Clear Sky Science · nl
Ontsluiting van sleutelpieken voor de authenticatie van olijfolie met Raman-spectroscopie en chemometrie
Waarom het verhaal van olijfoliefraude ertoe doet
Als u extra betaalt voor een fles olijfolie, verwacht u het echte product, niet een mengsel dat stilletjes is aangemaakt met goedkopere zaadoliën. Omdat olijfolie waardevol is en de wereldhandel ingewikkeld, komen fraude en verkeerde etikettering vaak voor. Deze studie presenteert een snelle, niet-destructieve methode om dergelijke trucs te herkennen door laserlicht op oliën te richten en slimme computerprogramma’s de verborgen chemische vingerafdrukken te laten lezen. De aanpak wil consumenten, eerlijke producenten en toezichthouders beschermen door het eenvoudiger te maken te controleren of wat in de fles zit overeenkomt met wat er op het etiket staat.
Met licht de oliefingerafdrukken lezen
De onderzoekers gebruikten een techniek genaamd Raman-spectroscopie, waarbij een gefocusseerde lichtbundel op een monster wordt gericht en wordt gemeten hoe het licht verstrooit terugkomt. Verschillende moleculen trillen op hun eigen manier en laten een patroon van pieken in het resulterende spectrum achter, vergelijkbaar met een streepjescode. Olijfolie en veelvoorkomende vervalsingsoliën zoals zonnebloem-, koolzaad- en maïsolie hebben verschillende mengsels van vetzuren en natuurlijke pigmenten, waardoor hun spectra niet identiek zijn. Door deze patronen te bestuderen in pure oliën en zorgvuldig bereide mengsels, kon het team een kleine set "sleutelpieken" identificeren waarvan de vorm en sterkte betrouwbaar veranderden naarmate er meer of minder olijfolie in een mengsel aanwezig was.
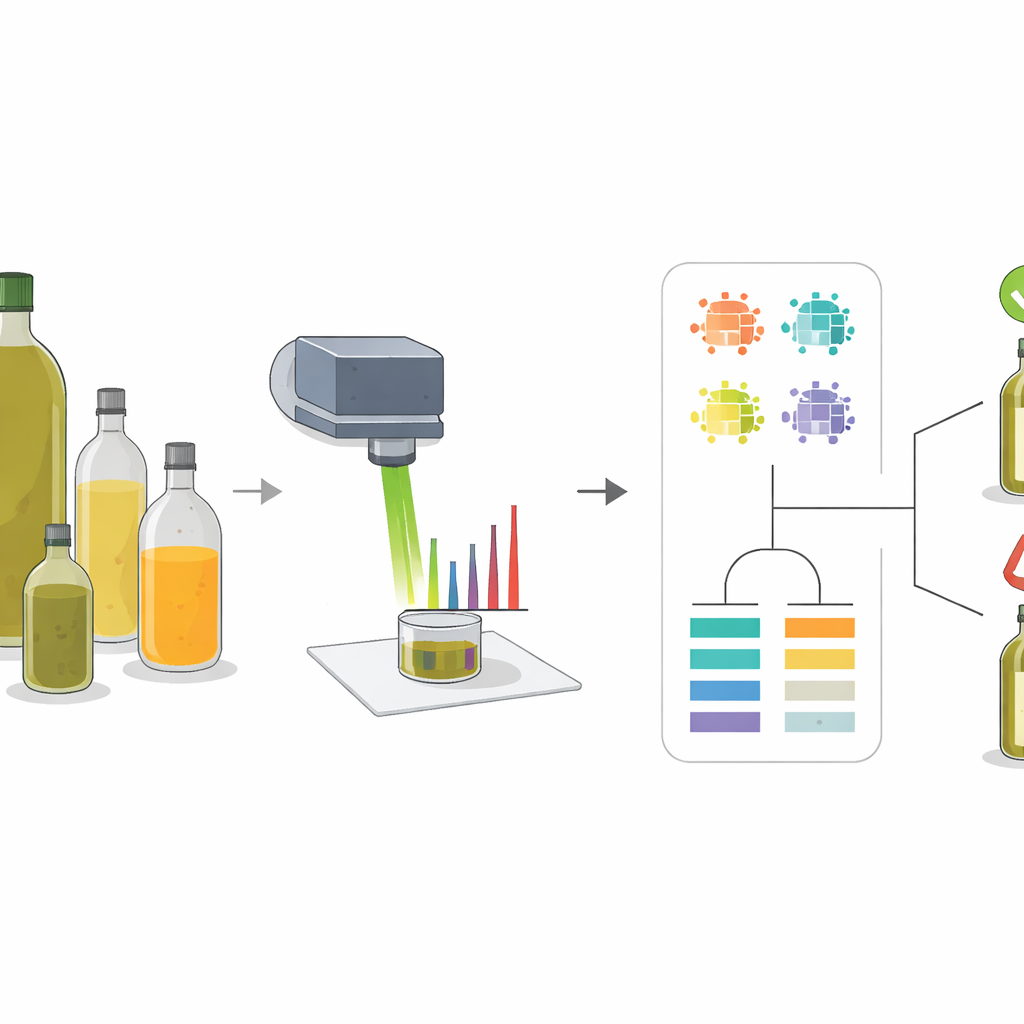
De meest veelzeggende signalen vinden
