Clear Sky Science · nl
Tekstmining-ondersteunde machine learning-voorspelling en experimentele validatie van emissiegolflengten
Wetenschappelijke tekst omzetten in licht
Elk jaar publiceren wetenschappers tienduizenden artikelen over materialen die gloeien — stoffen die worden gebruikt in telefoonschermen, medische scanners en stralingsdetectoren. In die publicaties staan metingen van precies welke kleuren verschillende materialen uitstralen, maar die informatie is verspreid, inconsistent geformuleerd en moeilijk voor computers te gebruiken. Deze studie laat zien hoe je die literatuur automatisch kunt uitlezen, kunt omzetten in een grote, betrouwbare dataset, en vervolgens machine learning kunt gebruiken om de kleur van licht te voorspellen die nieuwe materialen zullen uitzenden — waarmee onderzoekers veel sneller betere fosforen kunnen ontwerpen.
Waarom lichtgevende materialen belangrijk zijn
Fosforen zijn materialen die energie absorberen en heruitzenden als zichtbaar licht. Ze vormen de kern van technologieën zoals ultra-hoge-resolutie beeldschermen, witte LED's, medische beeldvorming en stralingsdetectie. Ingenieurs streven naar fosforen die in zeer specifieke kleuren schijnen, helder blijven bij hoge temperaturen en zo min mogelijk energie verspillen. In de afgelopen twee decennia is het onderzoek naar deze materialen explosief gegroeid, waardoor het wetenschappelijke archief is gevuld met gedetailleerde rapporten over chemische recepten en emissiegolflengten. Toch staan deze gegevens grotendeels opgesloten in ongestructureerde tekst — zinnen in paragrafen, bijschriften en experimentele secties die voor mensen zijn geschreven, niet voor computers. 
Computers leren materialenartikelen lezen
De auteurs bouwden een gespecialiseerde tekstmining-pijplijn die is afgestemd op de fosforliteratuur. In plaats van generieke taalgereedschappen te gebruiken, maakten ze regels die begrijpen hoe chemici formules daadwerkelijk schrijven, vooral voor “gedopeerde” materialen waarbij een kleine hoeveelheid van een element aan een gastheer wordt toegevoegd. Hun systeem kan complexe namen correct herkennen, zoals een hostrooster gevolgd door meerdere dope-ioniën en hun concentraties, en die namen koppelen aan nabijgelegen cijfers die emissiegolflengten voorstellen. Het pakt ook lastige formuleringen aan, zoals zinnen die zeggen “het straalt bij 630 nm” zonder de materiaalnaam te herhalen, of paragrafen waarin meerdere materialen en meerdere golflengten samen worden genoemd. Door elke zin te classificeren op basis van hoeveel materialen en eigenschappen deze bevat, en vervolgens een overeenkomstig algoritme te kiezen voor die situatie, vermindert de pijplijn sterk de verwisselingen tussen welk getal bij welk materiaal hoort.
Een zuivere kaart van samenstelling naar kleur bouwen
Met deze pijplijn toegepast op 16.659 tijdschriftartikelen extraheerde het team ongeveer 6.400 betrouwbare “materiaal–emissie”-paren: de formule van een fosfor, de piekemissiegolflengte, de eenheid en de digitale identificator van het artikel. Zorgvuldige tests toonden een hoge nauwkeurigheid aan, zowel bij het herkennen van volledige fosforformules als bij het koppelen daarvan aan de juiste emissiewaarden. Met deze gestructureerde dataset in handen richtten de onderzoekers zich op één bijzonder belangrijke familie: materialen gedopeerd met europiumionen (Eu2+), die, afhankelijk van het omringende kristal, over een groot deel van het zichtbare spectrum kunnen uitzenden. Ze berekenden fysisch betekenisvolle descriptors voor elke host — zoals kristalstructuurdetails, bindingslengtes en elektronische bandkloof — en gebruikten vervolgens feature-selectiemethoden om deze terug te brengen tot de handvol die het meest van belang zijn voor kleurvoorspelling.
