Clear Sky Science · nl
Machine learning onthult drie lagen van voedselcomplexiteit
Waarom slimmer voedsel ertoe doet
Elke hap voedsel verbergt een wereld van complexiteit: duizenden onzichtbare moleculen, ingewikkelde interacties tussen ingrediënten en de unieke manier waarop ieders hersenen reageren op smaak en geur. Dit artikel legt uit hoe moderne machine-learning wetenschappers helpt die complexiteit te doorgronden. Door chemische analyses, fabriekssensoren en zelfs hersenscans met elkaar te verbinden, hopen onderzoekers smakelijkere, gezondere en betrouwbaardere voeding te ontwerpen—en beter af te stemmen op wat verschillende mensen daadwerkelijk prettig vinden.
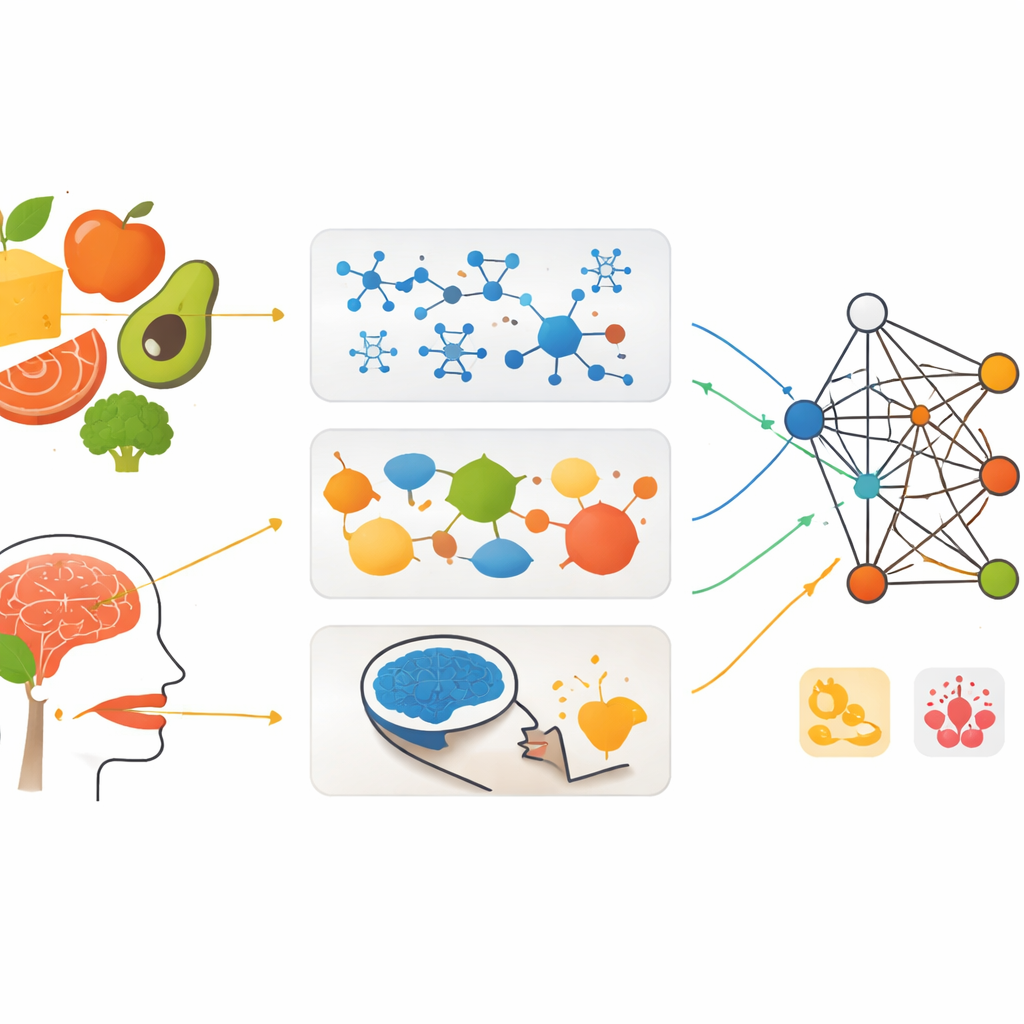
Inzicht in de verborgen bouwstenen van voedsel
Op het meest fundamentele niveau bestaan voedingsmiddelen uit tienduizenden verschillende chemicaliën. Veel daarvan zijn kleine aroma- en smaakmoleculen; anderen beïnvloeden voedingswaarde, veiligheid of houdbaarheid. Slechts een fractie van deze stoffen is grondig bestudeerd, waardoor wetenschappers vaak niet weten welke stoffen een bepaalde smaak of gezondheidseffect veroorzaken. Machine learning helpt deze leemten te vullen door patronen te vinden tussen de structuur van een molecuul en zijn gedrag. Algoritmen kunnen worden getraind op bekende gegevens om te voorspellen of nieuwe moleculen waarschijnlijk zoet of bitter smaken, fruitig of rokerig ruiken, of op een nuttige of schadelijke manier met menselijke receptoren interageren. Deep-learningmodellen die moleculen als netwerken van atomen behandelen, zijn bijzonder krachtig en onthullen structuur–smaakverbindingen die met de hand moeilijk te ontdekken zouden zijn.
