Clear Sky Science · nl
Betrouwbaarheid van LLM's als medische assistenten voor het algemene publiek: een gerandomiseerde vooraf geregistreerde studie
Waarom uw telefoon misschien niet de beste eerste dokter is
Steeds meer mensen wenden zich tot AI-chatbots voor hulp wanneer ze zich ziek voelen, in de hoop snel antwoord te krijgen op de vraag of ze zich zorgen moeten maken, wat hun klachten kunnen betekenen en of ze naar het ziekenhuis moeten. Deze studie stelt een eenvoudige maar dringende vraag: als gewone mensen krachtige taalmodellen thuis gebruiken als medische hulpen, nemen ze dan daadwerkelijk betere beslissingen over hun gezondheid — of kan de technologie een vals gevoel van zekerheid geven?
Het testen van slimme machines met realistische casussen
Om dat uit te zoeken ontwierpen onderzoekers in het Verenigd Koninkrijk tien realistische medische verhalen, zoals een plotselinge hevige hoofdpijn of ademhalingsproblemen, gebaseerd op veelvoorkomende aandoeningen die velen van ons kunnen treffen. Een team van ervaren artsen stemde in met de beste “volgende stap” voor elk verhaal — variërend van thuisblijven en zelfzorg tot het bellen van een ambulance — en noteerde de belangrijkste aandoeningen die een zorgvuldige persoon zou moeten overwegen. Vervolgens werden 1.298 volwassenen uit het hele VK willekeurig toegewezen aan een van vier opties: één van drie toonaangevende AI-chatbots gebruiken, of doen wat ze normaal thuis zouden doen, zoals webzoeken of vertrouwen op persoonlijke ervaring.
Hoe mensen en machines presteerden — afzonderlijk en samen
Toen de taalmodellen op zichzelf werden getest, door ze de volledige casusbeschrijvingen te geven en rechtstreeks te vragen naar een diagnose en aanbevolen actie, deden ze het indrukwekkend goed. Over de drie systemen heen suggereerden ze in ongeveer 95% van de gevallen ten minste één relevant medisch probleem en kozen ze in meer dan de helft van de gevallen het juiste urgentieniveau — veel beter dan toeval. Op papier leken deze systemen sterke kandidaten om bezorgde patiënten te adviseren.
Wanneer AI-advies echte mensen ontmoet
Maar zodra alledaagse gebruikers in beeld kwamen, veranderde het beeld. Deelnemers die AI gebruikten waren niet nauwkeuriger dan de controlegroep in het kiezen van de volgende stap, en ze waren daadwerkelijk slechter in het noemen van relevante onderliggende aandoeningen. Mensen in de niet-AI groep waren ongeveer 1,8 keer zo waarschijnlijk om een correcte aandoening te identificeren dan zij die chatbots gebruikten. De meeste deelnemers in alle groepen onderschatten hoe ernstig de situatie was. Met andere woorden: toegang tot een geavanceerd taalmodel hielp mensen niet om hun symptomen beter te begrijpen, en leidde niet duidelijk tot veiligere keuzes.