In plaats van te vertrouwen op één enkele meting, haalden de onderzoekers meerdere beschrijvende kenmerken uit elke belangrijke piek: hoe hoog die was (intensiteit), hoeveel gebied hij besloeg, hoe breed hij was op halve hoogte, en hoe zijn gebied zich verhoudde tot andere pieken. Vervolgens gebruikten ze clusteranalyse en correlatiekaarten om te zien hoe deze kenmerken verschillende oliën groepeerden en hoe ze verschoof wanneer het olijfgehalte toenam. Piekjes die gekoppeld waren aan kleurstoffen zoals bèta-caroteen en aan bepaalde typen onverzadigde vetten bleken bijzonder informatief. Zo werden sommige pieken sterker naarmate het aandeel olijfolie steeg, terwijl andere vervaagden omdat ze samenhingen met linolzuur, dat in zonnebloemolie vaker voorkomt. Dit multi-kenmerkenperspectief ving subtiele verschillen op die verloren zouden gaan bij gebruik van slechts één intensiteitswaarde.
Algoritmen laten bepalen wat eerlijk is en wat vervalst
Om deze spectrale vingerafdrukken om te zetten in praktische beslissingen, trainden de auteurs meerdere machine learning-modellen. Eerst lieten ze de modellen tien oliesoorten classificeren, waaronder vier pure oliën en zes soorten binaire en tertiaire mengsels. Boomgebaseerde methoden—random forests en gradient-boosted trees—presteerden het beste en wezen bijna alle monsters correct toe aan de juiste categorie wanneer ze de volledige set piekkenkenmerken kregen. Vervolgens werden dezelfde modeltypen gebruikt voor numerieke voorspelling: het schatten van het werkelijke percentage olijfolie in mengsels van twee of drie oliën. Ook hier presteerden de boomgebaseerde benaderingen beter dan meer traditionele methoden en volgden ze het olijfgehalte nauwkeurig, zelfs wanneer signalen van verschillende oliën sterk in het spectrum overlappen.
