Clear Sky Science · nl
Taalmodel-gestuurde voorspelling en ontdekking van zoogdiermetabolieten
Verborgen chemie in ons lichaam
Elke druppel bloed of urine bevat duizenden kleine moleculen die weerspiegelen wat we eten, hoe we leven en of we ziek worden. Voor de meeste van deze moleculen kennen wetenschappers echter niet hun namen of functies. Dit artikel introduceert DeepMet, een kunstmatig-intelligentiesysteem dat de “taal” van deze moleculen leest en voorspelt welke er ontbreken in onze huidige kaarten van menselijke en dierlijke chemie. Door experimenten te richten op de meest veelbelovende kandidaten helpt DeepMet onderzoekers deze chemische donkere materie te ontdekken en beter te begrijpen hoe onze lichamen werken.
Waarom zoveel moleculen onbekend blijven
Moderne instrumenten kunnen duizenden moleculen in een weefselmonster tegelijk wegen en gedeeltelijk karakteriseren. Maar van deze vingerafdrukken naar exacte structuren gaan is lastig. Bestaande databanken vermelden veel bekende metabolieten, toch komen de meeste signalen in echte monsters niet overeen met iets in die catalogi. Dit gat suggereert dat de huidige kaarten van de stofwisseling onvolledig zijn en dat veel natuurlijke moleculen in zoogdieren nooit zijn beschreven. De auteurs wilden een hulpmiddel bouwen dat van bekende metabolieten leert en vervolgens de meest plausibele ontbrekende moleculen kan bedenken, op vergelijkbare wijze als taalmodellen waarschijnlijk woorden in een zin voorspellen.
Een machine de grammatica van de stofwisseling leren
Het team trainde een neuraal netwerk genaamd DeepMet op ongeveer 2.000 goed vastgestelde menselijke metabolieten, elk gecodeerd als een korte tekenreeks die de structuur beschrijft. Na een eerste training op geneesmiddelachtige moleculen om algemene chemische regels te leren, werd DeepMet fijn afgesteld op deze set metabolieten. Toen men het model vroeg nieuwe structuren te genereren, produceerde het moleculen die hetzelfde chemische gebied bezetten als echte metabolieten en zelfs veel bekende typen enzymreacties reproduceerden, ondanks dat die regels nooit expliciet werden opgelegd. Met andere woorden leek DeepMet de ongeschreven grammatica te internaliseren die basisbouwstenen zoals suikers en aminozuren verbindt tot biologisch realistische kleine moleculen.
Voorspellen welke nieuwe moleculen waarschijnlijk bestaan
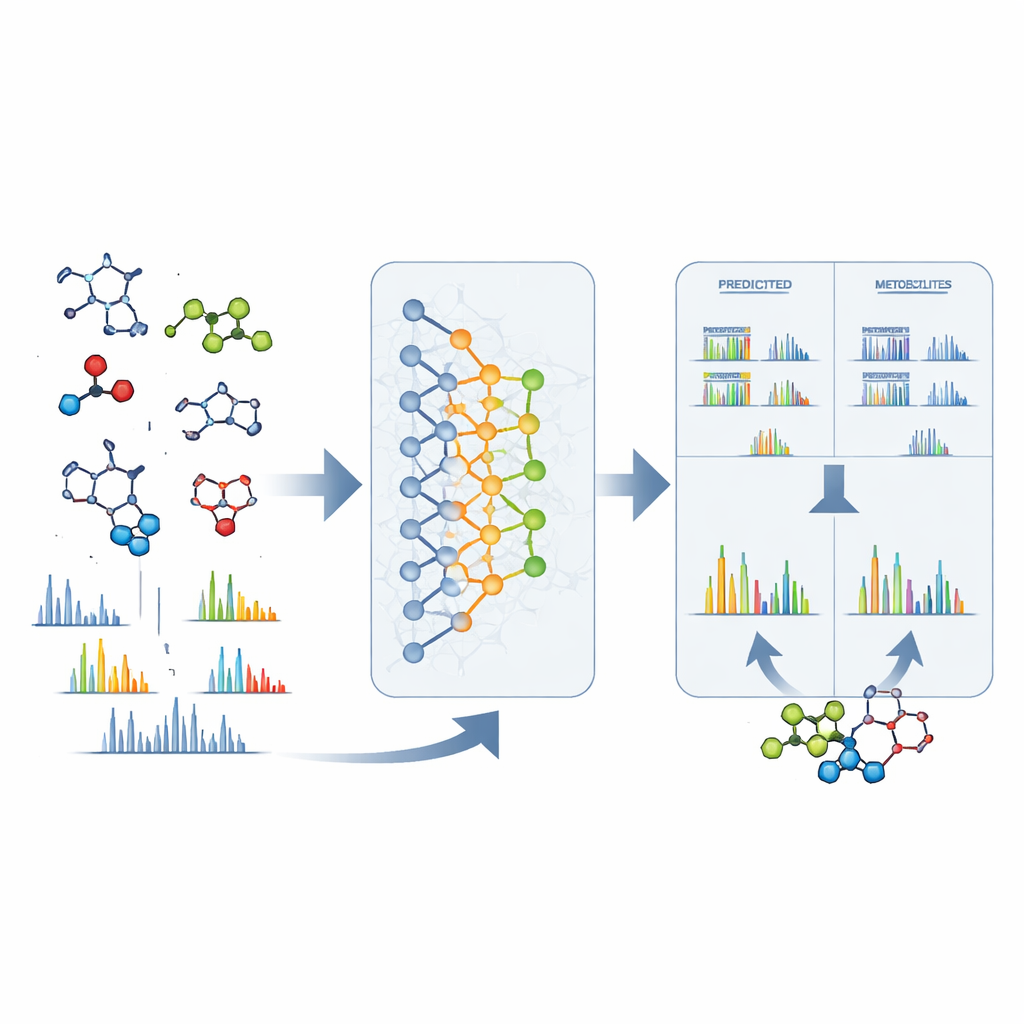
