Clear Sky Science · nl
Wetenschappelijke literatuur synthetiseren met retrieval-augmented taalmodellen
Waarom het zo moeilijk is om bij te blijven in de wetenschap
Elk jaar verschijnen er miljoenen nieuwe wetenschappelijke artikelen online. Geen enkele onderzoeker kan ze allemaal lezen, terwijl belangrijke medische behandelingen, klimaatinzichten en technologische doorbraken mogelijk verborgen liggen in deze informatiestroom. Dit artikel onderzoekt of geavanceerde AI-systemen wetenschappers kunnen helpen die oceaan van studies te doorzoeken en samen te vatten in heldere, betrouwbare overzichten — zonder feiten te verzinnen.
Een nieuw soort onderzoeksassistent
De auteurs introduceren OpenScholar, een kunstmatig-intelligentiesysteem dat specifiek is gebouwd om wetenschappelijke literatuur te lezen en te synthetiseren. In tegenstelling tot algemene chatbots is OpenScholar nauw verbonden met een enorme open database van ongeveer 45 miljoen onderzoeksartikelen, de OpenScholar DataStore. Wanneer een wetenschapper een vraag stelt — bijvoorbeeld hoe je geleide nanodeeltjes kunt koelen of welke methoden het beste werken voor hersenbeeldvorming — zoekt het systeem eerst in deze database naar relevante passages en stelt het vervolgens een antwoord op met inline-citaties, vergelijkbaar met een door mensen geschreven overzichtsartikel. Dit proces wordt meerdere keren herhaald: het systeem bekritiseert en verfijnt zijn eigen concepten om duidelijkheid, volledigheid en citatiekwaliteit te verbeteren.
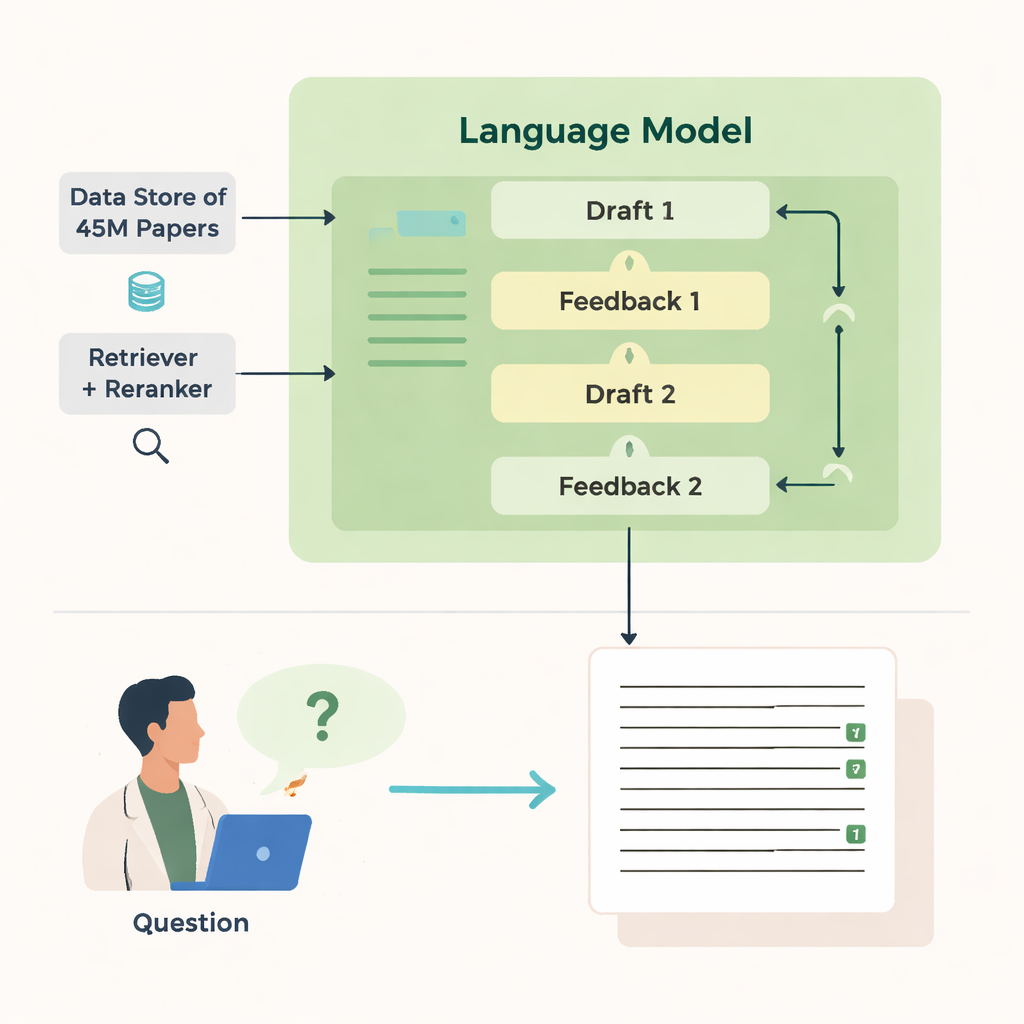
Hoe het zoekt en schrijft
De kracht van OpenScholar komt voort uit meerdere gecoördineerde onderdelen. Een "retriever"-module doorzoekt voorgerekende tekst-embeddings van miljoenen artikelen om veelbelovende fragmenten te vinden, terwijl een "reranker" deze fragmenten herschikt om zich te concentreren op de meest relevante. Het taalmodel gebruikt dit bewijsmateriaal vervolgens om een lang antwoord te formuleren met genummerde verwijzingen. Na het eerste concept genereert het model feedback aan zichzelf — aanwijzingen over ontbrekende perspectieven, zwakke structuur of dun bewijs — en activeert het indien nodig gerichtere zoekopdrachten. Daarna herschrijft het het antwoord, verweeft nieuwe artikelen en past citaties aan. Een laatste controle zorgt ervoor dat beweringen die ondersteuning vereisen, worden onderbouwd door ten minste één teruggevonden bron.