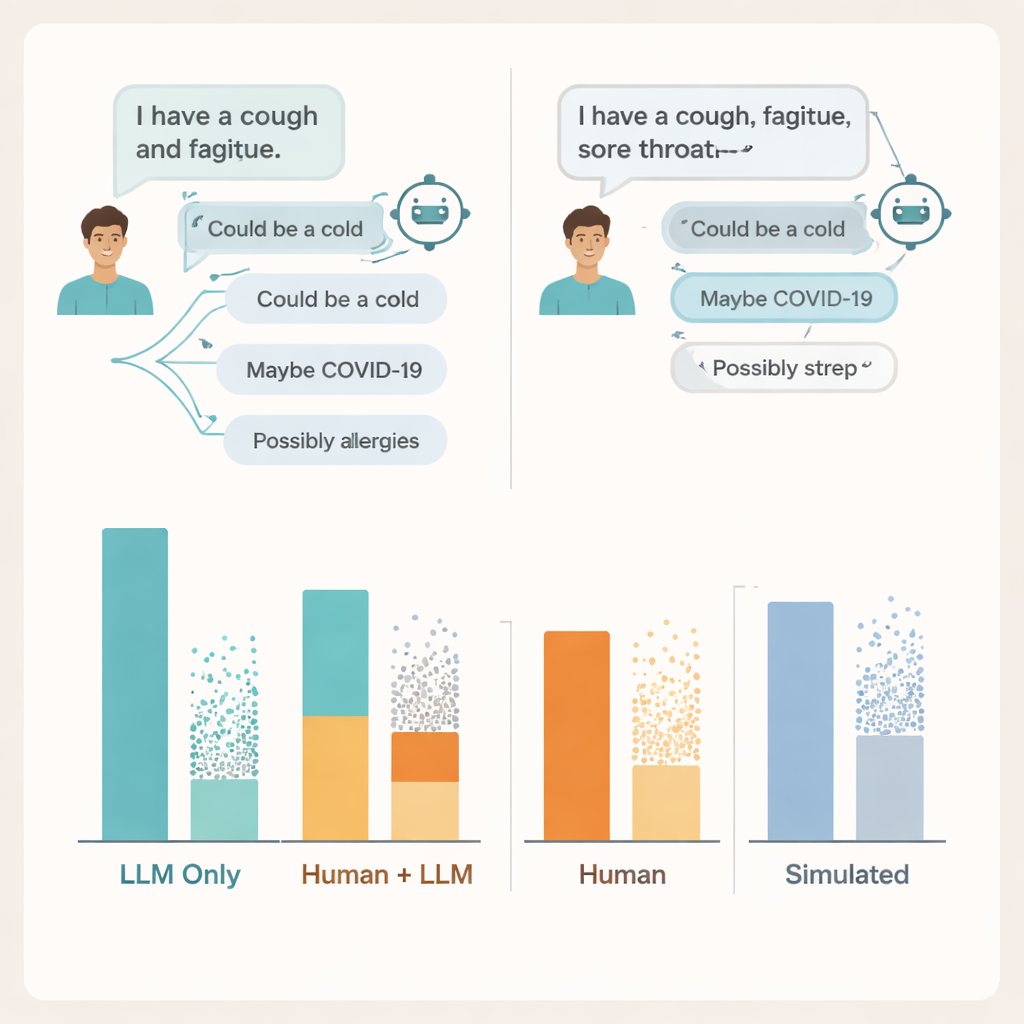
Waar het gesprek vastloopt
Om te begrijpen waarom doken de onderzoekers in de daadwerkelijke chattranscripten. Ze vonden problemen aan beide kanten van het gesprek. Veel gebruikers deelden niet genoeg details over hun klachten voor de AI om betrouwbaar advies te geven — vergelijkbaar met hoe patiënten soms sleutelgegevens weglaten tijdens een gesprek met een arts. De modellen noemden vaak ten minste één relevante aandoening, maar voegden ook meerdere onjuiste of afleidende mogelijkheden toe, en gebruikers hadden moeite om te beoordelen welke suggesties van belang waren. In sommige gevallen leidden vrijwel identieke symptoomomschrijvingen tot sterk uiteenlopend advies van hetzelfde model, waardoor het voor mensen moeilijk werd een duidelijk gevoel te krijgen wanneer ze wat op het scherm zagen konden vertrouwen.
Waarom standaardtests de echte risico's missen
Het team vergeleek deze resultaten ook met twee gangbare manieren om medische AI te beoordelen: meerkeuze-examenvragen en volledig gesimuleerde “patiënt”-gesprekken tussen twee modellen. Bij beide leken de systemen opnieuw sterk; ze bereikten of overtroffen typische slaagscores op examenachtige vragen en presteerden beter met gesimuleerde patiënten dan met echte. Toch kwamen hoge examscores en gepolijste gesimuleerde gesprekken niet overeen met hoe goed echte mensen het deden bij het gebruik van dezelfde hulpmiddelen. Benchmarks die kennis in isolatie testen, betogen de auteurs, missen de rommelige, fragiele aard van echte menselijke–AI-interacties.
Wat dit betekent voor patiënten en zorgsystemen
Voorlopig concluderen de onderzoekers dat huidige algemene taalmodellen niet klaar zijn om onbewaakt als eerstelijnsadviseurs voor het publiek te fungeren. Ze bevatten onmiskenbaar veel medische kennis, maar die kennis vertaalt zich niet automatisch in veiligere keuzes wanneer bezorgde mensen thuis gedeeltelijke, verwarde vragen intypen. AI echt nuttig maken in situaties met hoge risico's zoals de gezondheidszorg vereist meer dan betere examencijfers — het vraagt om zorgvuldig ontwerp, testen met diverse echte gebruikers en strengere controles op hoe informatie wordt verzameld, uitgelegd en vertrouwd in het wederzijdse gesprek.
Bronvermelding: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Trefwoorden: medische chatbots, zelfdiagnose, gezondheidszorg AI, patiëntbesluitvorming, grote taalmodellen