Hoe ingrediënten samenwerken
Voedsel gedraagt zich zelden als een eenvoudige optelsom van zijn onderdelen. Suikers, zuren, vetten en aroma’s kunnen elkaar versterken of dempen en zo textuur, vrijkomen van geurstoffen en smaakbalans veranderen. Om deze interacties te bestuderen verzamelen onderzoekers gedetailleerde “vingerafdrukken” van voedingsmiddelen met instrumenten zoals gas- en vloeistofchromatografie of ion-mobiliteitsspectrometrie, die complexe mengsels van chemicaliën scheiden en detecteren. Elektronische neuzen en tongen gaan een stap verder door met sensornetwerken het totale geur- of smaakpatroon van een monster vast te leggen. Door deze rijke signalen aan machine-learningmodellen te voeren, kunnen onderzoekers productkwaliteit classificeren, bederf of fraude opsporen en smaakprofielen sneller en objectiever inschatten dan met traditionele proefpanels. Data-fusie methoden combineren vervolgens meerdere bronnen—chemische vingerafdrukken, sensorsignalen, kleurbeelden en basiscompositie—tot geïntegreerde modellen die beter vastleggen hoe ingrediënten samenwerken.
Hoe onze hersenen smaak ervaren
De reis van voedsel eindigt niet op de tong; ze zet zich voort in de hersenen. Mensen verschillen sterk in hoe ze hetzelfde voedsel ervaren door genetica, cultuur en eerdere ervaringen. Nieuwe hersenbeeldvormingstools, zoals elektro-encefalografie (EEG), functionele near-infrared spectroscopie en functionele MRI, kunnen volgen hoe verschillende hersengebieden reageren wanneer mensen proeven of ruiken. Machine-learningmodellen die op deze signalen worden getraind, kunnen onderscheid maken tussen basissmaken zoals zoet, zuur of umami, specifieke geuren herkennen en zelfs inschatten hoe aangenaam iemand een geur vindt. Door snelle methoden zoals EEG te combineren met beeldvorming die laat zien waar in de hersenen activiteit plaatsvindt, bouwen onderzoekers aan rijkere, geïndividualiseerde kaarten van smaakperceptie.
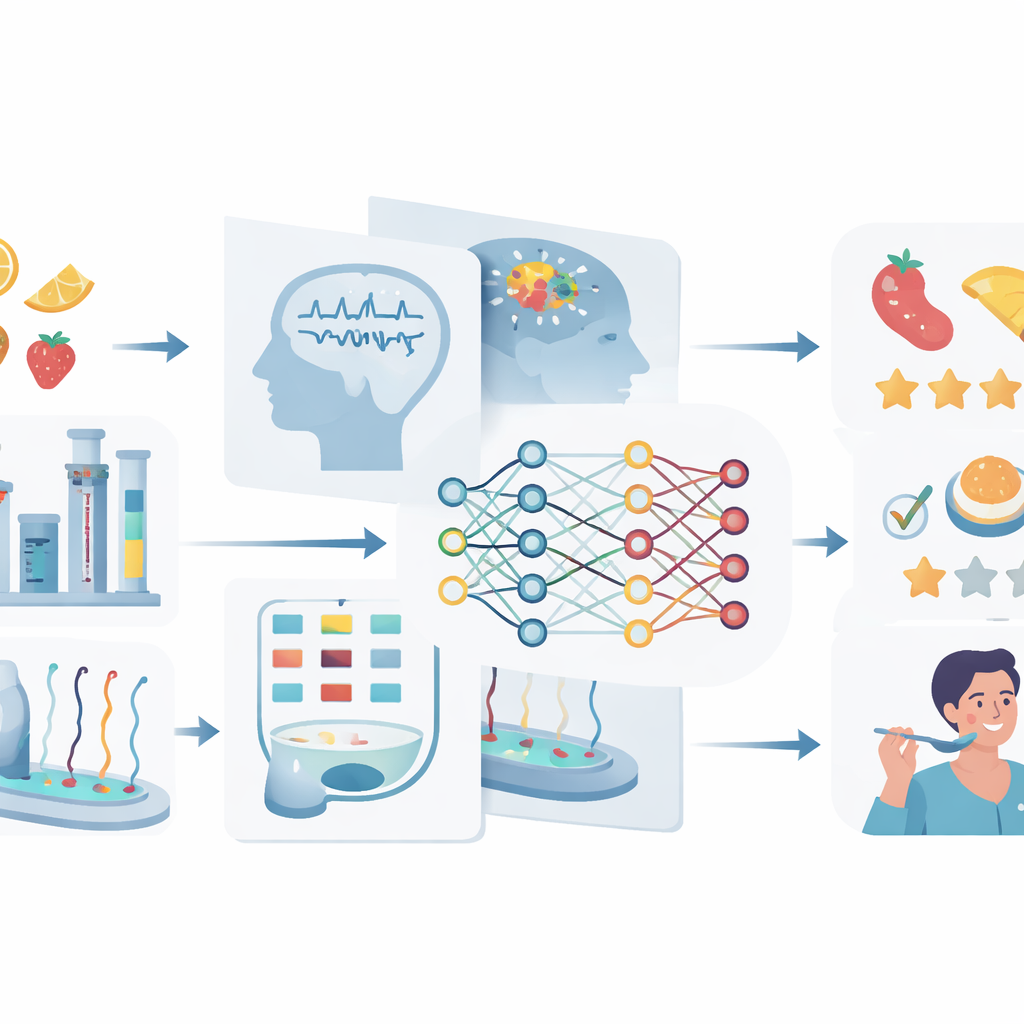
Verschillende datastromen samenbrengen