Claims en citaties op de proef stellen
Om te beoordelen of OpenScholar daadwerkelijk helpt, creëerden de auteurs ScholarQABench, een grote benchmark die is ontworpen om echte literatuuroverzichtsvragen na te bootsen. Deze bevat bijna 3.000 door experts geschreven vragen en honderden lange antwoorden uit computerwetenschappen, natuurkunde, neurowetenschappen en biomedische wetenschappen. Belangrijk is dat deze vragen meestal het lezen van meerdere artikelen vereisen, niet slechts één samenvatting. Het team evalueerde systemen langs meerdere dimensies: feitelijke juistheid, in hoeverre antwoorden de kernpunten besloegen, duidelijkheid van het schrijven en hoe nauwkeurig citaties de onderliggende artikelen weerspiegelden. Ze combineerden automatische controles met gedetailleerde beoordelingen door promovendi en andere deskundigen die AI-gegenereerde antwoorden vergeleken met door mensen geschreven versies.
Sterke chatbots verslaan en gelijkkomen met experts
Op deze benchmark presteerde OpenScholar beter dan zowel standaard taalmodellen als eerdere hulpmiddelen die eenvoudigweg retrieval toevoegden aan een algemene chatbot. Een compacte versie met acht miljard parameters, volledig getraind op open data, scoorde beter op een veeleisende synthese-opgave over meerdere artikelen dan GPT-4o en een concurrerend systeem genaamd PaperQA2, ondanks dat die op grotere propriëtaire modellen vertrouwden. Een opvallende bevinding was hoe vaak gewone chatbots hallucinaties vertoonden in referenties: in 78–90 procent van de gevallen bevatte hun citatielijst artikelen die niet bestonden of de beweringen niet ondersteunden. Ter vergelijking: de citatie-nauwkeurigheid van OpenScholar kwam dicht in de buurt van die van menselijke experts. Toen experts antwoorden rechtstreeks vergeleken, gaven ze ongeveer de helft van de tijd de voorkeur aan OpenScholar-8B boven door experts geschreven antwoorden, en ongeveer zeventig procent van de tijd aan een OpenScholar-pijplijn gebouwd op GPT-4o, grotendeels omdat de AI meer relevante studies behandelde en ze duidelijk organiseerde.