Machine learning de gloed laten voorspellen
Vervolgens trainden en vergeleken de auteurs meerdere machine-learningmodellen om de emissiegolflengte te voorspellen op basis van die descriptors. Een algoritme genaamd XGBoost presteerde het beste en behaalde een verklaarde variantie (R²) van ongeveer 0,91 op niet eerder geziene testgegevens — sterk bewijs dat het model de sleutelrelaties tussen structuur en kleur vastlegt. Om te zien of de aanpak in de praktijk werkt, gebruikte men het model om veelbelovende nieuwe Eu2+-gedopeerde sulfide- en nitride-fosforen voor te stellen, synthetiseerde men vier kandidaten in het laboratorium en mat men hun emissie. De waargenomen golflengten week slechts ongeveer 10 nanometer af van de voorspellingen, wat betekent dat de modelvoorspellingen zeer dicht bij de experimentele werkelijkheid lagen. 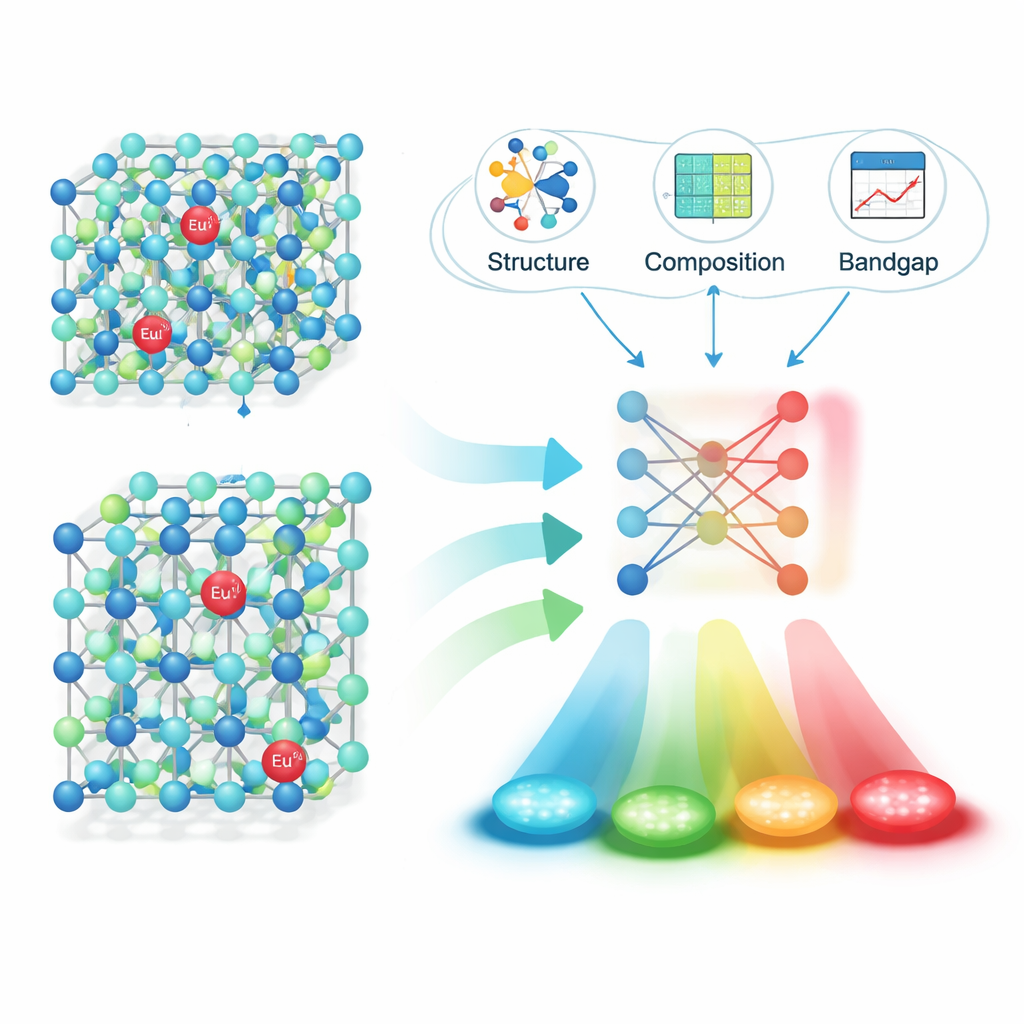
Van artikelen naar praktische ontwerpen
Voor niet‑specialisten is de kernboodschap dat dit werk verspreide, voor mensen geschreven artikelen omzet in een samenhangende, doorzoekbare kaart die “waaruit een materiaal bestaat” koppelt aan “welke kleur het uitstraalt”. Door het lezen, organiseren en leren te automatiseren — en vervolgens voorspellingen door middel van echte experimenten te bevestigen — schetst de studie een gesloten lus: tekst → data → model → nieuw materiaal. Dit kader kan worden uitgebreid naar andere eigenschappen zoals helderheid en stabiliteit, en zelfs naar andere klassen functionele materialen. Daarmee wijst het op een toekomst waarin wetenschappers, in plaats van op trial-and-error laboratoriumwerk, snel kunnen focussen op de meest veelbelovende recepten, wat de ontwikkeling van betere verlichting, schermen en sensortechnologieën versnelt.
Bronvermelding: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Trefwoorden: luminescente materialen, tekstmining, machine learning, fosforen, voorspelling emissiegolflengte