De onderzoekers hebben vervolgens één miljard kandidaat-moleculen uit DeepMet gesampled en geteld hoe vaak elke unieke structuur verscheen. Vaak herhaalde structuren leken meer op bekende metabolieten, deelden gemeenschappelijke chemische kernen met hen en kwamen overeen met plausibele enzymtransformaties. Om te testen of deze hoogfrequente kandidaten overeenkomen met echte moleculen vergeleek het team DeepMets voorspellingen met metabolieten die na het afsluiten van de trainingsdata aan de Human Metabolome Database werden toegevoegd. DeepMet had het merendeel van deze latere ontdekkingen al gegenereerd en plaatste vele daarvan hoog in zijn ranglijst. Van de duizenden hoog gerangschikte structuren die ontbraken in databases, kochten of synthetiseerden de auteurs 80 en controleerden echte menselijke monsters met massaspectrometrie. Ze bevestigden de aanwezigheid van verschillende eerder niet-herkende metabolieten, waarvan sommige waren over het hoofd gezien hoewel ze in bestaande literatuur verschijnen.
Van ruwe signalen naar concrete structuren
DeepMet is ook nuttig zodra een onbekende piek in een massaspectrometer is gezien. Alleen gegeven de exacte massa van een mysterieus molecuul kan het model veel structuren opsommen die hetzelfde zouden wegen en deze rangschikken op hoe metaboliet-achtig ze lijken. In bijna een derde van de testgevallen stond de correcte structuur bovenaan; in veel meer gevallen verscheen deze tussen slechts een handvol hoog gerangschikte kandidaten en was meestal erg vergelijkbaar qua vorm met de favoriet van het model. Om verder te verfijnen combineerden de auteurs DeepMet met aparte software die voorspelt hoe elke kandidaat zou uiteenvallen in een massaspectrometer. Het matchen van deze voorspelde patronen met echte experimentele spectra verdubbelde de identificatienauwkeurigheid ruwweg. Het doorzoeken van grote openbare datasets met deze gecombineerde aanpak leverde voorlopige structuren op voor veel eerder anonieme signalen en wees op metabolieten die verschillen tussen ziekten, diëten en microbiomestatussen.
Het verlichten van de chemische donkere materie van het leven
Door chemische intuïtie geleerd uit data te combineren met krachtige patroonherkenning aan massaspectra biedt DeepMet een stappenplan om nieuwe metabolieten op een gerichte, praktische manier te ontdekken. Het kan nog niet elk onbekend molecuul onthullen—sommige structuren liggen te ver van wat het heeft gezien en bepaalde isomeren blijven ononderscheidbaar zonder gespecialiseerde methoden. Maar de studie toont aan dat tools in de trant van taalmodellen niet alleen realistische moleculen kunnen verzinnen, maar ook reële verbindingen kunnen voorspellen die biologen later in dieren en mensen bevestigen. Voor de leek is de conclusie dat AI chemici nu kan helpen systematisch verborgen chemie in ons lichaam te onthullen, mogelijk nieuwe biomarkers te vinden, dieet–microbe–gastheer-verbindingen te traceren en geleidelijk de metabole donkere materie van vandaag om te vormen tot de goed in kaart gebrachte biologie van morgen.
Bronvermelding: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Trefwoorden: metabolomics, chemische taalmodellen, DeepMet, massaspectrometrie, metabole donkere materie