronale ruimte herschrijft
Omdat hun formule geometrie direct aan prestatie koppelt, kunnen de auteurs vragen hoe een "optimale" neuronale code eruit zou moeten zien in verschillende stadia van leren. In het begin, wanneer slechts enkele trainingsvoorbeelden beschikbaar zijn, zijn de beste codes laag-dimensionaal en sterk uitgelijnd met de meest informatieve latente variabelen, waarbij minder nuttige kenmerken effectief worden gecomprimeerd. Naarmate ervaring zich ophoopt, verschuift de optimale oplossing: de representatie van taakrelevante structuur breidt zich uit naar meer dimensies, en de sterke correlatie tussen individuele neuronen en afzonderlijke variabelen ontspant zich zelfs. Met andere woorden, de hersenen lijken te beginnen met een gerichte, laag-dimensionale schets van de taak en vullen gaandeweg een rijkere, meer gedistribueerde kaart in naarmate ze leren.
Waarom dit belangrijk is voor het begrijpen van hersenen en machines
Voor een algemene lezer is de kernboodschap dat populatiehersenactiviteit niet zomaar een kluwen van spikes is; het heeft een vorm, en die vorm doet ertoe. Door vier meetbare geometrische kenmerken te identificeren die bepalen hoe goed eenvoudige uitlezers kunnen generaliseren over verwante taken, biedt dit werk een gemeenschappelijke taal om biologische en kunstmatige neurale netwerken te vergelijken. Het suggereert dat dieren en machines tijdens het leren hun interne activiteit herschikken van compacte, sterk uitgelijnde codes naar hoger-dimensionale, beter gefactoriseerde codes die toch taakrelevante informatie tegen ruis beschermen. Dit geometrische perspectief helpt verklaren hoe dezelfde hersencircuits flexibel verborgen structuur in veel situaties kunnen hergebruiken, en zo de ogenschijnlijk moeiteloze generalisatie ondersteunen die ten grondslag ligt aan alledaagse intelligentie.
Bronvermelding: Wakhloo, A.J., Slatton, W. & Chung, S. Neural population geometry and optimal coding of tasks with shared latent structure.
Nat Neurosci29, 682–692 (2026). https://doi.org/10.1038/s41593-025-02183-y
Trefwoorden: geometrie van neuronale populaties, codering van latente variabelen, multitask leren, gedesenteerde representaties, generalisatie in neurale netwerken