Aangezien geen enkele methode ieder aspect van voedsel kan vastleggen, benadrukt het artikel het belang van het samenvoegen van vele soorten gegevens. Aan de ene kant staan moleculaire databases die voedingsstoffen, additieven en aroma‑verbindingen vermelden. In het midden bevinden zich metingen van complete voedingsmiddelen met laboratoriuminstrumenten en slimme sensoren. Aan de andere kant staan mensgerichte gegevens zoals proefnotities, consumentbeoordelingen en hersensignalen. Data-fusiestrategieën voegen deze onderdelen op verschillende momenten samen: rauwe signalen kunnen vroeg worden samengevoegd, geëxtraheerde kenmerken kunnen midden in de pijplijn gecombineerd worden, of aparte modellen kunnen op beslissingsniveau worden gemengd. Wanneer dergelijke multimodale datasets zorgvuldig worden opgeschoond, gestandaardiseerd en gedeeld onder gemeenschappelijke regels, kunnen machine-learningsystemen beter koppelen wat er in het voedsel zit, hoe het verwerkt wordt en hoe het uiteindelijk aanvoelt om te eten.
Wat dit betekent voor toekomstige maaltijden
De auteurs concluderen dat machine learning een nieuw gereedschapskist biedt om voedsel te begrijpen van molecuul tot geest. Simpel gezegd kan het wetenschappers helpen voorspellen welke combinaties van ingrediënten smakelijk, veilig en stabiel zullen zijn voordat er maanden in de keuken of pilotinstallatie worden besteed. Het kan ook objectieve metingen van instrumenten en sensoren koppelen aan de subjectieve ervaringen van diverse eters, en zo leiden tot meer inclusieve en gepersonaliseerde voedselontwerpen. Om deze visie te verwezenlijken heeft het vakgebied grotere en beter georganiseerde databases, beter interpreteerbare modellen en nauwere samenwerking tussen levensmiddelentechnologen, chemici, datawetenschappers en neurowetenschappers nodig. Als deze doelen worden bereikt, kunnen de voedingsmiddelen van morgen sneller worden ontwikkeld, nauwer op individuele voorkeuren en gezondheid worden afgestemd en betrouwbaarder worden beoordeeld dan ooit tevoren.
Bronvermelding: Ke, Q., Zhang, J., Huang, X. et al. Machine learning unveils three layers of food complexity. npj Sci Food 10, 87 (2026). https://doi.org/10.1038/s41538-026-00730-w
Trefwoorden: machine learning in levensmiddelentechnologie, voedsel smaak voorspelling, elektrische neus en tong, hersenreacties op smaak, multimodale voedselgegevens