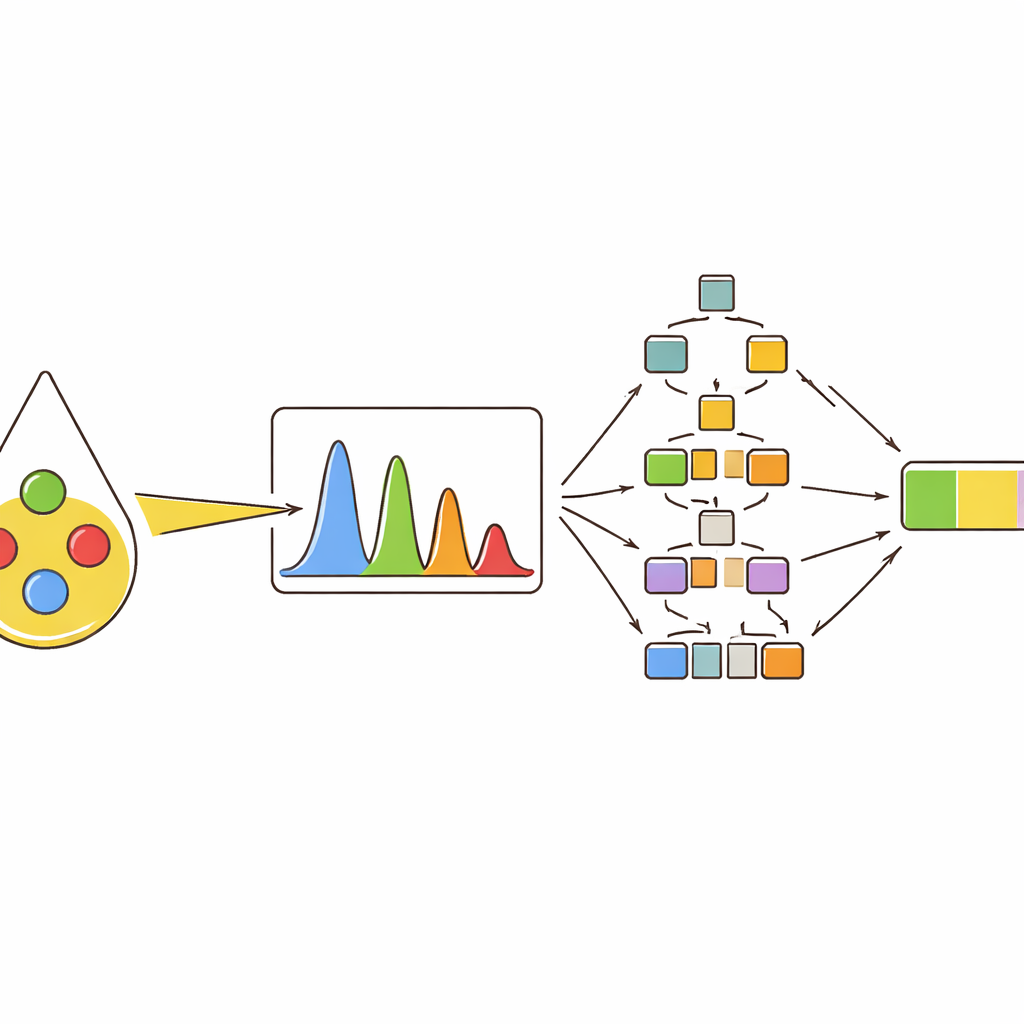
Het zwarte doos-probleem van slimme modellen openen
Veel krachtige machine learning-instrumenten zijn moeilijk te interpreteren; ze werken mogelijk goed maar geven weinig inzicht waarom ze een bepaalde beslissing namen. Om dit aan te pakken gebruikte de studie een verklaringsmethode die elke invoerkenmerk een bijdrage aan de uiteindelijke voorspelling toekent. Dit toonde aan dat een paar specifieke pieken de beslissingen van de modellen domineerden en consequent de voorspelde olijfinhoud omhoog of omlaag duwden afhankelijk van hun waarden. Dezelfde pieken bleven als belangrijkste naar voren komen over verschillende mengseltypes en in tests met commerciële supermarktoliën, die slechts een kleine hoeveelheid olijfolie bevatten. Voor deze monsters uit de praktijk schatten de beste modellen het olijfgehalte zeer dicht bij de werkelijke waarde, wat zowel de nauwkeurigheid als de transparantie van de aanpak ondersteunt.
Wat dit betekent voor uw fles thuis
Simpel gezegd laat het werk zien dat een snelle lichtscan, geïnterpreteerd door goed ontworpen en uitlegbare computermodellen, kan bepalen of een "olijfolie" puur is, sterk verdund, of ergens daartussenin. Door zich te concentreren op een handvol robuuste spectrale kenmerken en deze te combineren in geavanceerde maar interpreteerbare algoritmen, bouwden de onderzoekers een hulpmiddel dat in routinematige kwaliteitscontroles geïntegreerd zou kunnen worden, mogelijk zelfs in draagbare apparaten. Hoewel breder testen op meer regio’s, variëteiten en soorten fraude nog nodig is, wijst dit raamwerk op een toekomst waarin het verifiëren van de eerlijkheid van hoogwaardig voedsel zoals olijfolie sneller, makkelijker en betrouwbaarder wordt voor iedereen.
Bronvermelding: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Trefwoorden: authenticatie van olijfolie, detectie van voedselfraude, Raman-spectroscopie, machine learning, kwaliteit van eetbare olie