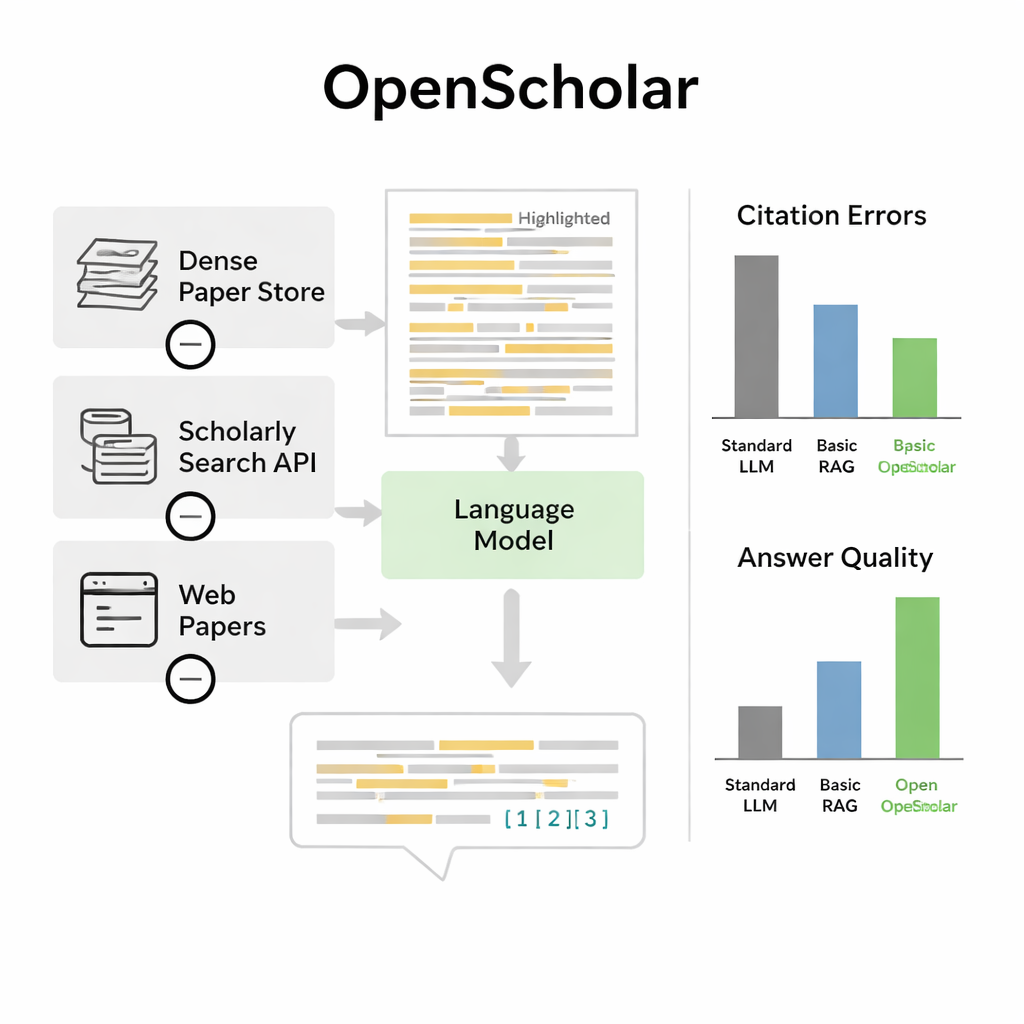
Beperkingen en toekomstige verbeteringen
Ondanks deze vooruitgang benadrukken de auteurs dat OpenScholar geen vervanging is voor wetenschappers. Het systeem kan nog steeds de meest representatieve artikelen missen, minder belangrijk werk te veel accentueren of feitelijke onjuistheden introduceren, vooral in compactere modellen. De benchmark zelf heeft ook beperkingen: deze richt zich voornamelijk op computerwetenschappen, biomedische wetenschappen en natuurkunde, en de zorgvuldig geannoteerde vragen zijn nog relatief weinig omdat de tijd van experts duur is. Evaluaties slagen er ook moeilijk in om subtielere kwaliteiten volledig vast te leggen, zoals of citaties werkelijk baanbrekend werk benadrukken of of een antwoord daadwerkelijk een nieuw experiment zou kunnen sturen.
Wat dit betekent voor alledaagse wetenschap
Voor niet-specialisten is de belangrijkste conclusie dat zorgvuldig ontworpen AI-hulpmiddelen wetenschappers al kunnen helpen de wetenschappelijke literatuur effectiever te doorzoeken, mits ze verbonden zijn met echte data en worden gehouden aan strikte standaarden voor bewijs en transparantie. OpenScholar laat zien dat wanneer een AI-systeem van de grond af wordt opgebouwd om echte artikelen op te halen, te controleren en te citeren — en wanneer de prestaties worden getest tegenover menselijke experts — het literatuursamenvattingen kan produceren die niet alleen leesbaar maar ook verifieerbaar zijn. In de praktijk zouden zulke tools onderzoekers kunnen vrijmaken om zich meer te richten op het ontwerpen van experimenten en het interpreteren van resultaten, terwijl mensen de uiteindelijke beoordeling van wat waar en belangrijk is behouden.
Bronvermelding: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Trefwoorden: literatuuroverzicht van wetenschappelijke publicaties, retrieval-augmented taalmodellen, OpenScholar, nauwkeurigheid van citaties, AI-onderzoekstools